Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Getting Access
Get started with dbnl
This guide walks you through using the Distributional SDK to create your first project, submit two runs and create a test session to compare the behavior of your AI application over time.
Congratulations! You ran your first Test Session. You can see the results of the Test Session by navigating to your project in the dbnl app and selecting your test session from the test session table.
By default, a similarity index test is added that tests whether your application has changed between the baseline and experiment run.
Distributional's adaptive testing platform
Distributional is an adaptive testing platform purpose-built for AI applications. It enables you to test AI application data at scale to define, understand, and improve your definition of AI behavior to ensure consistency and stability over time.
Define Desired Behavior Automatically create a behavioral fingerprint from the app’s runtime logs and any existing development metrics, and generate associated tests to detect changes in that behavior over time.
Adaptive testing requires a very different approach than traditional software testing. The goal of adaptive testing is to enable teams to define a steady baseline state for any AI application, and through testing, confirm that it maintains steady state, and where it deviates, figure out what needs to evolve or be fixed to reach steady state once again. This process needs to be discoverable, logged, organized, consistent, integrated and scalable.
Testing AI applications needs to be fundamentally reimagined to include statistical tests on distributions of quantities to detect meaningful shifts that warrant deeper investigation.
Distributions > Summary Statistics: Instead of only looking at summary statistics (e.g. mean, median, P90), we need to analyze distributions of metrics, over time. This accounts for the inherent variability in AI systems while maintaining statistical rigor.
Why is this useful? Imagine you have an application that contains an LLM and you want to make sure that the latency of the LLM remains low and consistent across different types of queries. With a traditional monitoring tool, you might be able to easily monitor P90 and P50 values for latency. P50 represents the latency value below which 50% of the requests fall and will give you a sense of the typical (median) response time that users can expect from the system. However, the P50 value for a normal distribution and bimodal distribution can be the same value, even though the shape of the distribution is meaningfully different. This can hide significant (usage-based or system-based) changes in the application that affect the distribution of the latency scores. If you don’t examine the distribution, these changes go unseen.
Consider a scenario where the distribution of LLM latency started with a normal distribution, but due to changes in a third-party data API that your app uses to inform the response of the LLM, the latency distribution becomes bimodal, though with the same median (and P90 values) as before. What could cause this? Here’s a practical example of how something like this could happen. The engineering team of the data API organization made an optimization to their API which allows them to return faster responses for a specific subset of high value queries, and routes the remainder of the API calls to a different server which has a slower response rate.
The effect that this has on your application is that now half of your users are experiencing an improvement in latency, and now a large number of users are experiencing “too much” latency and there’s an inconsistent performance experience among users. Solutions to this particular example include modifying the prompt, switching the data provider to a different source, format the information that you send to the API differently or a number of other engineering solutions. If you are not concerned about the shift and can accept the new steady state of the application, you can also choose to not make changes and declare a new acceptable baseline for the latency P50 value.
Installing the Python SDK and Accessing Distributional UI
To install the latest stable release of the dbnl package:
To install a specific version (e.g., version 0.22.0):
eval ExtraThe dbnl.eval extra includes additional features and requires an external spaCy model.
To install the required en_core_web_sm pretrained English-language NLP model model for spaCy:
dbnl with the eval ExtraTo install dbnl with evaluation extras:
If you need a specific version with evaluation extras (e.g., version 0.22.0):
We recommend setting your API token as an environment variable, see below.
DBNL has three reserved environment variables that it reads in before execution.
To check your SDK version:
To check your API server version:
Logging into the web app
Clicking the hamburger menu (☰) on the top-left corner
Viewing the version number listed in the footer
Want access to the Distributional platform? . We’ll guide you through the process and ensure you have everything you need to get started.
While we offer SaaS and a for testing purposes, neither are suitable for a production environment. We recommend our option if you plan on deploying the dbnl platform directly in your cloud or on-premise environment.
Create a for your own AI application.
Upload your own data as to your Project.
Define to augment your Runs with novel quantities.
Add more to ensure your application behaves as expected.
Learn more about .
Use to be alerted when tests fail.
For access to the Distributional platform, .
Understand Changes in Behavior Get alerted when there are , understand what is changing, and pinpoint at any level of depth what is causing the change to quickly take appropriate action.
Improve Based on Changes Easily add, remove, or recalibrate over time so you always have a dynamic representation of desired state that you can use to test new models, roll out new upgrades, or accelerate new app development.
Distributional’s platform is designed to easily with your existing infrastructure, including data stores, orchestrators, alerting tools, and AI platforms. If you are already using a model evaluation framework as part of app development, those can be used as an input to further define behavior in Distributional.
Ready to start using Distributional? Head straight to our to get set up on the platform and start testing your AI application.
The dbnl SDK supports . You can install the latest release of the SDK with the following command on Linux or macOS, install a specific release, and install :
You should have already received an invite email from the Distributional team to create your account. If that is not the case, please reach out to your Distributional contact. You can access and/or generate your token at (which will prompt you to login if you are not already).
DBNL has three available deployment types, SaaS, , and .
DBNL_API_TOKEN
The API token used to authenticate your dbnl account.
DBNL_API_URL
The base url of the Distributional API. For SaaS users, set this variable to api.dbnl.com. For other users, please contact your sys admin.
DBNL_APP_URL
An optional base url of the Distributional app. If this variable is not set, the app url is inferred from the DBNL_API_URL variable. For on-prem users, please contact your sys admin if you cannot reach the Distributional UI.
Metrics are measurable properties that help quantify specific characteristics of your data. Metrics can be user-defined, by providing a numeric column computed from your source data alongside your application data.
Alternatively, the Distributional SDK offers a comprehensive set of metrics for evaluating various aspects of text and LLM outputs. Using Distributional's methods for computing metrics will enable better data-exploration and application stability monitoring capabilities.
The SDK provides convenient functions for computing metrics from your data and reporting the results to Distributional:
The SDK includes helper functions for creating common groups of related metrics based on consistent inputs.
The Run is the core object for recording an application's behavior; when you upload a dataset from usage of your app, it takes the shape of a Run. As such, you can think of a Run as the results from a batch of uses or from a standard example set of uses of your application. When exploring or testing your app's behavior, you will look at the Run in dbnl either in isolation or in comparison to another Run.
A Run contains the following:
a table of results where each row holds the data related to a single app usage (e.g. a single input and output along related metadata),
a set of Run-level values, also known as scalars,
structural information about the components of the app and how they relate, and
user-defined metadata for remembering the context of a run.
Your Project will contain many Runs. As you report Runs into your Project, dbnl will build a picture of how your application is behaving, and you will utilize tests to verify that its behavior is appropriate and consistent. Some common usage patterns would be reporting a Run daily for regular checkpoints or reporting a Run each time you deploy a change to your application.
The structure of a Run is defined by its schema. This informs dbnl about what information will be stored in each result (the columns), what Run-level data will be reported (the scalars), and how the application is organized (the components).
The contains more details on Metrics including some example usage.
See the for a more complete list and description of available metrics.
See the for a more complete list and description of available functions.
Generally, you will use our to report Runs. The data associated with each Run is passed to dbnl as pandas dataframes.
A component is a mechanism for grouping columns based on their role within the app. You can also define an index in your schema to tell dbnl a unique identifier for the rows in your Run results. For more information, see the section on the .
Throughout our application and documentation, you'll often encounter the terms "baseline" and "experiment". These concepts are specifically related to running tests in dbnl. The Baseline Run defines the comparison point when running a test; the Experiment Run is the Run which is being tested against that comparison point. For more information, see the sections on and .
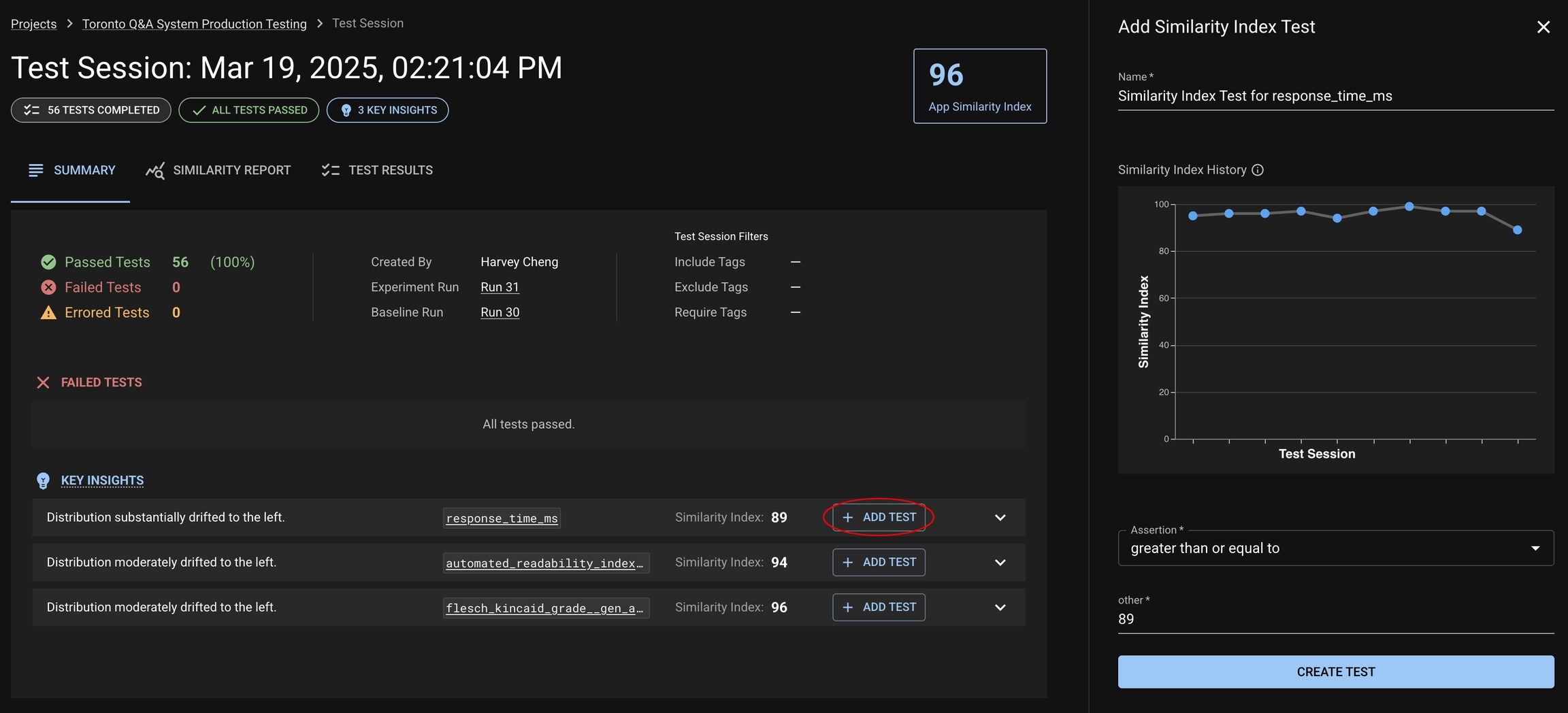
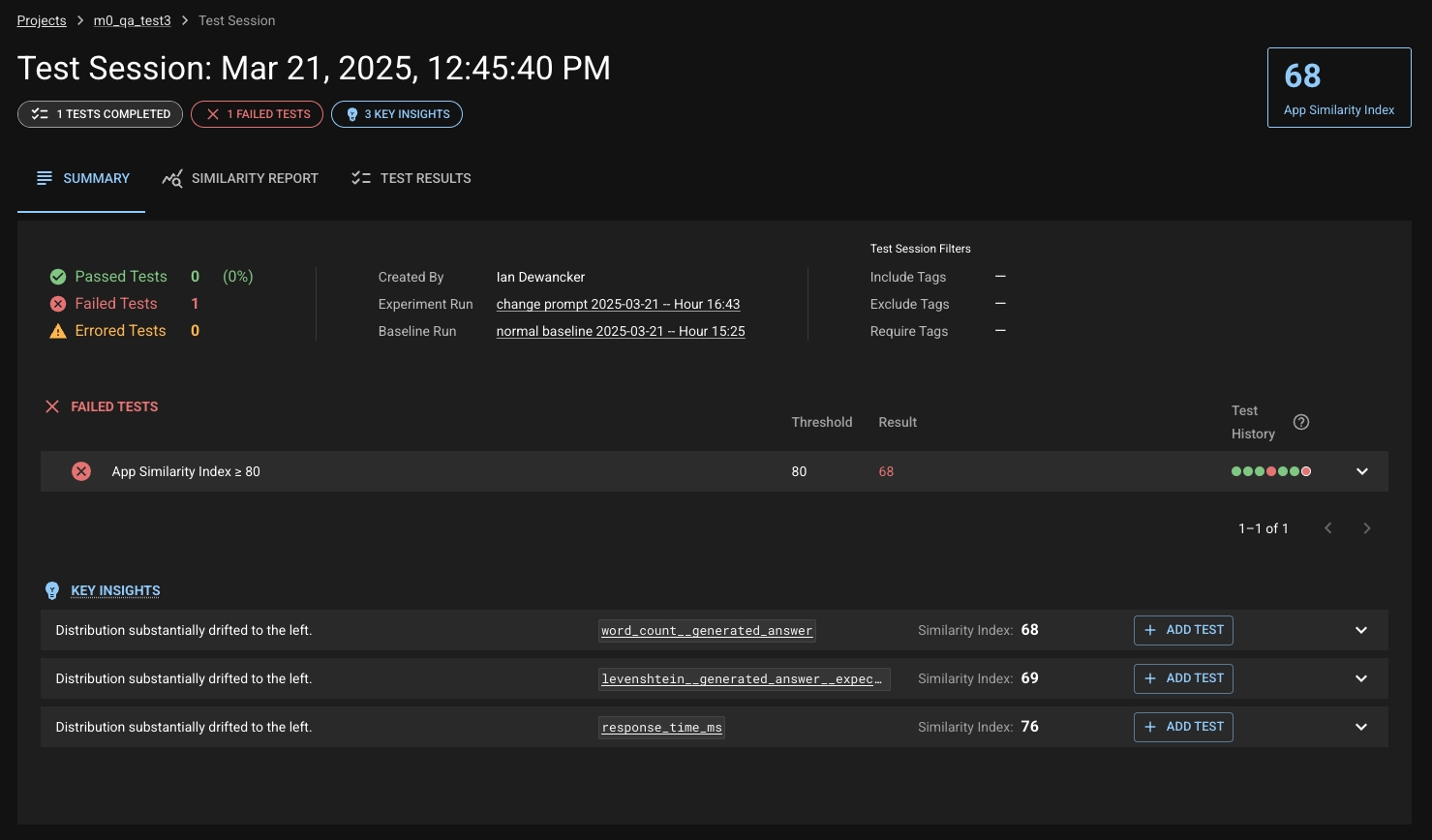
Similarity Index is a single number between 0 and 100 that quantifies how much your application’s behavior has changed between two runs – a Baseline and an Experiment run. It is Distributional’s core signal for measuring application drift, automatically calculated and available in every Test Session.
A lower score indicates a greater behavioral change in your AI application. Each Similarity Index has accompanying Key Insights with a description to help users understand and act on the behavioral drift that Distributional has detected.
Test Session Summary Page — App-level Similarity Index, results of failed tests, and Key Insights
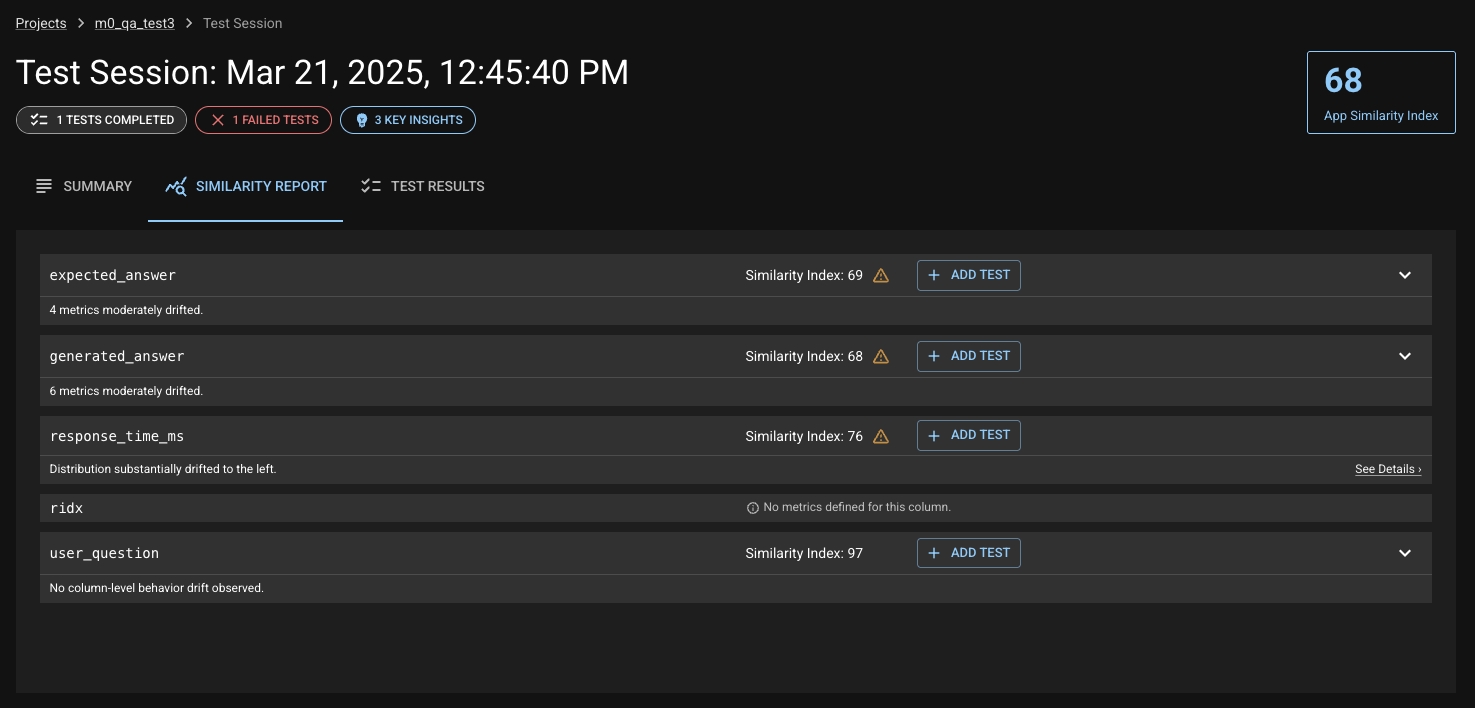
Similarity Report Tab — Breakdown of Similarity Indexes by column and metric
Column Details View — Histograms and statistical comparison for specific metrics
Tests View — History of Similarity Index-based test pass/fail over time
When model behavior changes, you need:
A clear signal that drift occurred
An explanation of what changed
A workflow to debug, test, and act
Similarity Index + Key Insights provides all three.
