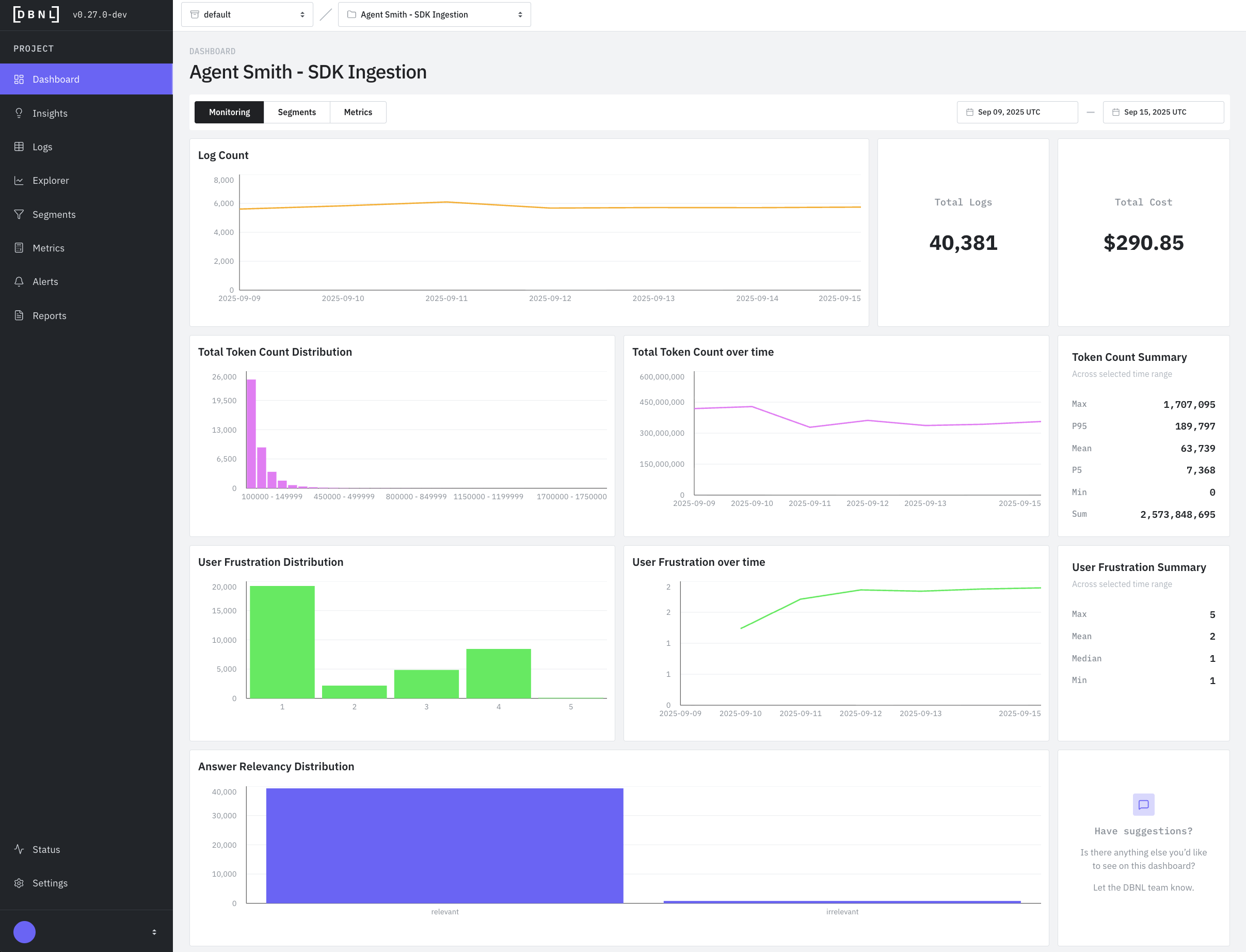
Default dashboard displaying recommended graphs and statistics for a specific time window (default: last 7 days)
Default dashboard displaying recommended graphs and statistics for a specific