# What is AI Testing?
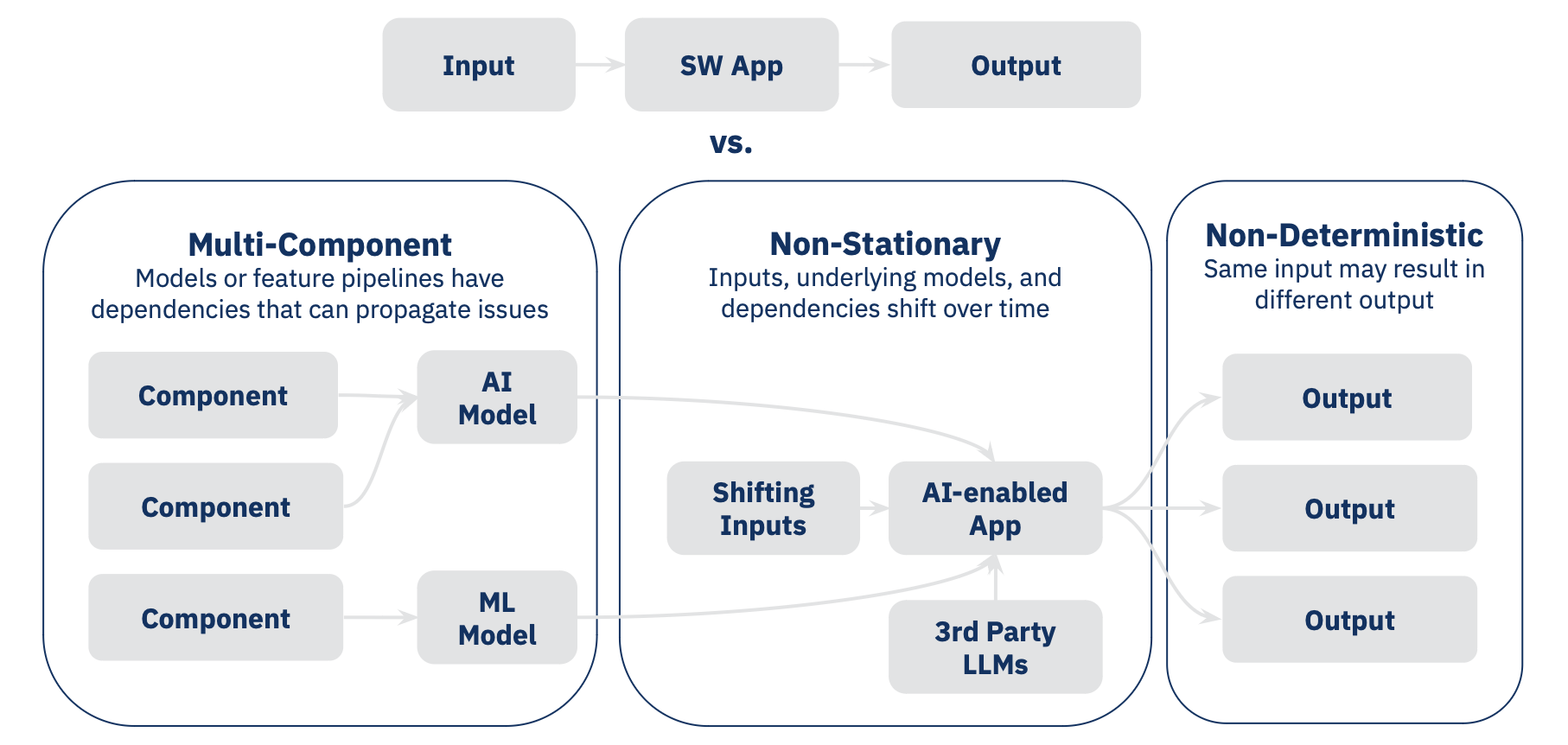
Unlike traditional software applications that follow a straightforward input-to-output path, AI applications present unique testing challenges. A typical AI system combines multiple components like search systems, vector databases, LLM APIs, and machine learning models. These components work together, creating a more complex system than traditional software.
Comparison of traditional software vs. AI workflows
Traditional software testing works by checking if a function produces an expected output given a specific input. For example, a payment processing function should always calculate the same total given the same items and tax rate. However, this approach falls short for AI applications for three key reasons, as illustrated in the diagram:
* First, AI applications are **multi-component systems** where changes in one part can affect others in unexpected ways. For instance, a change in your vector database could affect your LLM's responses, or updates to a feature pipeline could impact your machine learning model's predictions.
* Second, AI applications are **non-stationary, meaning their behavior changes over time even if you don't change the code.** This happens because the world they interact with changes - new data comes in, language patterns evolve, and third-party models get updated. A test that passes today might fail tomorrow, not because of a bug, but because the underlying conditions have shifted.
* Third, AI applications are **non-deterministic. Even with the exact same input, they might produce different outputs each time.** Think of asking an LLM the same question twice - you might get two different, but equally valid, responses. This makes it impossible to write traditional tests that expect exact matches.