An app’s Similarity Index drops from 93 → 46
Key Insight: “Answer similarity has decreased sharply”
Metric: levenshtein__generated_answer__expected_answer
Result: Investigate histograms, set test thresholds, adjust model
Similarity Index operates at three levels:
Application Level — Aggregates all lower-level scores
Column Level — Individual column-level drift
Metric Level — Fine-grained metric change (e.g., readability, latency, BLEU score)
Each level rolls up into the one above it. You can sort by Similarity Index to find the most impacted parts of your app.
By default, a new DBNL project comes with an Application-level Similarity Index test:
Threshold: ≥ 80
Failure: Indicates meaningful application behavior change
In the UI:
Passed tests are shown in green
Failed tests are shown in red with diagnostic details
All past test runs can be reviewed in the test history.
Key Insights are human-readable interpretations of Similarity Index changes. They answer:
“What changed, and does it matter?”
Each Key Insight includes:
A plain-language summary: “Distribution substantially drifted to the right”
The associated column/metric
The Similarity Index for that metric
Option to add a test on the spot
Distribution substantially drifted to the right.
→ Metric: levenshtein__generated_answer__expected_answer
→ Similarity Index: 46
→ Add Test
Insights are prioritized and ordered by impact, helping you triage quickly.
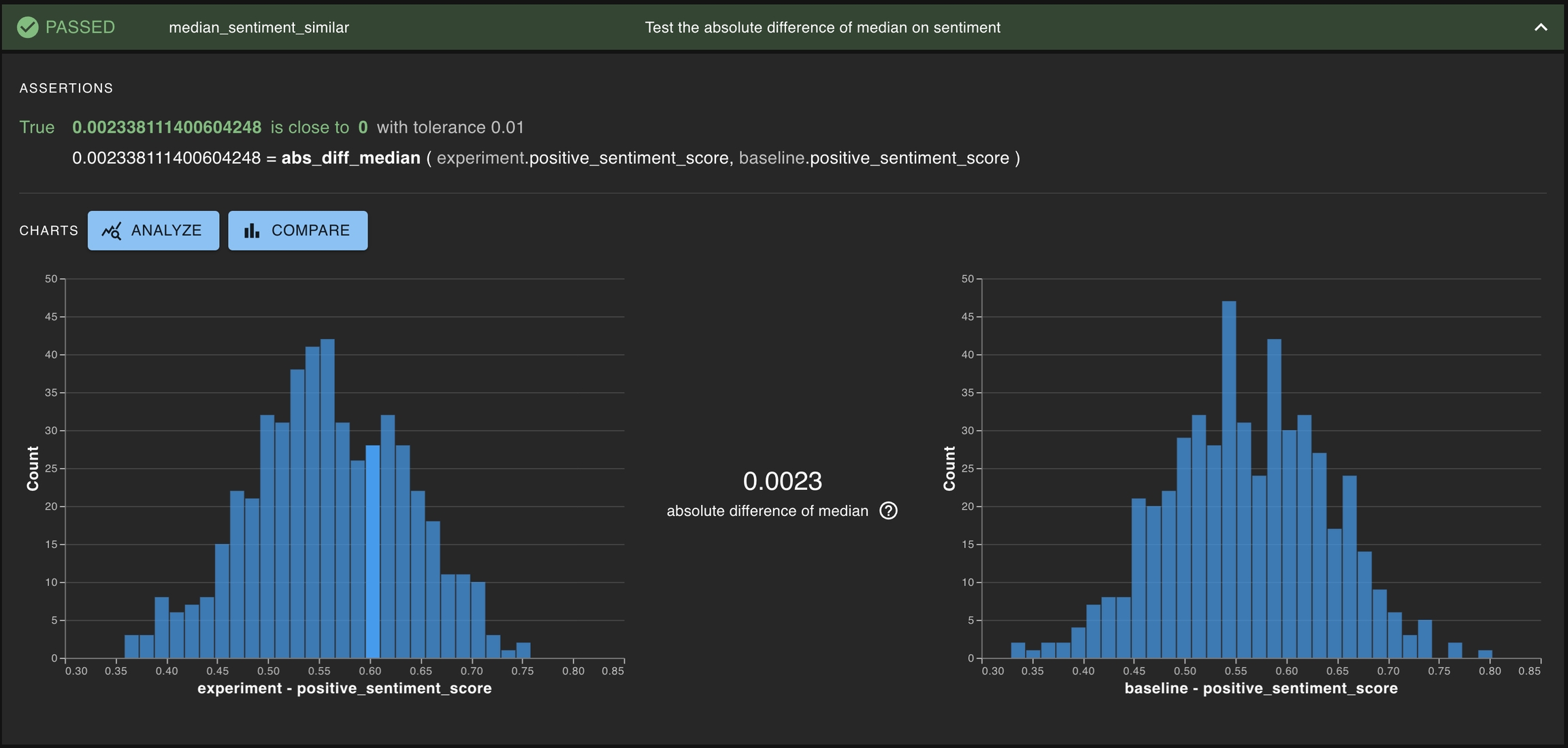
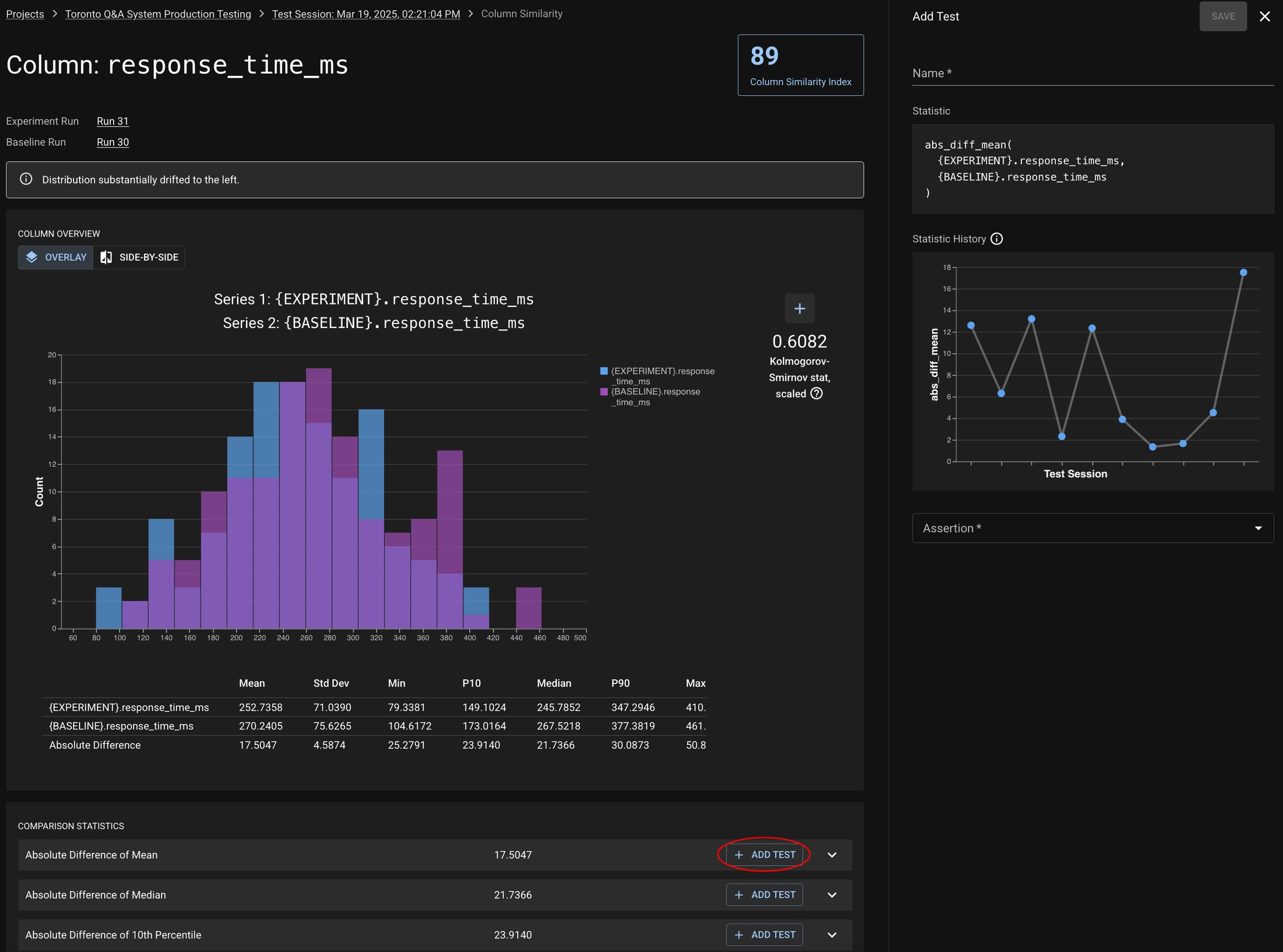
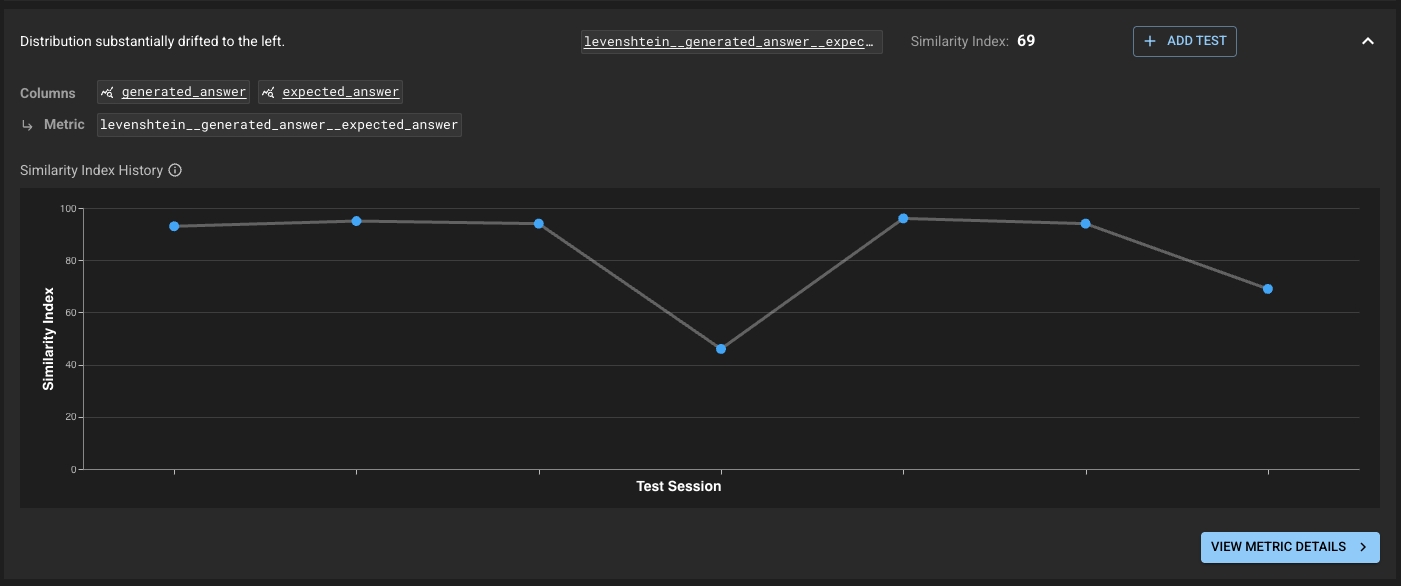
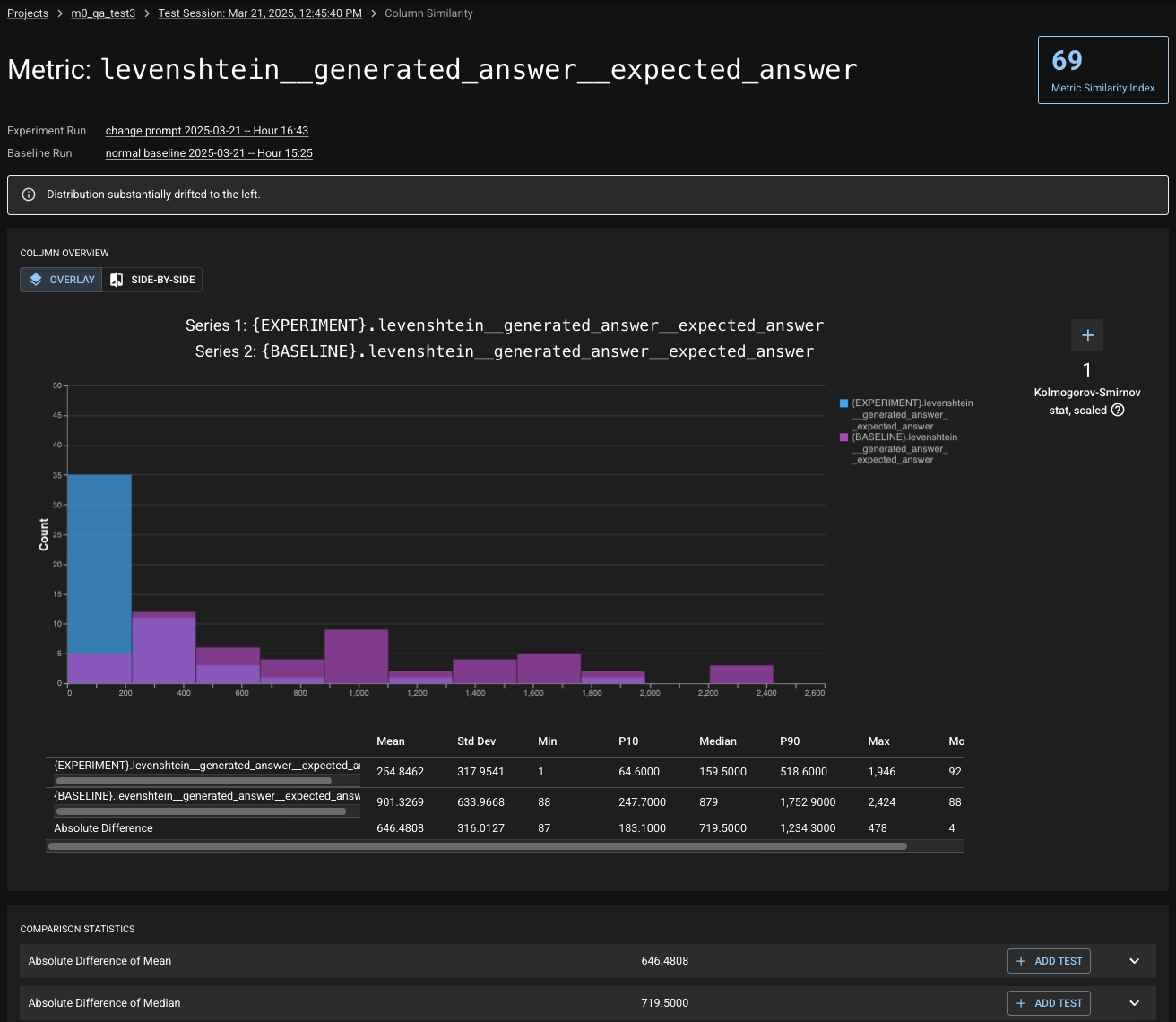
Clicking into a Key Insight opens a detailed view:
Histogram overlays for experiment vs. baseline
Summary statistics (mean, median, percentile, std dev)
Absolute difference of statistics between runs
Links to add similarity or statistical tests on specific metrics
This helps pinpoint whether drift was due to longer answers, slower responses, or changes in generation fidelity.
Run a test session
Similarity Index < 80 → test fails
Review top-level Key Insights
Click into a metric (e.g., levenshtein__generated_answer__expected_answer)
View distribution shift and statistical breakdown
Add targeted test thresholds to monitor ongoing behavior
Adjust model, prompt, or infrastructure as needed
Your data + DBNL testing == insights about your app's behavior
Distributional uses data generated by your AI-powered app to study its behavior and alert you to valuable insights or worrisome trends. The diagram below gives a quick summary of this process:
Each app usage involves input(s), the resulting output(s), and context about that usage
Example: Input is a question from a user; Output is your app’s answer to that question; Context is the time/day that the question was asked.