time window (default: last 7 days)
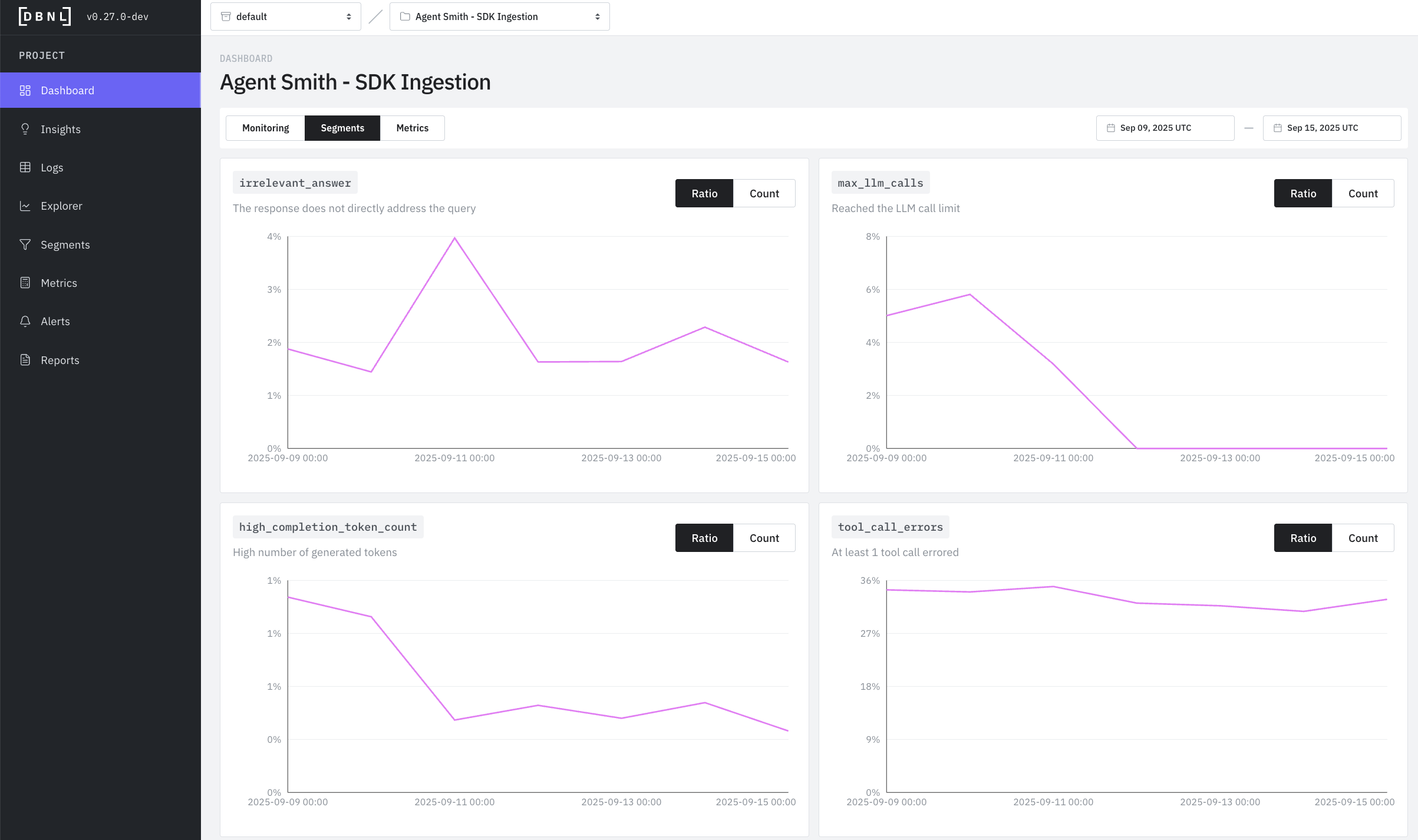
Dashboard displaying all tracked [Segments](segments.md) as time series of daily counts for each [Segment](segments.md) within a specific time range (default: last 7 days)