As the app is used, you record and store the usage in a data store for later review
Example: At 2am every morning, an Airflow job parses all of the previous day’s app usages and sends that info to a data store.
When data is moved to your data store, it is also submitted to DBNL for testing.
Example: The 2am Airflow job is amended to include data augmentation by DBNL Eval and uploading of the resulting Run to trigger automatic app testing.
A Run usually contains many (e.g., dozens or hundreds) rows of inputs + outputs + context, where each row was generated by an app usage. Our insights are statistically derived from the distributions estimated by these rows.
You can read more about the DBNL specific terms . Simply stated, a Run contains all of the data which DBNL will use to test the behavior of your app – insights about your app’s behavior will be derived from this data.
is our library that provides access to common, well-tested GenAI evaluation metrics. You can use DBNL Eval to augment data in your app, such as the inputs and outputs. You are also able to bring your own eval metrics and use them in conjunction with DBNL Eval or standalone. Doing so produces a broader range of tests that can be run, and it allows the platform to produce more powerful insights.
Discover how dbnl manages user permissions through a layered system of organization and namespace roles—like org admin, org reader, namespace admin, writer, and reader.
A user is an individual who can log into a dbnl organization.
Permissions are settings that control access to operations on resources within a dbnl organization. Permissions are made up of two components.
Resource: Defines which resource is being controlled by this permission (e.g. projects, users).
Verb: Defines which operations are being controlled by this permission (e.g. read, write).
For example, the projects.read permission controls access to the read operations on the projects resource. It is required to be able to list and view projects.
A role consists in a set of permissions. Assigning a role to a user gives the user all the permissions associated with the role.
Roles can be assigned at the organization or namespace level. Assigning roles at the namespace level allows for giving users granular access to projects and their related data.
An org role is a role that can be assigned to a user within an organization. Org role permissions apply to resources across all namespaces.
There are two default org roles defined in every organization.
The org admin role has read and write permissions for all org level resources making it possible to perform organization management operations such as creating namespaces and assigning users roles.
The org reader role has read-only permissions to org level resources making it possible to navigate the organization by listing users and namespaces.
To assign a user an org role, go to ☰ > Settings > Admin > Users, scroll to the relevant user and select the an org role from the dropdown in the Org Role column.
A namespace role is a role that can be assigned to a user within a namespace. Namespace role permissions only apply to resources defined within the namespace in which the role is assigned.
There are three default namespace roles defined in every organization.
The namespace admin role has read and write permissions for all namespace level resources within a namespace making it possible to perform namespace management operations such as assigning users roles within a namespace.
The namespace admin role has read and write permissions for all namespace level resources within a namespace except for those resources and operations related to namespace management such as namespace role assignments.
The namespace reader role has read-only permissions for all namespace level resources within a namespace.
This is an experimental role that is available through the API, but is not currently fully supported in the UI.
To assign a user a namespace role within a namespace, go to ☰ > Settings > Admin > Namespaces, scroll and click on the relevant namespace and then click + Add User.

Instructions for self-hosted deployment options
There are two main options to deploy the dbnl platform as a self-hosted deployment:
Helm chart: The dbnl platform can be deployed using a Helm chart to existing infrastructure provisioned by the customer.
Terraform module: The dbnl platform can be deployed using a Terraform module on infrastructure provisioned by the module alongside the platform. This is options is supported on AWS and GCP.
Which option to choose depends on your situation. The Helm chart provides maximum flexibility, allowing users to provision their infrastructure using their own processes, while the Terraform module provides maximum simplicity, reducing the installation to single Terraform command.
Understanding key concepts and their role relative to your app
Adaptive testing for AI applications requires more information than standard deterministic testing. This is because:
AI applications are multi-component systems where changes in one part can affect others in unexpected ways. For instance, a change in your vector database could affect your LLM's responses, or updates to a feature pipeline could impact your machine learning model's predictions.
AI applications are non-stationary, meaning their behavior changes over time even if you don't change the code. This happens because the world they interact with changes - new data comes in, language patterns evolve, and third-party models get updated. A test that passes today might fail tomorrow, not because of a bug, but because the underlying conditions have shifted.
AI applications are non-deterministic. Even with the exact same input, they might produce different outputs each time. Think of asking an LLM the same question twice - you might get two different, but equally valid, responses. This makes it impossible to write traditional tests that expect exact matches.
To account for this, each time you want to measure the behavior of the AI application, you will need to:
Record outcomes at all of the app’s components, and
Push a distribution of inputs through the app to study behavior across the full spectrum of possible app usage.
The inputs, outputs, and outcomes associated with a single app usage are grouped in a Result, with each value in a result described as a Column. The group of results that are used to measure app behavior is called a Run. To determine if an app is behaving as expected, you create a Test, which involves statistical analysis on one or more runs. When you apply your tests to the runs that you want to study, you create a Test Session, which is a permanent record of the behavior of an app at a given time.
Tokens are used for programmatic access to the dbnl platform.
A personal access token is a token that can be used for programmatic access to the dbnl platform through the SDK.
Tokens are not revocable at this time. Please remember to keep your tokens safe.
Token permissions are resolved at use time, not creation time. As such, changing the user permissions after creating a personal access token will change the permissions of the personal access token.
To create a new personal access token, go to ☰ > Personal Access Tokens and click Create Token.
You can create a Project either via the UI or the SDK:
Simply click the "Create Project" button from the Project list view.
You can quickly copy an existing Project to get up and running with a new one. This will copy the following items into your new Project:
Test specifications
Test tags
Notification rules
There are a couple of ways to copy a Project.
Any Project can be exported to a JSON file; that JSON file can then be adjusted to your liking and imported as a new Project. This is doable both via the UI and the SDK:
To export a Project, simply click the download icon on the Project page, in the header.
This will download the Project's JSON to your computer. There is an example JSON in the expandable section below.
Once you have a Project JSON, you can edit it as you'd like, and then import it by clicking the "Create Project" button on the Project list and then clicking the "Import from File" tab.
Fill out the name and description, click "Create Project", and you're all set!
Exporting and importing a Project is done easily via the SDK functions export_project_as_json and import_project_from_json.
You can also just directly copy a given Project. Again, this can be done via the UI or the SDK:
There are two ways to copy a Project from the UI:
In the Project list, after you click "Create Project", you can navigate to the "Copy Existing" tab and choose a Project from the dropdown.
While viewing a Project, you can click the copy icon in the header to copy it to a new Project.
Copying a Project is done easily via the SDK function copy_project.
The full process of reporting a Run ultimately breaks down into three steps:
Creating the Run, which includes defining its structure and any relevant metadata
Reporting the results of the Run, which include columnar data and scalars
Closing the Run to mark it as complete once reporting is finished
The important parts of creating a run are providing identifying information — in the form of a name and metadata — and defining the structure of the data you'll be reporting to it. As mentioned in the previous section, this structure is called the Run Schema.
A Run schema defines four aspects of the Run's structure:
Columns (the data each row in your results will contain)
Scalars (any Run-level data you want to report)
Index (which column or columns uniquely identify rows in your results)
Components (functional groups to organize the reported results in the form of a graph)
Columns are the only required part of a schema and are core to reporting Runs, as they define the shape your results will take. You report your column schema as a list of objects, which contain the following fields:
name: The name of the column
description: A descriptive blurb about what the column is
component: Which part of your application the column belongs to (see Components below)
Using the index field within the schema, you have the ability to designate Unique Identifiers – specific columns which uniquely identify matching results between Runs. Adding this information facilitates more direct comparisons when testing your application's behavior and makes it easier to explore your data.
Once you've defined the structure of your run, you can upload data to dbnl to report the results of that run. As mentioned above, there are two kinds of results from your run:
The row-level column results (these each represent the data of a single "usage" of your application)
The Run-level scalar results (these represent data that apply to all usages in your Run as a whole)
dbnl expects you to upload your results data in the form of a pandas DataFrame. Note that scalars can be uploaded as a single-row DataFrame or as a dictionary of values.
Now that you understand each step, you can easily integrate all of this into your codebase with a few simple function calls via our SDK:
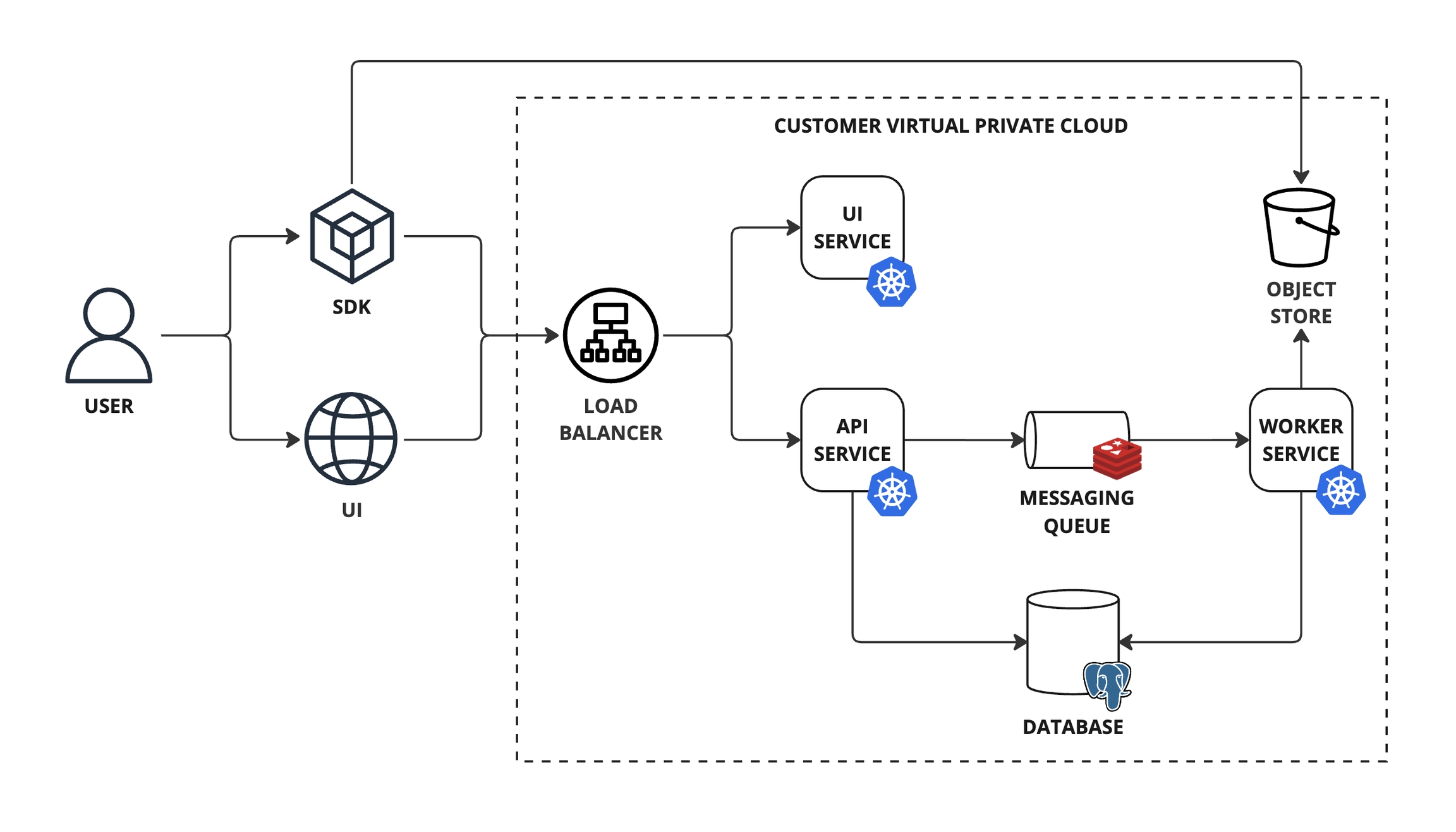
An overview of the architecture for the dbnl platform
The dbnl platform architecture consists of a set of services packaged as Docker images and a set of standard infrastructure components.
The dbnl platform requires the following infrastructure:
A Kubernetes cluster to host the dbnl platform services.
A PostgreSQL database to store metadata.
An object store bucket to store raw data.
A Redis database to serve as a messaging queue.
A load balancer to route traffic to the API or UI service.
The dbnl platform consists in three core services:
The API service (api-srv) serves the dbnl API and orchestrates work across the dbnl platform.
The worker service (worker-srv) processes async jobs scheduled by the API service.
The UI service (ui-srv) serves the dbnl UI assets.
A personal access token has the same permissions as the user that created it. See for more details about permissions.
Personal access tokens are implemented using and are not persisted. Tokens cannot be recovered if lost and a new token will need to be created.
The "Baseline Run" is a core concept in dbnl that, appropriately, refers to the Run used as a baseline when executing a Test Session. Conversely, the Run being tested is called the "Experiment Run". Any that compare statistics will test the values in the experiment relative to the baseline.
Depending on your use case, you may want to make your Baseline Run dynamic. You can use a Run Query for this. Currently, dbnl supports setting a Run Query that looks back a number of previous runs. For example, in a production testing use case, you may want to use the previous Run as the baseline for each Test Session, so you'd create a Run Query that looks back 1 run. See the UI example in the section for information on how to create a Run Query. You can also create a Run Query .
You can choose a Baseline Run at the time of Test Session creation. If you do not provide one, dbnl will use your Project's default Baseline Run. See for more information.
From your Project, click the "Test Configuration" tab. Choose a Run or Run Query from the Baseline Run dropdown.
You can set a Run as baseline via the set_run_as_baseline or set_run_query_as_baseline functions.
Projects are the main organizational tool in dbnl. Each Project lives within a in your and is accessible by everyone in that Namespace. Generally, you'll create one Project for every AI application that you'd like to test with dbnl. The list of Projects available to you is the default landing page when browsing to the dbnl UI.
Your Project will contain all of your app's — a collection of results from your app — and all of the that you've defined to monitor the behavior of your app. It also has a name and various configurable properties like a and .
Creating a project with the SDK can be done easily with the function.
Each of these steps can be done separately via our , but it can also be done conveniently with a single SDK function call: dbnl.report_run_with_results, which is recommended. See below.
We also have an eval library available that lets you generate useful metrics on your columns and report them to dbnl alongside the Run results. Check out for more information.
In older versions of dbnl, the job of the schema was done by something called the "Run Config". The Run Config has been fully deprecated, and you should check the and update any code you have.
type: The type of the column, e.g. int. For a list of available types, see
Scalars represent any data that live at the Run level; that is, the represent single data points that apply to your entire Run. For example, you may want to calculate an for the entirety of a result set for your model. The scalar schema is also a list of objects, and takes on the same fields as the column schema above.
Components are defined within the components_dag field of the schema. This defines the topological structure of your app as a . Using this, you can tell dbnl which part of your application different columns correspond to, enabling a more granular understanding of your app's behavior.
You can learn more about creating a Run schema in the SDK reference for . There is also a , but we recommend the method shown in the .
Check out the section on to see how dbnl can supplement your results with more useful data.
There are functions to upload and in the SDK, but, again, we recommend the method in the !
Once you're finished uploading results to dbnl for your Run, the run should be closed, to mark it as ready to be used in Test Sessions. Note that reporting results to a Run will overwrite any existing results, and, once closed, the Run can no longer have results uploaded. If you need to close a Run, there is an for it, or you can close an open Run from its page on the UI.
Tests are the key tool within dbnl for asserting the behavior and consistency of Runs. Possible goals during testing can include:
Asserting that your application, holistically or for a chosen column, behaves consistently compared to a baseline.
Asserting that a chosen column meets its minimum desired behavior (e.g., inference throughput);
Asserting that a chosen column has a distribution that roughly matches a baseline reference;
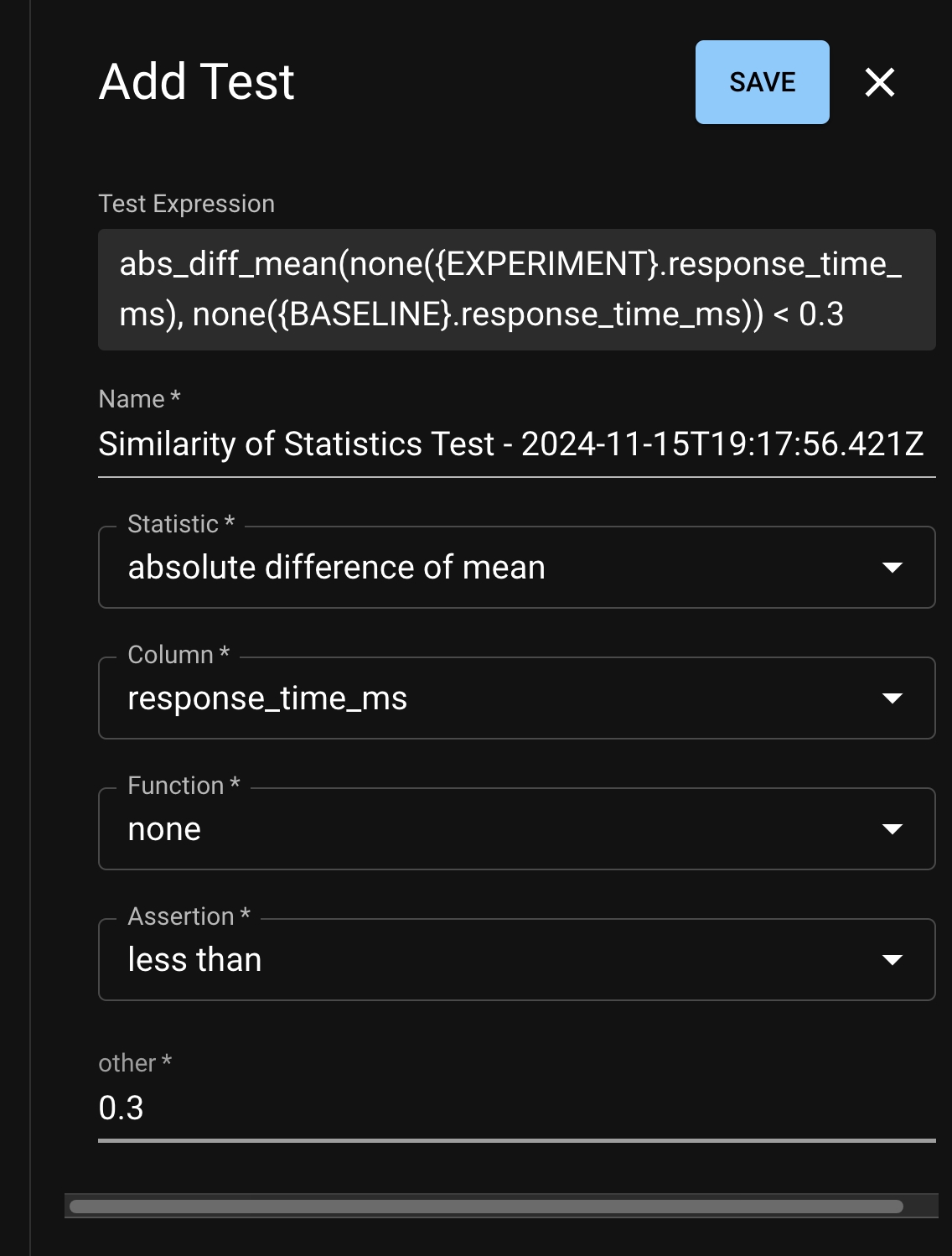
At a high level, a Test is a statistic and an assertion. Generally, the statistic aggregates the data in a column or columns, and the assertion tests some truth about that aggregation. This assertion may check the values from a single Run, or it may check how the values in a Run have changed compared to a baseline. Some basic examples:
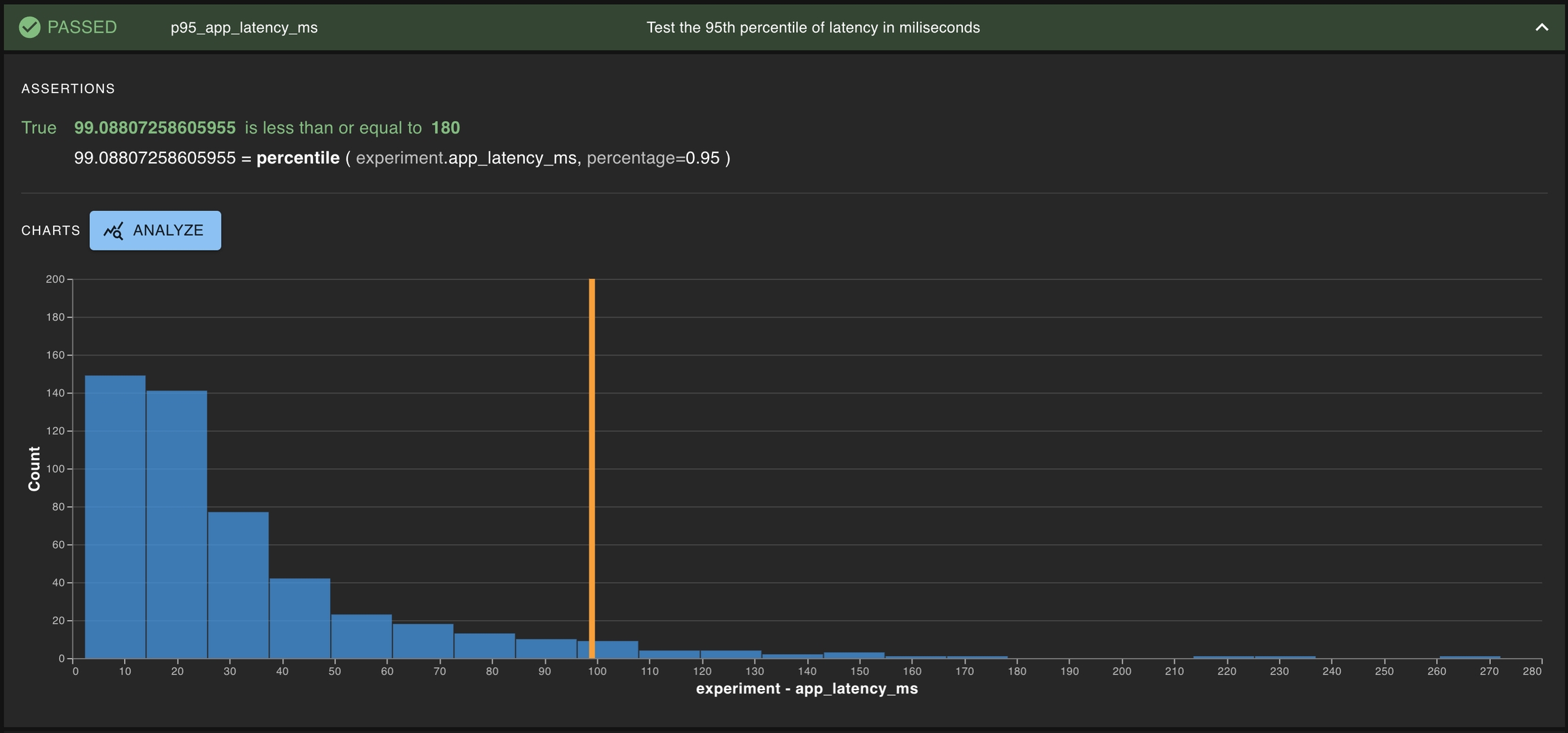
Assert the 95th percentile of app_latency_ms is less than or equal to 180
Assert the absolute difference of median of positive_sentiment_score against the baseline is close to 0
In the next sections, we will explore the objects required for testing alongside the methods for creating tests, running tests, reviewing/analyzing tests, and some best practices.
Terraform module installation instructions
The Terraform module option provides maximum simplicity. It provisions all the required infrastructure and permissions in your cloud provider of choice before deploying the dbnl platform Helm chart, removing the need to provision any infrastructure or permission separately.
The following prerequisite steps are required before starting the Terraform module installation.
To configure the Terraform module, you will need:
A domain name to host the dbnl platform (e.g. dbnl.example.com).
An RSA key pair can be generated with:
On the environment from which you are planning to install the module, you will need to:
At a minimum, the user performing the installation needs to be able to provision the following infrastructure:
Soon.
The steps to install the Terraform module using the Terraform CLI are as follows:
Create a dbnl folder and change to it.
Create a modules folder and copy the terraform module to it.
Create a variables.tf file.
Create a main.tf file.
Create a dbnl.tfvars file.
Initialize the Terraform module.
Apply the Terraform module.
Soon.
For more details on all the installation options, see the Terraform module README file and examples folder.
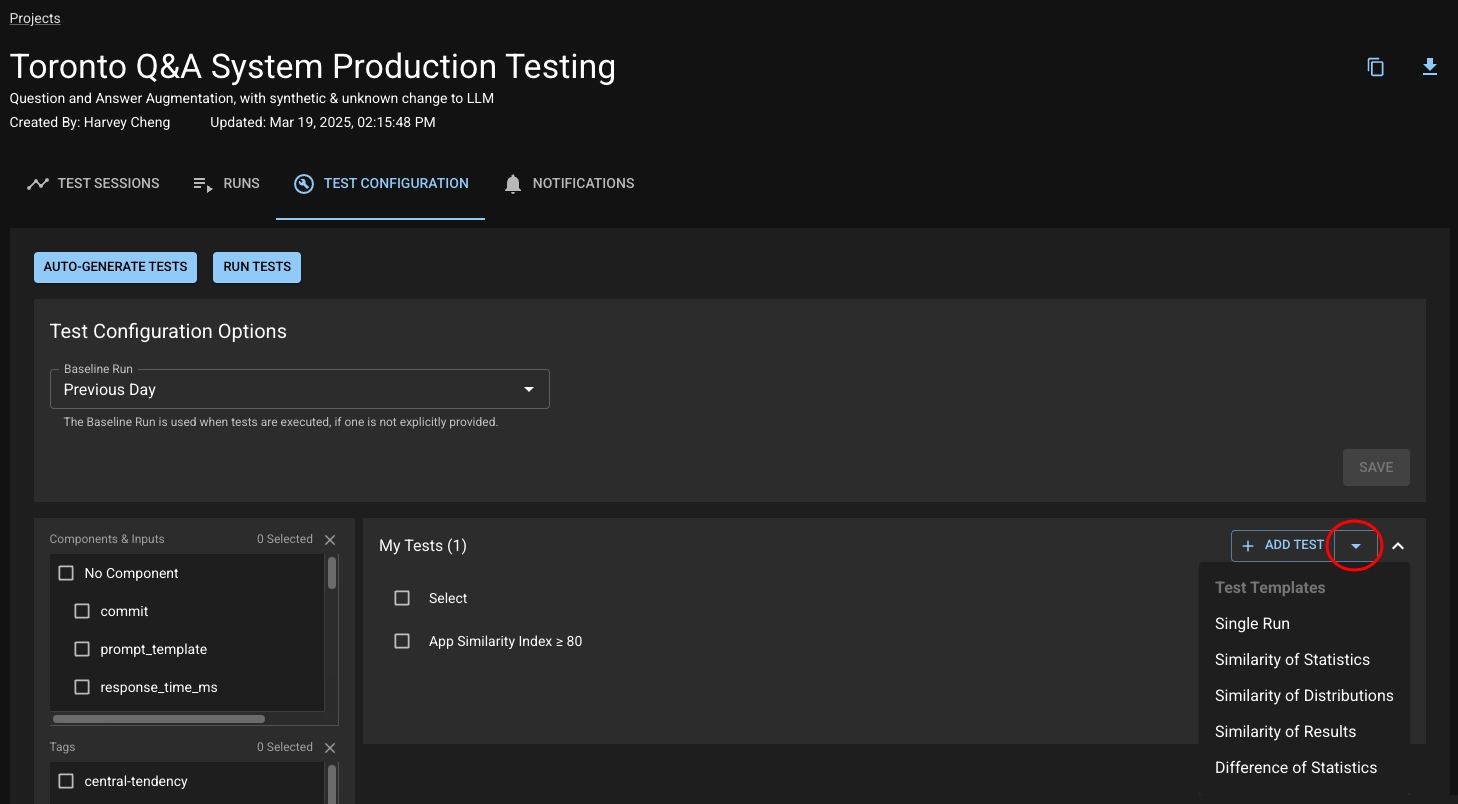
As you become more familiar with the behavior of your application, you may want to build on the default App Similarity Index test with tests that you define yourself. Let's walk through that process.
As you browse the dbnl UI, you will see "+" icons or "+ Add Test" buttons appear. These provide context-aware shortcuts for easily creating relevant tests.
At each of these locations, a test creation drawer will open on the right side of the page with several of the fields pre-populated based on the context of the button, alongside a history of the statistic, if relevant. Here are some of the best places to look for dbnl-assisted test creation:
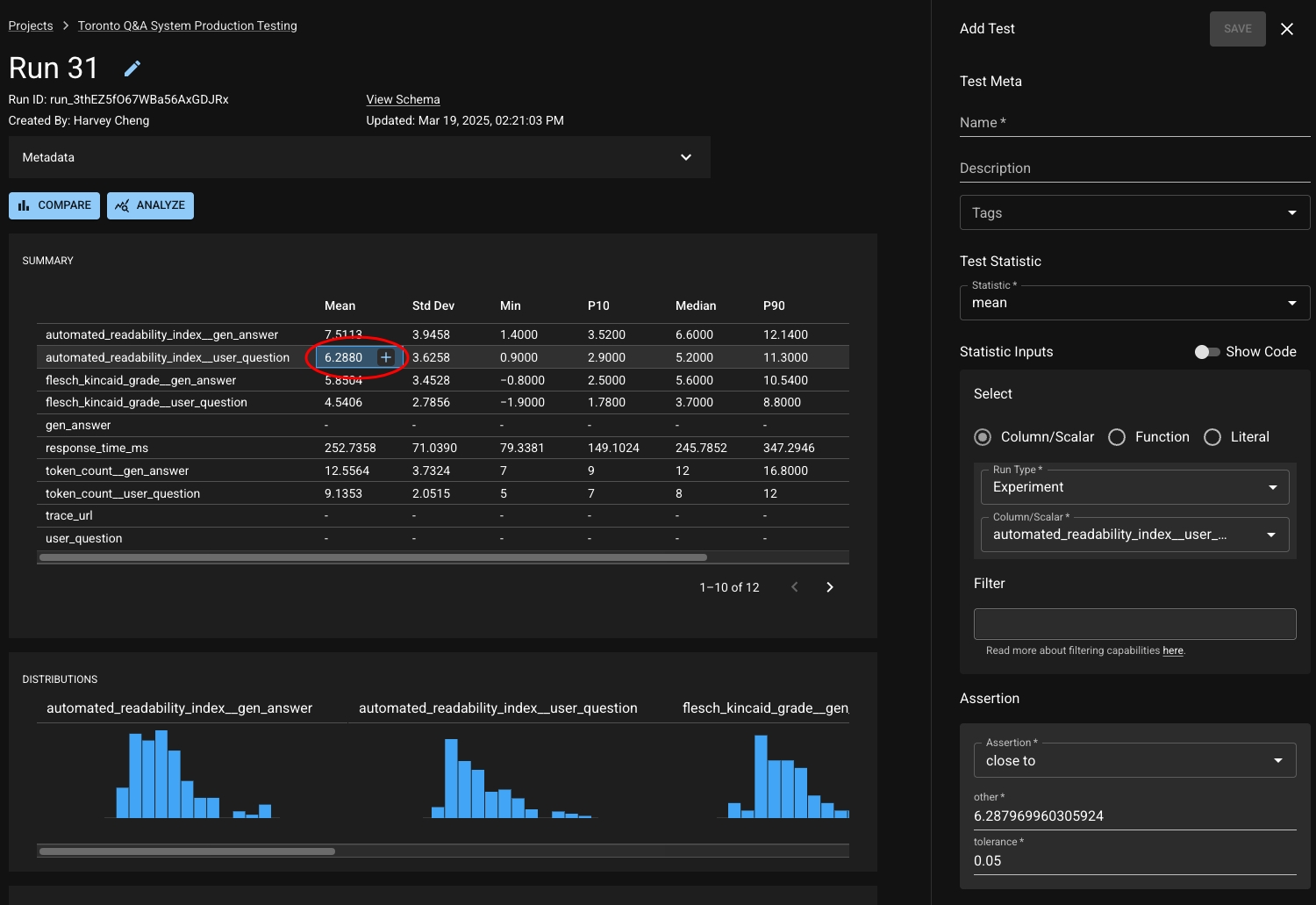
When inspecting the details of a column or metric from a Test Session, there are several "Add Test" buttons provided to allow you to quickly create a test on a relevant statistic. The Statistic History graph can help guide you on choosing a threshold.
When viewing a Run, each entry in the summary statistics table can be used to seed creation of a test for that chosen statistic.
These shortcuts appear in several other places in the UI as well when you are inspecting your Runs and Test Sessions; keep an eye out for the "+"!
Test templates are macros for basic test patterns recommended by Distributional. It allows the user to quickly create tests from a builder in the UI. Distributional provides five classes of test templates:
From the Test Configuration tab on your Project, click the dropdown next to "Add Test".
Select from one of the five options. A Test Creation drawer will appear and the user can edit the statistic, column, and assertion that they desire. Note that each Test Template has a limited set of statistics that it supports.
If you have a good idea of what you want to test or just want to explore, you can create tests manually from either the UI or via the Python SDK.
Let's say you are building an Q&A chatbot, and you have a column for the length of your bot's responses, word_count. Perhaps you want to ensure that your bot never outputs more than 100 words; in that case, you'd choose:
The statistic max,
The assertion less than or equal to ,
and the threshold 100.
But what if you're not opinionated about the specific length? You just want to ensure that your app is behaving consistently as it runs and doesn't suddenly start being unusually wordy or terse. dbnl makes it easy to test that as well; you might go with:
The statistic absolute difference of mean,
The assertion less than,
and the threshold 20.
Now you're ready to go and create that test, either via the UI or the SDK:
From your Project, click the "Test Configuration" tab.
Next to the "My Tests" header, you can click "Add Test" to open the test creation page, which will enable you to define your test through the dropdown menu on the left side of the window.
By default, your Project will be pre-populated with a test for the first goal above. This is the "App " test which gives you a quick understanding of whether your application's behavior has significantly deviated from a selected baseline.
Terraform modules are available for AWS and GCP. For access to the Terraform module for your cloud provider of choice and to get registry credentials, .
A set of dbnl registry credentials to pull the (e.g. Docker images, Helm charts).
An RSA key pair to sign the .
Install
Install
Install
(IAM)
(VPC)
(EKS)
(ACM)
(ALB)
The Terraform module can be installed using . We recommend using a to manage the Terraform state.
The dbnl platform uses or OIDC for authentication. OIDC providers that are known to work with dbnl include:
Follow the to create a new SPA (single page application).