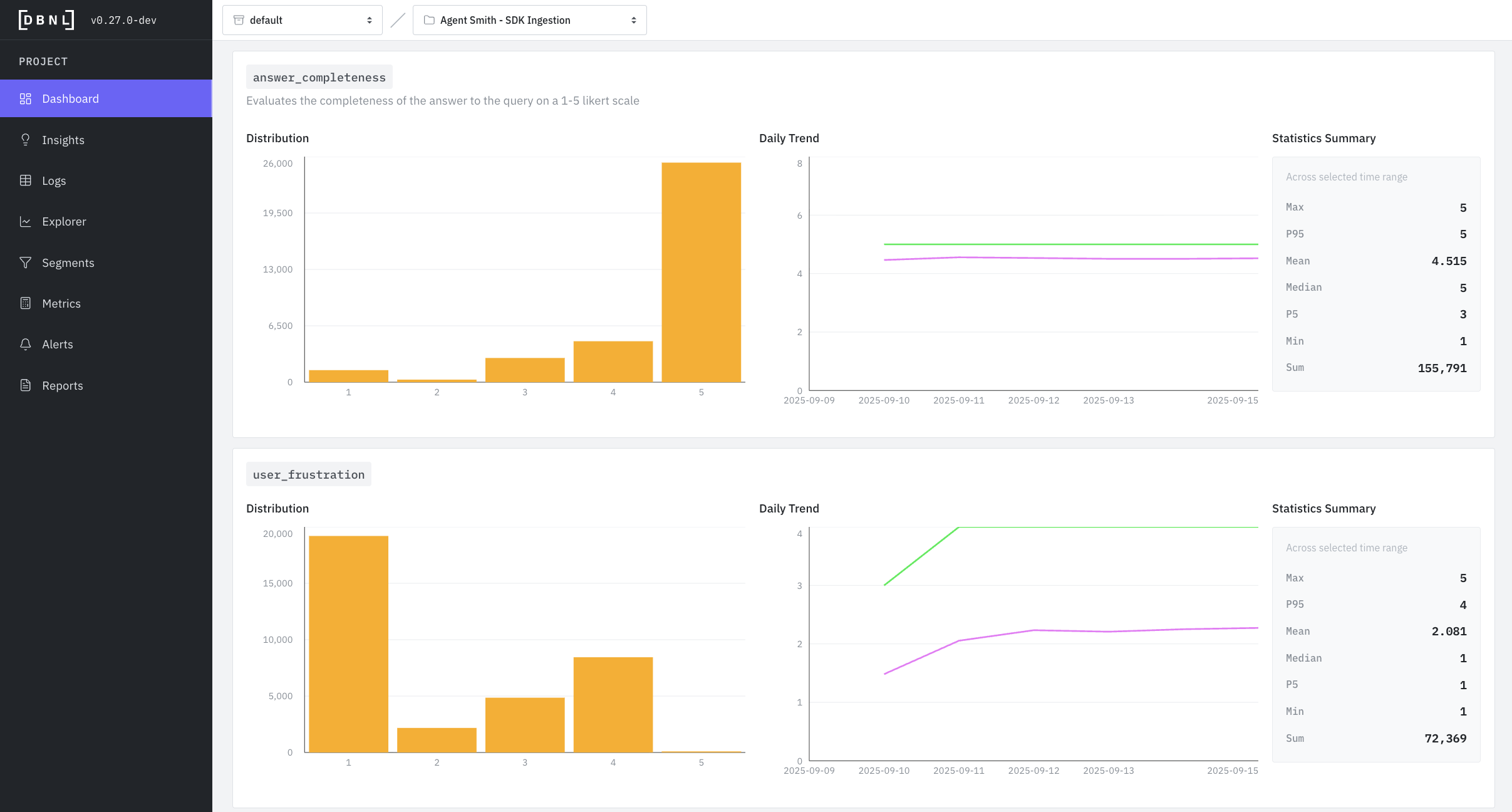
Dashboard displaying all custom [Metrics](metrics.md) as histograms, time series, and statistics summaries for all logs within a specific time range (default: last 7 days)