In Settings > Application URIs, add the dbnl deployment domain to the list of Allowed Callback URLs (e.g. dbnl.mydomain.com).
Navigate to Settings > Basic Information and copy the Client ID as the OIDC clientId option.
Navigate to Settings > Basic Information and copy the Domain and prepend with https:// to use as the OIDC issuer option (e.g. https://my-app.us.auth0.com/).
Follow the to create a custom API.
Use your dbnl deployment domain as the Identifier (e.g. dbnl.mydomain.com).
Navigate to Settings > General Settings and copy the Identifier as the OIDC audience option.
Set the OIDC scopes option to "openid profile email".
Follow the to create a new SPA (single page application) and enable OIDC.
Add the dbnl deployment domain as the callback URL (e.g. dbnl.mydomain.com).
[Optional] Follow the to restrict access to certain users.
Navigate to App Registrations > (Application) > Manage > API permissions and add the Microsoft Graph email, openid and profile permissions to the application.
Navigate to App Registrations > (Application) > Manage > Manifest and set access token version to 2.0 with "accessTokenAcceptedVersion": 2 .
Navigate to App Registrations > (Application) > Manage > Token configuration > Add optional claim > Access > email to add the email optional claim to the access token type.
Navigate to App Registrations > (Application) and copy the Application (client) ID (APP_ID) to be used as the OIDC clientId and OIDC audience options.
Set the OIDC issuer option to https://login.microsoftonline.com/{APP_ID}/v2.0 .
Set the OIDC scopes option to "openid email profile {APP_ID}/.default".
Set the Sign-in redirect URIs to your dbnl domain (e.g. dbnl.mydomain.com)
Navigate to General > Client Credentials and copy the Client ID to be used as the OIDC clientId option.
Navigate to Sign on > OpenID Connect ID Token and copy the Issuer URL to be used as the OIDC issuer and OIDC audience options.
Set the OIDC scopes option to "openid email profile" .
The first step in coming up with a test is determining what behavior you're interested in. As described in , each Run of your application reports its behavior via its results, which are organized into columns (and scalars). Once you've identified the column or scalar you'd like to test on, then you need to determine what you'd like to apply to it and the you'd like to make on that statistic.
This might seem like a lot, but dbnl has your back! While you can define tests , dbnl has several ways of helping you identify what columns you might be interested in and letting you quickly define tests on them.
When creating a test, you can specify tags to apply to it. You can use these tags to filter which tests you want to include or exclude later when . Some of the test creation shortcuts on the UI do not currently allow specifying tests, but you can edit the test and add tags after the fact.
When you're looking at a Test Session, dbnl will provide insights about which columns or metrics have have demonstrated the most drift. These are great candidates to define tests on if you want to be specificially alerted about their behavior. You can click the "Add Test" button to create a test on the of the relevant column. The Similarity Index history graph can help guide you on choosing a threshold.
: These are parametric statistics of a column.
: These test if the absolute difference of a statistic of a column between two runs is less than a threshold.
: These test if the column from two different runs are similarly distributed is using a nonparametric statistic.
: These are tests on the row-wise absolute difference of result
: These tests the signed difference of a statistic of a column between two runs
When creating a test manually, you can also specify filters to apply the test only to specific rows within your Runs. Check out for more information.
On the left side you can configure your test by choosing a statistic and assertion. Note that you can use our builder or build a test spec with raw JSON (you can see some example test spec JSONs ). On the right, you can browse the data of recent Runs to help you figure out what statistics and thresholds are appropriate to define acceptable behavior.
Tests can be using the python SDK. Users must provide a JSON dictionary that adheres to the dbnl Test Spec, which is described in the previous link and has an example provided below.
You can see a full list with descriptions of available statistics and assertions .
Follow the to create a new SPA (single page application) and enable OIDC.
List of networking requirements
The dbnl platform needs to be hosted on a domain or subdomain (e.g. dbnl-example.com or dbnl.example.com). It cannot be hosted on a subpath.
It is recommended that the dbnl platform be served over HTTPS. Support for SSL termination at the load balancer is included.
Currently, the dbnl platform cannot run in an air-gapped environment and requires a few URLs to be accessible via egress.
Artifacts Registry
Required to fetch the dbnl paltform artifacts such as the Helm chart and Docker images.
https://us-docker.pkg.dev/dbnlai/
Object Store
Required for services to access the object store.
https://{BUCKET}.s3.amazonaws.com/ (if using S3)
https://storage.googleapis.com/{BUCKET} (if using GCS)
OIDC
Required to validate OIDC tokens.
https://login.microsoftonline.com/{APP_ID}/v2.0/ (if using Microsoft EntraID)
https://{ACCOUNT}.okta.com/ (if using Okta)
Integrations
Required to use some integrations.
https://events.pagerduty.com/v2/enqueue (if using PagerDuty)
https://hooks.slack.com/services/ (if using Slack)
Returns the absolute value of the input.
Syntax
Adds the two inputs.
Syntax
Logical and operation of two or more boolean columns.
Syntax
Returns the ARI (Automated Readability Index) which outputs a number that approximates the grade level needed to comprehend the text. For example if the ARI is 6.5, then the grade level to comprehend the text is 6th to 7th grade.
Syntax
Computes the BLEU score between two columns.
Syntax
Returns the number of characters in a text column.
Syntax
Aliases
num_chars
Divides the two inputs.
Syntax
Computes the element-wise equal to comparison of two columns.
Syntax
Aliases
eq
Filters a column using another column as a mask.
Syntax
Returns the Flesch-Kincaid Grade of the given text. This is a grade formula in that a score of 9.3 means that a ninth grader would be able to read the document.
Syntax
Computes the element-wise greater than comparison of two columns. input1 > input2
Syntax
Aliases
gt
Computes the element-wise greater than or equal to comparison of two columns. input1 >= input2
Syntax
Aliases
gte
Returns true if the input string is valid json.
Syntax
Computes the element-wise less than comparison of two columns. input1 < input2
Syntax
Aliases
lt
Computes the element-wise less than or equal to comparison of two columns. input1 <= input2
Syntax
Aliases
lte
Returns Damerau-Levenshtein distance between two strings.
Syntax
Returns True if the list has duplicated items.
Syntax
Returns the length of lists in a list column.
Syntax
Most common item in list.
Syntax
Multiplies the two inputs.
Syntax
Returns the negation of the input.
Syntax
Logical not operation of a boolean column.
Syntax
Computes the element-wise not equal to comparison of two columns.
Syntax
Aliases
neq
Logical or operation of two or more boolean columns.
Syntax
Returns the rouge1 score between two columns.
Syntax
Returns the rouge2 score between two columns.
Syntax
Returns the rougeL score between two columns.
Syntax
Returns the rougeLsum score between two columns.
Syntax
Returns the number of sentences in a text column.
Syntax
Aliases
num_sentences
Subtracts the two inputs.
Syntax
Returns the number of tokens in a text column.
Syntax
Returns the number of words in a text column.
Syntax
Aliases
num_words
Instructions for managing a dbnl Sandbox deployment.
The dbnl sandbox deployment bundles all of the dbnl services and dependencies into a single self-contained Docker container. This container replicates a full scale dbnl deployment by creating a Kubernetes cluster in the container and using Helm to deploy the dbnl platform and its dependencies (postgresql, redis and minio).
The sandbox deployment is not suitable for production environments.
The sandbox container needs access to the following two registries to pull the containers for the dbnl platform and its dependencies.
us-docker.pkg.dev
docker.io
The sandbox container needs sufficient memory and disk space to schedule the k3d cluster and the containers for the dbnl platform and its dependencies.
Although the sandbox image can be deployed manually using Docker, we recommend using the dbnl CLI to manage the sandbox container. For more details on the sandbox CLI options, run:
To start the dbnl Sandbox, run:
This will start the sandbox in a Docker container named dbnl-sandbox. It will also create a Docker volume of the same name to persist data beyond the lifetime of the sandbox container.
To stop the dbnl sandbox, run:
This will stop and remove the sandbox container. It does not remove the Docker volume and the next time the sandbox is started, it will remount the existing volume, persisting the data beyond the lifetime of the Sandbox container.
To get the status of the dbnl sandbox, run:
To tail the dbnl sandbox logs, run:
To execute a command in the dbnl sandbox, run:
This will execute COMMAND within the dbnl sandbox container. This is a useful tool for debugging the state of the containers running within the sandbox containers. For example:
To get a list of all Kubernetes resources, run:
To get the logs for a particular pod, run:
This is an irreversible action. All the sandbox data will be lost forever.
To delete the sandbox data, run:
The sandbox deployment uses username and password authentication with a single user. The user credentials are:
Username: admin
Password: password
The sandbox persists data in a Docker volume named dbnl-sandbox. This volume is persisted even if the sandbox is stopped, making it possible to later resume the sandbox without losing data.
If deploying and hosting the sandbox on a remote host, such as on EC2 or Compute Engine, the sandbox --base-url option needs to be set on start.
For example, if hosting the sandbox on http://example.com:8080, the sandbox needs to be started with:
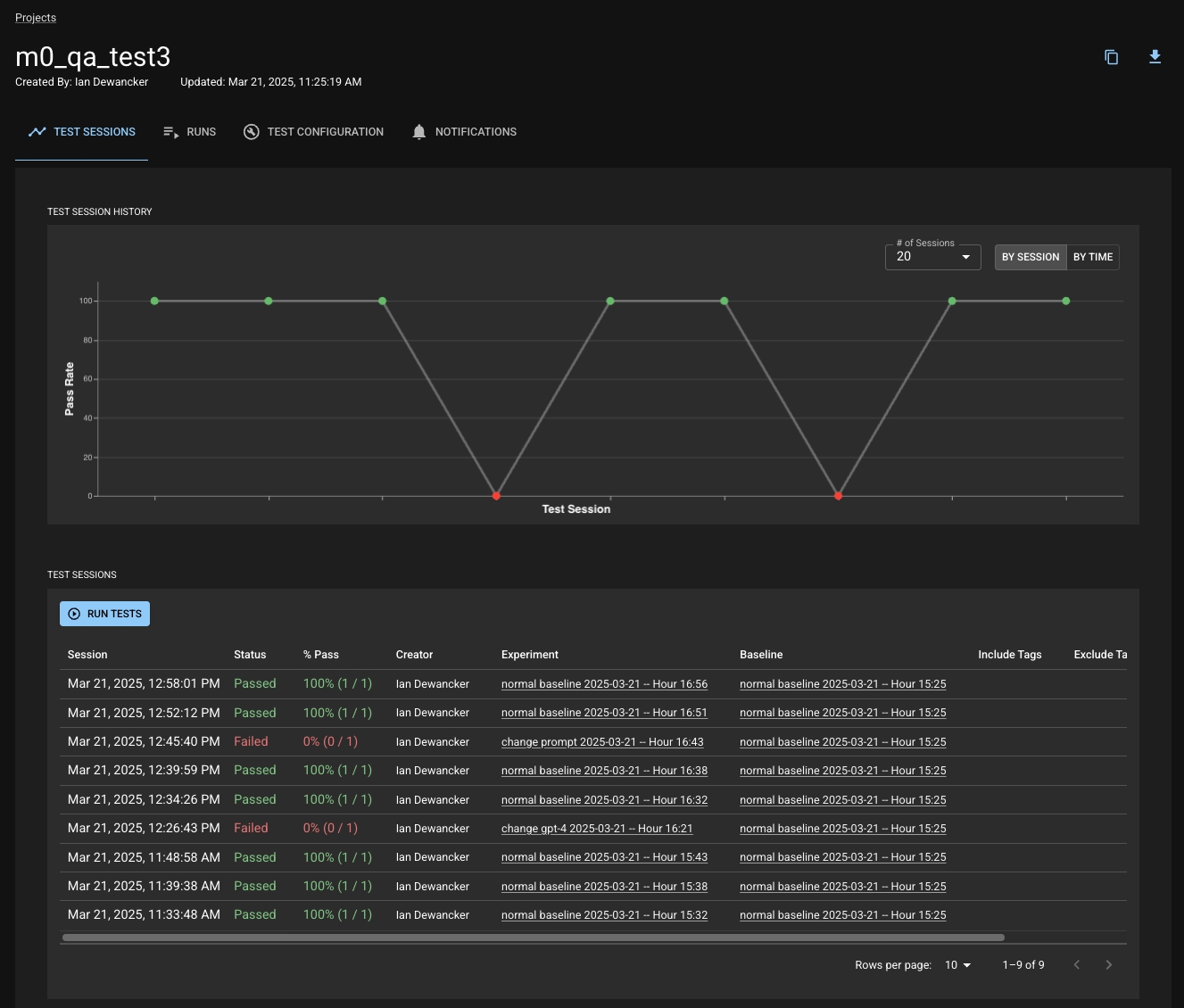
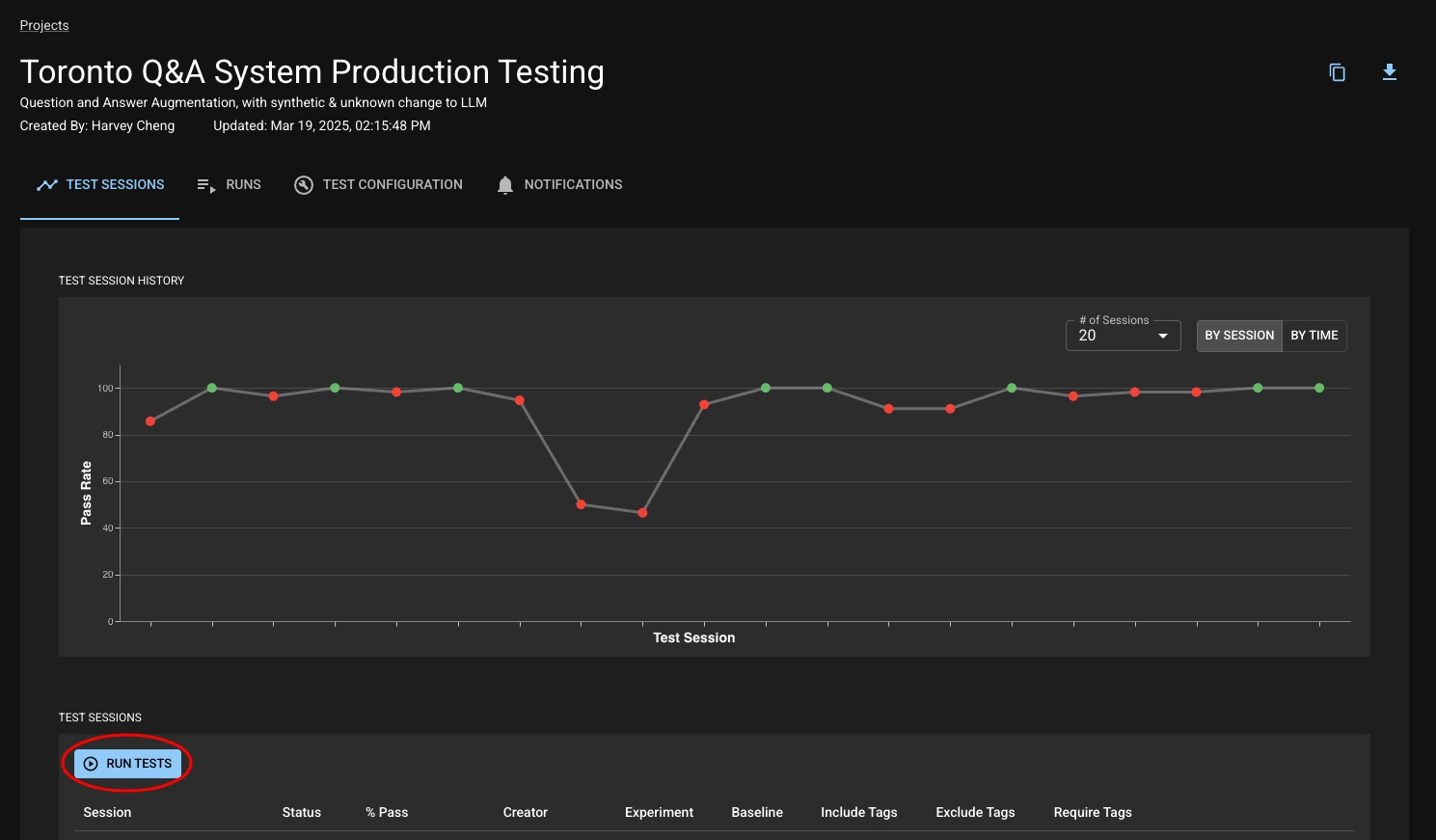
The Test Sessions section in your Project is a record of all the Test Sessions you've created. You can view a line chart of the pass rate of your Test Sessions over time or view a table with each row representing a Test Session You can click on a point in the chart or a row in the table to navigate to the corresponding Test Session's detail page to dig into what happened within that session.
When you first open a Test Session's page, you will land on the Summary tab. This tab provides you with summary information about the session such as the App Similarity Index, which tests have failed, and key insights about the session. There are also tabs to see the Similarity Report (more information below) or to view all the test results within the session.
On the Summary tab, you'll notice a list of key insights that dbnl has discovered about your Test Session. The key insights will tell you at a glance which columns or metrics have had the most significant change in your Experiment Run when compared to the baseline. If you are particularly interested in the column or metric going forward, you can quickly add a test for its Similarity Index.
Expanding one of these will allow you to view some additional information such as a history of the Similarity Index for the related column or metric; if you are viewing a metric, it will also tell you the lineage of which columns the metric is derived from.
The Similarity Report gives you an overview of all the columns your Experiment Run, providing the relevant Similarity Indexes, the ability to quickly create tests from them, and the option to deep-dive into a column. Expanding one of the rows for a column for show you all the metrics calculated for that column, with their own respective Similarity Indexes and details.
If you click on the "See Details" link on any of these rows (or from the Key Insights view), you'll be taken to a view that lets you explore the respective column or metric in detail.
From this view, you can easily compare the changes in the column/metric with graphs and summary statistics. Expanding of the comparison statistics will give you even more information to dig into! Click "Add Test" to quickly create a test on the related statistic.
You can run any tests you've created (or just the default App Similarity Index test) to investigate the behavior of your application.
When you run a Test Session, you are running your tests against a given Experiment Run.
Tests are run within the context of a Test Session, which is effectively just a collection of tests run against an Experiment Run with a Baseline Run. You can create a Test Session, which will immediately run the tests, via the UI or the SDK:
absolute difference of max
-
absolute difference of mean
-
absolute difference of median
-
absolute difference of min
-
absolute difference of percentile
Requires percentage as a parameter.
absolute difference of standard deviation
-
absolute difference of sum
-
Category Rank Discrepancy
Computes the absolute difference in the proportion of the specified category between the experiment and baseline runs. The category is specified by its rank in the baseline run.
Requires rankas a parameter: can be one of [most_common, second_most_common, not_top_two].
Chi-squared stat, scaled
Kolmogorov-Smirnov stat, scaled
max
-
mean
-
median
-
min
-
mode
-
Null Count
Computes the number of None values in a column.
Null Percentage
Computes the fraction of None values in a column.
percentile
Requires percentage as a parameter.
scalar
signed difference of max
-
signed difference of mean
-
signed difference of median
-
signed difference of min
-
signed difference of percentile
Requires percentage as a parameter.
signed difference of standard deviation
-
signed difference of sum
-
standard deviation
-
sum
-
between
between or equal to
close to
equal to
greater than
greater than or equal to
less than
less than or equal to
not equal to
outside
outside or equal to
An overview of the dbnl Query Language
The dbnl Query Language is a SQL-like language that allows for querying data in runs for the purpose of drawing visualizations, defining metrics or evaluating tests.
An expression is a combination of literals, values, operators, and functions. Expressions can evaluate to scalar or columnar values depending on their types and inputs. There are three types of expressions that can be composed into arbitrarily complex expressions.
Literal expressions are constant-valued expressions.
Column and scalar expressions are references to columns or scalar values in a run. They use dot-notation to reference a column or scalar within a run.
For example, a column named score in a run with id run_1234 can be referenced with the expression:
Function expressions are functions evaluated over zero or more other expressions. They make it possible to compose simple expressions into arbitrarily complex expressions.
For example, the word_count function can be used to compute the word count of the text column in a run with id run_1234 with the expression:
Operators are aliases for function expressions that enhance readability and ease of use. Operator precedence is the same as that of most SQL dialect.
Arithmetic operators
Arithmetic operators provide support for basic arithmetic operations.
Comparison operators
Comparison operators provide support for common comparison operations.
Logical operators
Logical operators provide support for boolean comparisons.
The dbnl Query Language follows the null semantics of most SQL dialect. With a few exception, when a null value is used as an input to a function or operator, the result is null.
One exception to this is boolean functions and operators where ternary logic is used similar to most SQL dialects.
Install .
Install , the dbnl CLI and Python SDK.
Within the sandbox container, is used in conjunction with to schedule the containers for the dbnl platform and its dependencies.
The dbnl sandbox image and the dbnl platform images are stored in a private registry. For access, .
Once ready, the dbnl UI will be accessible at .
To use the dbnl Sandbox, set your API URL to , either through or through the .
This will tail the logs from the container. This does not include the logs from the services that run on the Kubernetes cluster within the container. For this, you will need to use the .
Once you've , you can check it out in the UI!
Across the Test Session page, you will see Similarity Indexes at both an "App" level as well as on each of your columns and metrics. This is a special summary score that dbnl calculates for you to help you quickly and easily understand how much your app has changed between the Experiment and Baseline Runs within the session, both holistically and at a granular level. You can define tests on any of the indexes — at the app level or on a specific metric or column. For more information, see the section "".
If you haven't already, take a look at the documentation on . All the methods for running a test will allow you to choose a Baseline Run at the time of Test Session creation, but you can also .
You can choose to run the tests associated with a Project by clicking on the "Run Tests" button on your Project. This button will open up a modal that allows you to specify the Baseline and Experiment Runs, as well as the tags of the tests you would like to include or exclude from the test session.
Tests can be run via the SDK function . Most likely, you will want to create a Test Session shortly after you've reported and closed a Run. See for more information.
Continue onto for how to look at and interpret the results from your Test Session.
Computes a scaled and normalized statistic between two nominal distributions.
Computes a scaled and normalized statistic between two ordinal distributions.
Special function for using in tests. Returns the input as a scalar value if it is a scalar and returns an error otherwise.
Below is a basic working example that highlights the SDK workflow. If you have not yet installed the SDK, follow .
boolean
true
int
42
float
1.0
string
'hello world'
-a
negate(a)
Negate an input.
a * b
multiply(a, b)
Multiply two inputs.
a / b
divide(a, b)
Divide two inputs.
a + b
add(a, b)
Add two inputs.
a - b
subtract(a, b)
Subtract two inputs.
a = b
eq(a, b)
Equal to.
a != b
neq(a, b)
Not equal to.
a < b
lt(a, b)
Less than.
a <= b
lte(a, b)
Less than or equal to.
a > b
gt(a, b)
Greater than.
a >= b
gte(a, b)
Greater than or equal to
not b
not(a, b)
Logical not of input.
a and b
and(a, b)
Logical and of two inputs.
a or b
or(a, b)
Logical or of two inputs.
4 > null
null
null = null
null
null + 2
null
word_count(null)
null
true
null
true
null
false
false
null
null
false
true
null
true
true
null
null
null
false
null
false
null
null
null
null
null
null




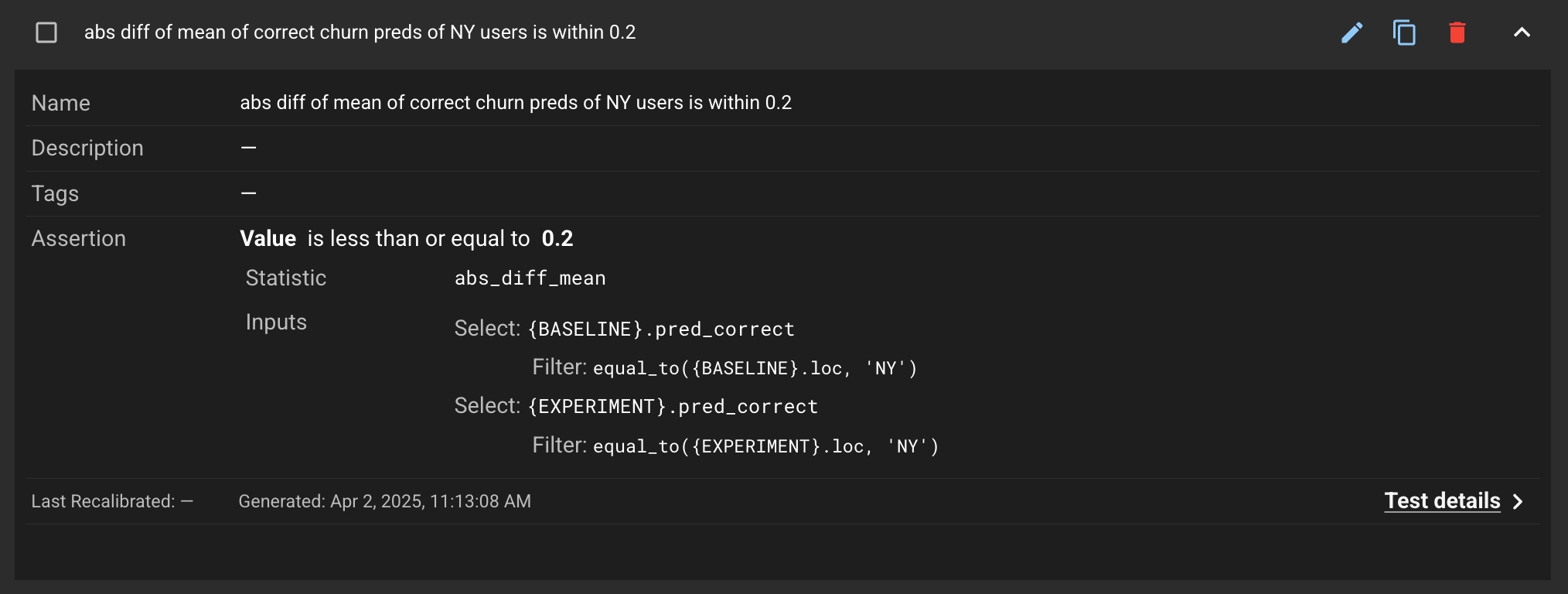
Filters can be used to specify a sub-selection of rows in Runs you would like to be tested.
For example, you might want to create a test that asserts that the absolute difference of means of the correct churn predictions is <= 0.2 between Baseline and Experiment Runs, only for rows where the loc column is NY.
Once you've used one of the methods above, you can now see the new test in the Test Configuration tab of your Project.
When a Test Session is created, this test will use the defined filters to sub-select for the rows that have the loc column equal to NY.
Notifications provide a way for users to be automatically notified about critical test events (e.g., failures or completions) via third-party tools like PagerDuty and Slack.
With Notifications you can:
Add critical test failure alerting to your organization’s on-call
Create custom notifications for specific feature tests
Stay informed when a new test session has started
A Notification is composed of two major elements:
The Notification Channel — this contains the metadata for how and where a Notification will be sent
The Notification Criteria — this defines the rules for when a Notification will be generated
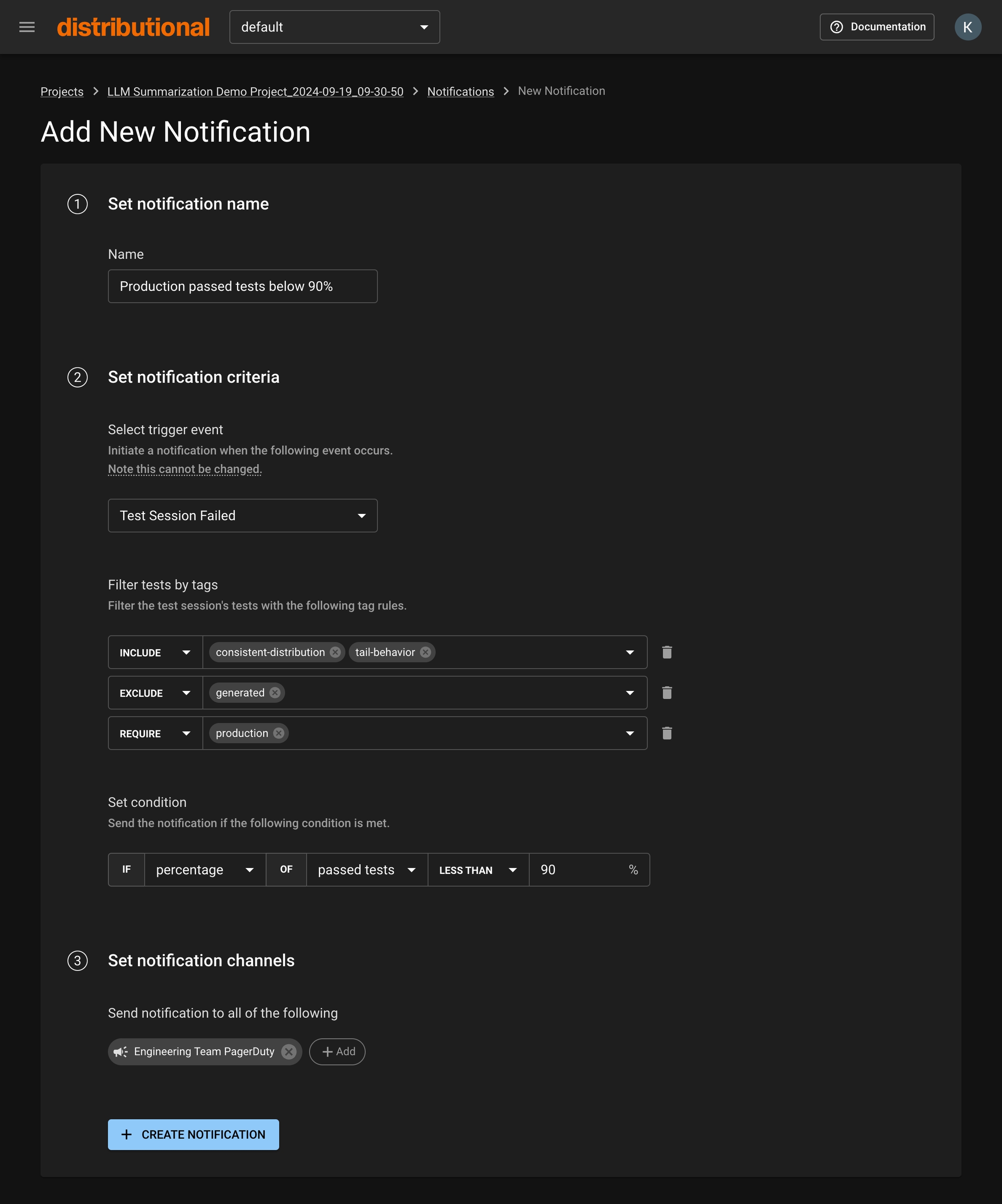
Before setting up a Notification in your project, you must have a Notification Channel set up in your Namespace. A Notification Channel describes who will be notified and how. A Notification Channel in a Namespace can be used by Notifications across all Projects belonging to that Namespace.
In your desired Namespace, choose Notification Channels in the menu sidebar. Note: you must be a Namespace admin in order to do this.
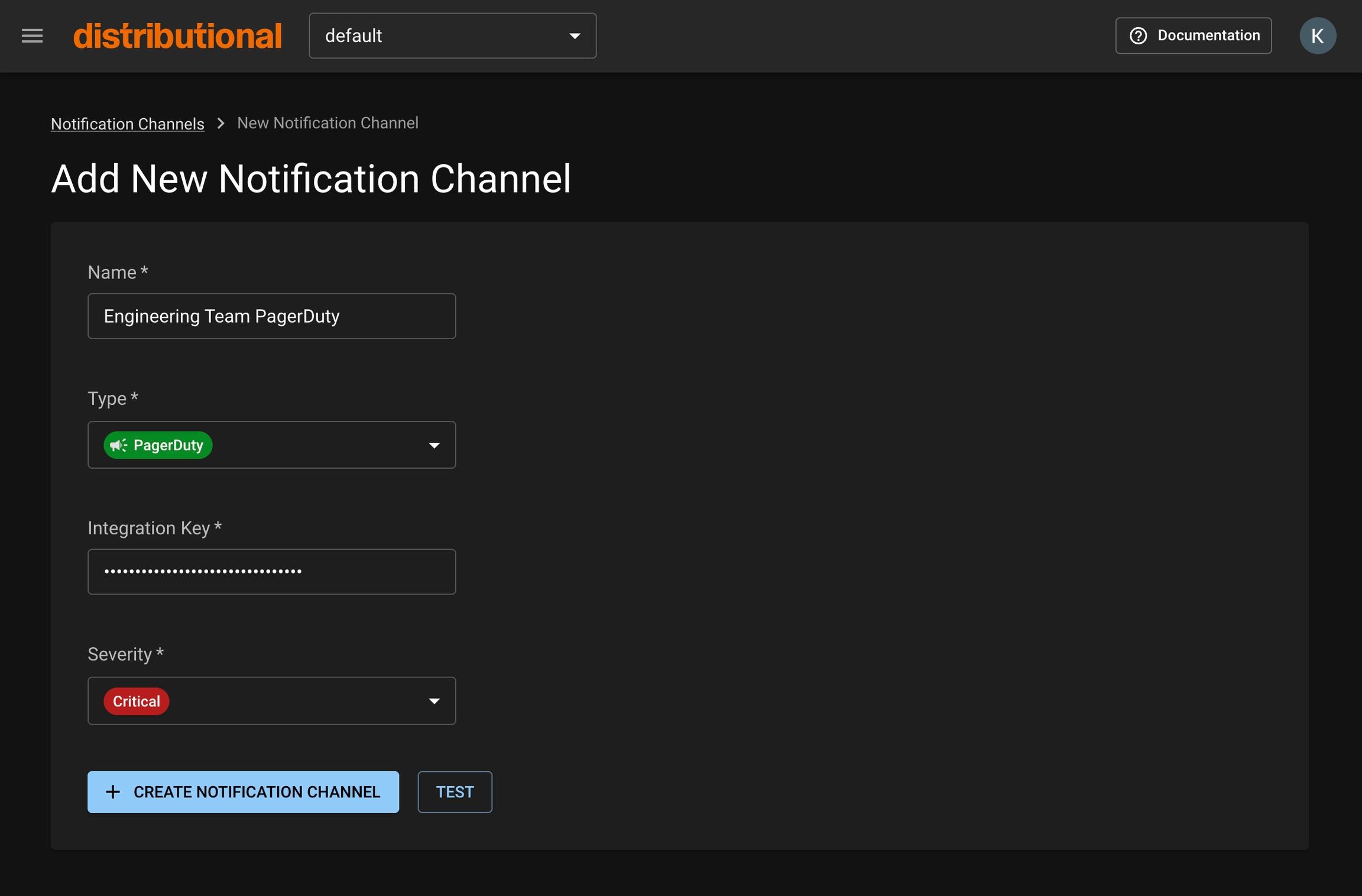
Click the New Notification Channel button to navigate to the creation form.
Fill out the appropriate fields.
Optional: If you’d like to test that your Notification Channel is set up correctly, click the Test button. If it is correctly set up, you should receive a notification through the integration you’ve selected.
Click the Create Notification Channel button. Your channel will now be available when setting up your Notification.
Note: More coming up in the product roadmap!
Navigate to your Project and click the Notifications tab.
Click the "New Notification" button to navigate to the creation form.
Click the "Create Notification" button. Your Notification will now notify you when your specified criteria are met!
Trigger Event
The trigger event describes when your Notification is initiated. Trigger events are based on Test Session outcomes.
Tags Filtering
Filtering by Tags allows you to define which tests in the Test Session you care to be notified about.
There are three types of Tags filters you can provide:
Include: Must have ANY of the selected
Exclude: Must not have ANY of the selected
Require: Must have ALL of the selected
When multiple types are provided, all filters are combined using ‘AND’ logic, meaning all conditions must be met simultaneously.
Note: This field only pertains to the ‘Test Session Failed’ trigger event
Condition
The condition describes the threshold at which you care to be notified. If the condition is met, your Notification will be sent.
Note: This field only pertains to the ‘Test Session Failed’ trigger event
Resources in the dbnl platform are organized using organizations and namespaces.
An organization, or org for short, corresponds to a dbnl deployment.
Some resources, such as users, are defined at the organization level. Those resources are sometimes referred to as organization resources or org resources.
A namespace is a unit of isolation within a dbnl organization.
Most resources, including projects and their related resources, are defined at the namespace level. Resources defined within a namespace are only accessible within that namespace providing isolation between namespaces.
All organizations include a namespace named default. This namespace cannot be modified or deleted.
To switch namespace, use the namespace switcher in the navigation bar.
To create a namespace, go to ☰ > Settings > Admin > Namespaces and click the + Create Namespace button.
The following section introduces the concepts used to control access to the dbnl platform.
An overview of the self-hosted deployment options
The self-hosted deployment option allows you to deploy the dbnl platform directly in your cloud or on-premise environment.
Navigate to the and create the test with the filter specified on the baseline and experiment run.
Filter for the baseline Run:
Filter for the experiment Run:
In adding your Notification Channel, you will be able to select which you'd like to be notified through.
Set your Notification’s name, , and Notification Channels.
See .
You can create a test with filters in the SDK via the function:
Gets the unconnected components DAG from a list of column schemas. If there are no components, returns None. The default components dag is of the form {
“component1”: [], “component2”: [], …}
Parameters:column_schemas – list of column schemas
Returns: dictionary of components DAG or None
Create a TestSessionInput object from a Run or a RunQuery. Useful for creating TestSessions right after closing a Run.
Parameters:
run – The Run to create the TestSessionInput from
run_query – The RunQuery to create the TestSessionInput from
run_alias – Alias for the Run, must be ‘EXPERIMENT’ or ‘BASELINE’, defaults to “EXPERIMENT”
Raises:DBNLInputValidationError – If both run and run_query are None
Returns: TestSessionInput object
Helm chart installation instructions
The Helm chart option separates the infrastructure and permission provisioning process from the dbnl platform deployment process, allowing you to manage the infrastructure, permissions and Helm chart using their existing processes.
The following prerequisite steps are required before starting the Helm chart installation.
To successfully deploy the dbnl Helm chart, you will need the following infrastructure:
To configure the dbnl Helm chart, you will need:
A hostname to host the dbnl platform (e.g. dbnl.example.com).
A set of dbnl registry credentials to pull the dbnl artifacts (e.g. Docker images, Helm chart).
An RSA key pair can be generated with:
To install the dbnl Helm chart, you will need:
For the services deployed by the Helm chart to work as expected, they will need the following permissions and network accesses:
api-srv
Network access to the database.
Network access to the Redis database.
Permission to read, write and generate pre-signed URLs on the object store bucket.
worker-srv
Network access to the database.
Network access to the Redis database.
Permission to read and write to the object store bucket.
The steps to install the Helm chart using the Helm CLI are as follows:
Create an image pull secret with the your dbnl registry credentials.
Create a minimal values.yaml file.
Log into the dbnl Helm registry.
Install the Helm chart.
For more details on all the installation options, see the Helm chart README and values.yaml files. The chart can be inspected with:
An overview of data access controls.
Data for a run is split between the object store (e.g. S3, GCS) and the database.
Metadata (e.g. name, schema) and aggregate data (e.g. summary statistics, histograms) are stored in the database.
Raw data is stored in the object store.
Database access is always done through the API with the API enforcing access controls to ensure users only access data for which they have permission.
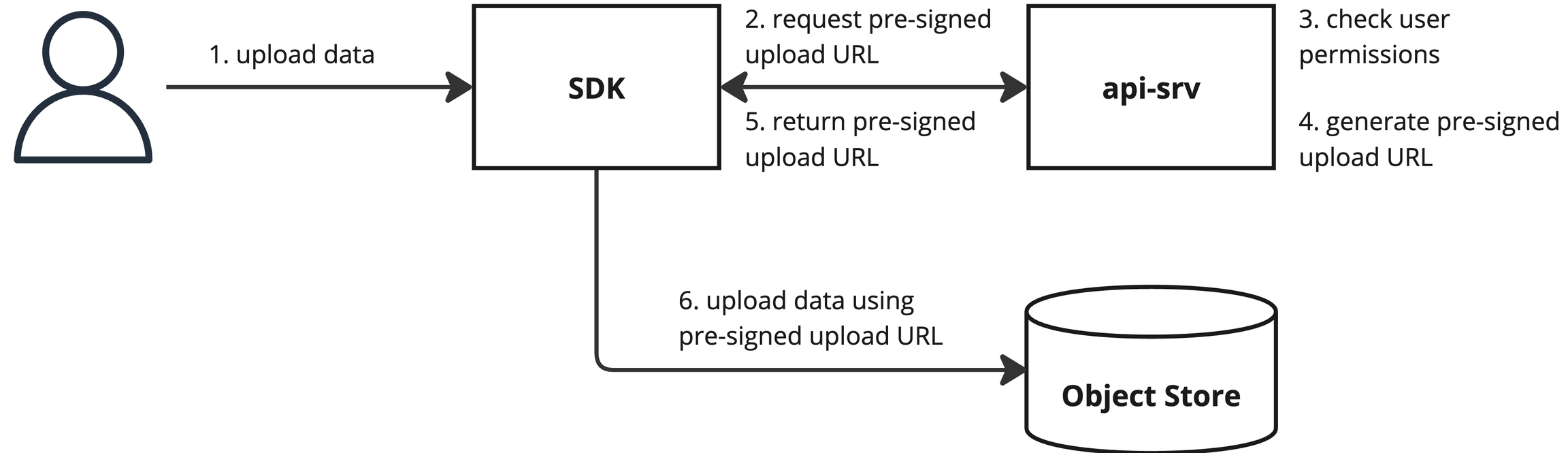
When uploading or downloading data for a run, the SDK first sends a request for a pre-signed upload or download URL to the API. The API enforces access controls, returning an error if the user is missing the necessary permissions. Otherwise, it returns a pre-signed URL which the SDK then uses to upload or download the data.
Returns the column schema for the metric to be used in a run config.
Returns: _description_
Returns the description of the metric.
Returns: Description of the metric.
Evaluates the metric over the provided dataframe.
Parameters:df – Input data from which to compute metric.
Returns: Metric values.
Returns the expression representing the metric (e.g. rouge1(prediction, target)).
Returns: Metric expression.
If true, larger values are assumed to be directionally better than smaller once. If false, smaller values are assumged to be directionally better than larger one. If None, assumes nothing.
Returns: True if greater is better, False if smaller is better, otherwise None.
Returns the input column names required to compute the metric. :return: Input column names.
Returns the metric name (e.g. rouge1). :return: Metric name.
Returns the fully qualified name of the metric (e.g. rouge1__prediction__target).
Returns: Metric name.
Returns the column schema for the metric to be used in a run config.
Returns: _description_
Returns the type of the metric (e.g. float)
Returns: Metric type.
An enumeration.
Computes the accuracy of the answer by evaluating the accuracy score of the answer using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_accuracy available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
context – context column name
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: accuracy metric
Returns answer correctness metric.
This metric is generated by an LLM using a specific specific prompt named llm_answer_correctness available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
prediction – prediction column name
target – target column name
eval_llm_client – eval_llm_client
Returns: answer correctness metric
Returns answer similarity metric.
This metric is generated by an LLM using a specific specific prompt named llm_answer_similarity available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
prediction – prediction column name
target – target column name
eval_llm_client – eval_llm_client
Returns: answer similarity metric
Computes the coherence of the answer by evaluating the coherence score of the answer using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_coherence available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: coherence metric
Computes the commital of the answer by evaluating the commital score of the answer using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_commital available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: commital metric
Computes the completeness of the answer by evaluating the completeness score of the answer using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_completeness available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
prediction – prediction column
eval_llm_client – eval_llm_client
Returns: completeness metric
Computes the contextual relevance of the answer by evaluating the contextual relevance score of the answer using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_contextual_relevance available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
context – context column name
eval_llm_client – eval_llm_client
Returns: contextual relevance metric
Returns faithfulness metric.
This metric is generated by an LLM using a specific specific prompt named llm_faithfulness available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
context – context column name
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: faithfulness metric
Computes the grammar accuracy of the answer by evaluating the grammar accuracy score of the answer using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_grammar_accuracy available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: grammar accuracy metric
Returns a set of metrics which evaluate the quality of the generated answer. This does not include metrics that require a ground truth.
Parameters:
input – input column name (i.e. question)
prediction – prediction column name (i.e. generated answer)
context – context column name (i.e. document or set of documents retrieved)
eval_llm_client – eval_llm_client
Returns: list of metrics
Computes the originality of the answer by evaluating the originality score of the answer using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_originality available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: originality metric
Returns relevance metric with context.
This metric is generated by an LLM using a specific specific prompt named llm_relevance available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
context – context column name
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: answer relevance metric with context
Returns a list of metrics relevant for a question and answer task.
Parameters:
prediction – prediction column name (i.e. generated answer)
eval_llm_client – eval_llm_client
Returns: list of metrics
Computes the reading complexity of the answer by evaluating the reading complexity score of the answer using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_reading_complexity available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: reading complexity metric
Computes the sentiment of the answer by evaluating the sentiment assessment score of the answer using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_sentiment_assessment available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: sentiment assessment metric
Computes the text fluency of the answer by evaluating the perplexity of the answer using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_text_fluency available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: text fluency metric
Computes the toxicity of the answer by evaluating the toxicity score of the answer using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_text_toxicity available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: toxicity metric
Returns the Automated Readability Index metric for the text_col_name column.
Calculates the Automated Readability Index (ARI) for a given text. ARI is a readability metric that estimates the U.S. school grade level necessary to understand the text, based on the number of characters per word and words per sentence.
Parameters:text_col_name – text column name
Returns: automated_readability_index metric
Returns the bleu metric between the prediction and target columns.
The BLEU score is a metric for evaluating a generated sentence to a reference sentence. The BLEU score is a number between 0 and 1, where 1 means that the generated sentence is identical to the reference sentence.
Parameters:
prediction – prediction column name
target – target column name
Returns: bleu metric
Returns the character count metric for the text_col_name column.
Parameters:text_col_name – text column name
Returns: character_count metric
Returns the context hit metric.
This boolean-valued metric is used to evaluate whether the ground truth document is present in the list of retrieved documents. The context hit metric is 1 if the ground truth document is present in the list of retrieved documents, and 0 otherwise.
Parameters:
ground_truth_document_id – ground_truth_document_id column name
retrieved_document_ids – retrieved_document_ids column name
Returns: context hit metric
Returns a set of metrics relevant for a question and answer task.
Parameters:text_col_name – text column name
Returns: list of metrics
Returns the Flesch-Kincaid Grade metric for the text_col_name column.
Calculates the Flesch-Kincaid Grade Level for a given text. The Flesch-Kincaid Grade Level is a readability metric that estimates the U.S. school grade level required to understand the text. It is based on the average number of syllables per word and words per sentence.
Parameters:text_col_name – text column name
Returns: flesch_kincaid_grade metric
Returns a set of metrics relevant for a question and answer task.
Parameters:
prediction – prediction column name (i.e. generated answer)
target – target column name (i.e. expected answer)
Returns: list of metrics
Returns a set of metrics relevant for a question and answer task.
Parameters:
ground_truth_document_id – ground_truth_document_id column name
retrieved_document_ids – retrieved_document_ids column name
Returns: list of metrics
Returns the inner product metric between the ground_truth_document_text and top_retrieved_document_text columns.
This metric is used to evaluate the similarity between the ground truth document and the top retrieved document using the inner product of their embeddings. The embedding client is used to retrieve the embeddings for the ground truth document and the top retrieved document. An embedding is a high-dimensional vector representation of a string of text.
Parameters:
ground_truth_document_text – ground_truth_document_text column name
top_retrieved_document_text – top_retrieved_document_text column name
embedding_client – embedding client
Returns: inner product metric
Returns the inner product metric between the prediction and target columns.
This metric is used to evaluate the similarity between the prediction and target columns using the inner product of their embeddings. The embedding client is used to retrieve the embeddings for the prediction and target columns. An embedding is a high-dimensional vector representation of a string of text.
Parameters:
prediction – prediction column name
target – target column name
embedding_client – embedding client
Returns: inner product metric
Returns the levenshtein metric between the prediction and target columns.
The Levenshtein distance is a metric for evaluating the similarity between two strings. The Levenshtein distance is an integer value, where 0 means that the two strings are identical, and a higher value returns the number of edits required to transform one string into the other.
Parameters:
prediction – prediction column name
target – target column name
Returns: levenshtein metric
Returns the mean reciprocal rank (MRR) metric.
This metric is used to evaluate the quality of a ranked list of documents. The MRR score is a number between 0 and 1, where 1 means that the ground truth document is ranked first in the list. The MRR score is calculated by taking the reciprocal of the rank of the first relevant document in the list.
Parameters:
ground_truth_document_id – ground_truth_document_id column name
retrieved_document_ids – retrieved_document_ids column name
Returns: mrr metric
Returns a set of metrics relevant for a question and answer task.
Parameters:prediction – prediction column name (i.e. generated answer)
Returns: list of metrics
Computes the similarty of the prediction and target text by evaluating using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_text_similarity available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: similarity metric
Returns a set of metrics relevant for a question and answer task.
Parameters:
prediction – prediction column name (i.e. generated answer)
target – target column name (i.e. expected answer)
input – input column name (i.e. question)
context – context column name (i.e. document or set of documents retrieved)
ground_truth_document_id – ground_truth_document_id containing the information in the target
retrieved_document_ids – retrieved_document_ids containing the full context
ground_truth_document_text – text containing the information in the target (ideal is for this to be the top retrieved document)
top_retrieved_document_text – text of the top retrieved document
eval_llm_client – eval_llm_client
eval_embedding_client – eval_embedding_client
Returns: list of metrics
Returns a set of all metrics relevant for a question and answer task.
Parameters:
prediction – prediction column name (i.e. generated answer)
target – target column name (i.e. expected answer)
input – input column name (i.e. question)
context – context column name (i.e. document or set of documents retrieved)
ground_truth_document_id – ground_truth_document_id containing the information in the target
retrieved_document_ids – retrieved_document_ids containing the full context
ground_truth_document_text – text containing the information in the target (ideal is for this to be the top retrieved document)
top_retrieved_document_text – text of the top retrieved document
eval_llm_client – eval_llm_client
eval_embedding_client – eval_embedding_client
Returns: list of metrics
Returns the rouge1 metric between the prediction and target columns.
ROUGE-1 is a recall-oriented metric that calculates the overlap of unigrams (individual words) between the predicted/generated summary and the reference summary. It measures how many single words from the reference summary appear in the predicted summary. ROUGE-1 focuses on basic word-level similarity and is used to evaluate the content coverage.
Parameters:
prediction – prediction column name
target – target column name
Returns: rouge1 metric
Returns the rouge2 metric between the prediction and target columns.
ROUGE-2 is a recall-oriented metric that calculates the overlap of bigrams (pairs of words) between the predicted/generated summary and the reference summary. It measures how many pairs of words from the reference summary appear in the predicted summary. ROUGE-2 focuses on word-level similarity and is used to evaluate the content coverage.
Parameters:
prediction – prediction column name
target – target column name
Returns: rouge2 metric
Returns the rougeL metric between the prediction and target columns.
ROUGE-L is a recall-oriented metric based on the Longest Common Subsequence (LCS) between the reference and generated summaries. It measures how well the generated summary captures the longest sequences of words that appear in the same order in the reference summary. This metric accounts for sentence-level structure and coherence.
Parameters:
prediction – prediction column name
target – target column name
Returns: rougeL metric
Returns the rougeLsum metric between the prediction and target columns.
ROUGE-LSum is a variant of ROUGE-L that applies the Longest Common Subsequence (LCS) at the sentence level for summarization tasks. It evaluates how well the generated summary captures the overall sentence structure and important elements of the reference summary by computing the LCS for each sentence in the document.
Parameters:
prediction – prediction column name
target – target column name
Returns: rougeLsum metric
Returns all rouge metrics between the prediction and target columns.
Parameters:
prediction – prediction column name
target – target column name
Returns: list of rouge metrics
Returns the sentence count metric for the text_col_name column.
Parameters:text_col_name – text column name
Returns: sentence_count metric
Returns a set of metrics relevant for a summarization task.
Parameters:
prediction – prediction column name (i.e. generated summary)
target – target column name (i.e. expected summary)
Returns: list of metrics
Returns a set of metrics relevant for a generic text application
Parameters:
prediction – prediction column name (i.e. generated text)
target – target column name (i.e. expected text)
Returns: list of metrics
Returns the token count metric for the text_col_name column.
A token is a sequence of characters that represents a single unit of meaning, such as a word or punctuation mark. The token count metric calculates the total number of tokens in the text. Different languages may have different tokenization rules. This function is implemented using the spaCy library.
Parameters:text_col_name – text column name
Returns: token_count metric
Returns the word count metric for the text_col_name column.
Parameters:text_col_name – text column name
Returns: word_count metric
A common strategy for evaluating unstructured text application is to use other LLMs and text embedding models to drive metrics of interest.
The following examples show how to initialize an llm_eval_client and an eval_embedding_client under different providers.
It is possible for some of the LLM-as-judge metrics to occasionally return values that are unable to be parsed. These metrics values will surface as None
Distributional is able to accept dataframes including None values. The platform will intelligently filter them when applicable.
LLM service providers often impose request rate limits and token throughput caps. Some example errors that one might encounter are shown below:
In the event you experience these errors, please work with your LLM service provider to adjust your limits. Additionally, feel free to reach out to Distributional support with the issue you are seeing.
Create a new Test Spec
Parameters:test_spec_dict – A dictionary containing the Test Spec schema.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in.
DBNLAPIValidationError – Test Spec does not conform to expected format.
DBNLDuplicateError – Test Spec with the same name already exists in the Project.
Returns: The JSON dict of the created Test Spec object. The return JSON will contain the id of the Test Spec.
Test Spec JSON Structure
Create a Test Generation Session
Parameters:
run – The Run to use when generating tests.
columns – List of columns in the Run to generate tests for. If None, all columns in the Run will be used, defaults to None. If a list of strings, each string is a column name. If a list of dictionaries, each dictionary must have a ‘name’ key, and the value is the column name.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in.
DBNLInputValidationError – arguments do not conform to expected format.
Returns: The TestGenerationSession that was created.
Create a Test Recalibration Session by redefining the expected output for tests in a Test Session
Parameters:
test_session – Test Session to recalibrate
feedback – Feedback for the recalibration. Can be ‘PASS’ or ‘FAIL’.
test_ids – List of test IDs to recalibrate, defaults to None. If None, all tests in the Test Session will be recalibrated.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in.
DBNLInputValidationError – arguments do not conform to expected format.
Returns: Test Recalibration Session
If some generated Tests failed when they should have passed and some passed when they should have failed, you will need to submit 2 separate calls, one for each feedback result.
Get the specified Test Tag or create a new one if it does not exist
Parameters:
project_id – The id of the Project that this Test Tag is associated with.
name – The name of the Test Tag to create or retrieve.
description – An optional description of the Test Tag. Limited to 255 characters.
Returns: The dictionary containing the Test Tag
Raises:DBNLNotLoggedInError – dbnl SDK is not logged in.
Get all Test Sessions in the given Project
Parameters:project – Project from which to retrieve Test Sessions
Returns: List of Test Sessions
Raises:DBNLNotLoggedInError – dbnl SDK is not logged in.
Get all Tests executed in the given Test Session
Parameters:test_session_id – Test Session ID
Returns: List of test JSONs
Raises:DBNLNotLoggedInError – dbnl SDK is not logged in.
Formats a Test Spec payload for the API. Add project_id if it is not present. Replace tag_names with tag_ids.
Parameters:
test_spec_dict – A dictionary containing the Test Spec schema.
project_id – The Project ID, defaults to None. If project_id does not exist in test_spec_dict, it is required as an argument.
Raises:DBNLInputValidationError – Input does not conform to expected format
Returns: The dictionary containing the newly formatted Test Spec payload.
Wait for a Test Generation Session to finish. Polls every 3 seconds until it is completed.
Parameters:
test_generation_session – The TestGenerationSession to wait for.
timeout_s – The total wait time (in seconds) for Test Generation Session to complete, defaults to 180.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in.
DBNLError – Test Generation Session did not complete after waiting for the timeout_s seconds
Returns: The completed TestGenerationSession
Wait for a Test Recalibration Session to finish. Polls every 3 seconds until it is completed.
Parameters:
test_recalibration_session – The TestRecalibrationSession to wait for.
timeout_s – The total wait time (in seconds) for Test Recalibration Session to complete, defaults to 180.
Returns: The completed TestRecalibrationSession
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in.
DBNLError – Test Recalibration Session did not complete after waiting for the timeout_s seconds
Wait for a Test Session to finish. Polls every 3 seconds until it is completed.
Parameters:
test_session – The TestSession to wait for
timeout_s – The total wait time (in seconds) for Test Session to complete, defaults to 180.
Returns: The completed TestSession
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in.
DBNLError – Test Session did not complete after waiting for the timeout_s seconds
Mark the specified dbnl Run status as closed. A closed run is finalized and considered complete. Once a Run is marked as closed, it can no longer be used for reporting Results.
Note that the Run will not be closed immediately. It will transition into a closing state and will be closed in the background. If wait_for_close is set to True, the function will block for up to 3 minutes until the Run is closed.
Parameters:
run – The Run to be closed
wait_for_close – If True, the function will block for up to 3 minutes until the Run is closed, defaults to True
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
DBNLError – Run did not close after waiting for 3 minutes
A run must be closed for uploaded results to be shown on the UI.
Copy a Project; a convenience method wrapping exporting and importing a project with a new name and description
Parameters:
project – The project to copy
name – A name for the new Project
description – An optional description for the new Project. Description is limited to 255 characters.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
DBNLConflictingProjectError – Project with the same name already exists
Returns: The newly created Project
Create a new DBNL Metric
Parameters:
project – DBNL Project to create the Metric for
name – Name for the Metric
expression_template – Expression template string e.g. token_count({RUN}.question)
description – Optional description of what computation the metric is performing
greater_is_better – Flag indicating whether greater values are semantically ‘better’ than lesser values
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
Returns: Created Metric
Create a new Project
Parameters:
name – Name for the Project
description – Description for the DBNL Project, defaults to None. Description is limited to 255 characters.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLAPIValidationError – DBNL API failed to validate the request
DBNLConflictingProjectError – Project with the same name already exists
Returns: Project
Create a new Run
Parameters:
project – The Project this Run is associated with.
run_schema – The schema for data that will be associated with this run. DBNL will validate data you upload against this schema.
display_name – An optional display name for the Run, defaults to None. display_name does not have to be unique.
metadata – Additional key-value pairs you want to track, defaults to None.
run_config – (Deprecated) Do not use. Use run_schema instead.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
Returns: Newly created Run
(Deprecated) Please see create_run_schema instead.
Parameters:
project – DBNL Project this RunConfig is associated to
columns – List of column schema specs for the uploaded data, required keys name and type, optional key component, description and greater_is_better. type can be int, float, category, boolean, or string. component is a string that indicates the source of the data. e.g. “component” : “sentiment-classifier” or “component” : “fraud-predictor”. Specified components must be present in the components_dag dictionary. greater_is_better is a boolean that indicates if larger values are better than smaller ones. False indicates smaller values are better. None indicates no preference. An example RunConfig columns: columns=[{“name”: “pred_proba”, “type”: “float”, “component”: “fraud-predictor”}, {“name”: “decision”, “type”: “boolean”, “component”: “threshold-decision”}, {“name”: “error_type”, “type”: “category”}]
scalars –
List of scalar schema specs for the uploaded data, required keys name and type, optional key component, description and greater_is_better. : type can be int, float, category, boolean, or string. component is a string that indicates the source of the data. e.g. “component” : “sentiment-classifier” or “component” : “fraud-predictor”. Specified components must be present in the components_dag dictionary.
greater_is_better is a boolean that indicates if larger values are better than smaller ones. False indicates smaller values are better. None indicates no preference.
An example RunConfig scalars: scalars=[{“name”: “accuracy”, “type”: “float”, “component”: “fraud-predictor”}, {“name”: “error_type”, “type”: “category”}]
description – Description for the DBNL RunConfig, defaults to None. Description is limited to 255 characters.
display_name – Display name for the RunConfig, defaults to None. display_name does not have to be unique.
row_id – List of column names that are the unique identifier, defaults to None.
components_dag – Optional dictionary representing the DAG of components, defaults to None. eg : {“fraud-predictor”: [‘threshold-decision”], “threshold-decision”: []},
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
Returns: RunConfig with the desired columns schema
(Deprecated) Please see create_run_schema_from_results instead.
Parameters:
project – DBNL Project to create the RunConfig for
column_data – DataFrame with the results for the columns
scalar_data – Dictionary or DataFrame with the results for the scalars, defaults to None
description – Description for the RunConfig, defaults to None
display_name – Display name for the RunConfig, defaults to None
row_id – List of column names that are the unique identifier, defaults to None
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
Returns: RunConfig with the desired schema for columns and scalars, if provided
Create a new RunQuery for a project to use as a baseline Run. Currently supports key=”offset_from_now” with value as a positive integer, representing the number of runs to go back for the baseline. For example, query={“offset_from_now”: 1} will use the latest run as the baseline, so that each run compares against the previous run.
Parameters:
project – The Project to create the RunQuery for
name – A name for the RunQuery
query – A dict describing how to find a Run dynamically. Currently, only supports “offset_from_now”: int as a key-value pair.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
Returns: A new dbnl RunQuery, typically used for finding a Dynamic Baseline for a Test Session
Create a new RunSchema
Parameters:
columns – List of column schema specs for the uploaded data, required keys name and type, optional keys component, description and greater_is_better.
scalars – List of scalar schema specs for the uploaded data, required keys name and type, optional keys component, description and greater_is_better.
index – Optional list of column names that are the unique identifier.
components_dag – Optional dictionary representing the DAG of components.
Returns: The RunSchema
int
float
boolean
string
category
list
The optional component key is for specifying the source of the data column in relationship to the AI/ML app subcomponents. Components are used in visualizing the components DAG.
The components_dag dictionary specifies the topological layout of the AI/ML app. For each key-value pair, the key represents the source component, and the value is a list of the leaf components. The following code snippet describes the DAG shown above.
Basic
With `scalars`, `index`, and `components_dag`
Create a new RunSchema from the column results, as well as scalar results if provided
Parameters:
column_data – A pandas DataFrame with all the column results for which we want to generate a RunSchema.
scalar_data – A dict or pandas DataFrame with all the scalar results for which we want to generate a RunSchema.
index – An optional list of the column names that can be used as unique identifiers.
Raises:DBNLInputValidationError – Input does not conform to expected format
Returns: The RunSchema based on the provided results
Create a new TestSession with the given Run as the Experiment Run, and the given Run or RunQuery as the baseline if provided
Parameters:
experiment_run – The Run to create the TestSession for
baseline – The Run or RunQuery to use as the Baseline Run, defaults to None. If None, the Baseline set for the Project is used.
include_tags – Optional list of Test Tag names to include in the Test Session.
exclude_tags – Optional list of Test Tag names to exclude in the Test Session.
require_tags – Optional list of Test Tag names to require in the Test Session.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
Returns: The newly created TestSession
Calling this will start evaluating Tests associated with a Run. Typically, the Run you just completed will be the “Experiment” and you’ll compare it to some earlier “Baseline Run”.
Referenced Runs must already be closed before a Test Session can begin.
Suppose we have the following Tests with the associated Tags in our Project
Test1 with tags [“A”, “B”]
Test2 with tags [“A”]
Test3 with tags [“B”]
include_tags=[“A”, “B”] will trigger Tests 1, 2, and 3. require_tags=[“A”, “B”] will only trigger Test 1. exclude_tags=[“A”] will only trigger Test 3. include_tags=[“A”] and exclude_tags=[“B”] will only trigger Test 2.
Delete a DBNL Metric by ID
Parameters:metric_id – ID of the metric to delete
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLAPIValidationError – DBNL API failed to validate the request
Returns: None
Export a Project alongside its Test Specs, Tags, and Notification Rules as a JSON object
Parameters:project – The Project to export as JSON.
Raises:DBNLNotLoggedInError – dbnl SDK is not logged in
Returns: JSON object representing the Project
Get column results for a Run
Parameters:run – The Run from which to retrieve the results.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
DBNLDownloadResultsError – Failed to download results (e.g. Run is not closed)
Returns: A pandas DataFrame of the column results for the Run.
You can only retrieve results for a Run that has been closed.
Get the latest Run for a project
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLResourceNotFoundError – Run not found
Parameters:project – The Project to get the latest Run for
Returns: The latest Run
(Deprecated) Please see get_latest_run and access the schema attribute instead.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLResourceNotFoundError – RunConfig not found
Parameters:project – DBNL Project to get the latest RunConfig for
Returns: Latest RunConfig
Get a DBNL Metric by ID
Parameters:metric_id – ID of the metric to get
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLAPIValidationError – DBNL API failed to validate the request
Returns: The requested metric
Get all the namespaces that the user has access to
Raises:DBNLNotLoggedInError – dbnl SDK is not logged in
Returns: List of namespaces
Get the Project with the specified name or create a new one if it does not exist
Parameters:
name – Name for the Project
description – Description for the DBNL Project, defaults to None
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLAPIValidationError – DBNL API failed to validate the request
Returns: Newly created or matching existing Project
Retrieve a Project by name.
Parameters:name – The name for the existing Project.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLProjectNotFoundError – Project with the given name does not exist.
Returns: Project
Get all results for a Run
Parameters:run – The Run from which to retrieve the results.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
DBNLDownloadResultsError – Failed to download results (e.g. Run is not closed)
Returns: A named tuple comprised of columns and scalars fields. These are the pandas DataFrames of the uploaded data for the Run.
You can only retrieve results for a Run that has been closed.
Retrieve a Run with the given ID
Parameters:run_id – The ID of the dbnl Run. Run ID starts with the prefix run_. Run ID can be found at the Run detail page.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
DBNLRunNotFoundError – A Run with the given ID does not exist.
Returns: The Run with the given run_id.
(Deprecated) Please access Run.schema instead.
Parameters:run_config_id – The ID of the DBNL RunConfig to retrieve
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
Returns: RunConfig with the given run_config_id
(Deprecated) Please see get_latest_run and access the schema attribute instead.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLResourceNotFoundError – RunConfig not found
Parameters:project – DBNL Project to get the latest RunConfig for
Returns: RunConfig from the latest Run
Retrieve a DBNL RunQuery with the given name, unique to a project
Parameters:
project – The Project from which to retrieve the RunQuery.
name – The name of the RunQuery to retrieve.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLRessourceNotFoundError – RunQuery not found
Returns: RunQuery with the given name.
Get scalar results for a Run
Parameters:run – The Run from which to retrieve the scalar results.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
DBNLDownloadResultsError – Failed to download results (e.g. Run is not closed)
Returns: A pandas DataFrame of the scalar results for the Run.
You can only retrieve results for a Run that has been closed.
Create a new Project from a JSON object
Parameters:params – JSON object representing the Project, generally based on a Project exported via export_project_as_json(). See export_project_as_json() for the expected format.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLAPIValidationError – DBNL API failed to validate the request
DBNLConflictingProjectError – Project with the same name already exists
Returns: Project created from the JSON object
Setup dbnl SDK to make authenticated requests. After login is run successfully, the dbnl client will be able to issue secure and authenticated requests against hosted endpoints of the dbnl service.
Parameters:
api_token – DBNL API token for authentication; token can be found at /tokens page of the DBNL app. If None is provided, the environment variable DBNL_API_TOKEN will be used by default.
namespace_id – DBNL namespace ID to use for the session; available namespaces can be found with get_my_namespaces().
api_url – The base url of the Distributional API. For SaaS users, set this variable to api.dbnl.com. For other users, please contact your sys admin. If None is provided, the environment variable DBNL_API_URL will be used by default.
app_url – An optional base url of the Distributional app. If this variable is not set, the app url is inferred from the DBNL_API_URL variable. For on-prem users, please contact your sys admin if you cannot reach the Distributional UI.
Report all column results to dbnl
Parameters:
run – The Run that the results will be reported to
data – A pandas DataFrame with all the results to report to dbnl. The columns of the DataFrame must match the columns of the Run’s schema.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
All data should be reported to dbnl at once. Calling dbnl.report_column_results more than once will overwrite the previously uploaded data.
Once a Run is closed, you can no longer call report_column_results to send data to dbnl.
Report all results to dbnl
Parameters:
run – The Run that the results will be reported to
column_data – A pandas DataFrame with all the results to report to dbnl. The columns of the DataFrame must match the columns of the Run’s schema.
scalar_data – A dictionary or single-row pandas DataFrame with the scalar results to report to dbnl, defaults to None.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
All data should be reported to dbnl at once. Calling dbnl.report_results more than once will overwrite the previously uploaded data.
Once a Run is closed, you can no longer call report_results to send data to dbnl.
Create a new Run, report results to it, and close it.
Parameters:
project – The Project to create the Run in.
column_data – A pandas DataFrame with the results for the columns.
scalar_data – An optional dictionary or DataFrame with the results for the scalars, if any.
display_name – An optional display name for the Run.
index – An optional list of column names to use as the unique identifier for rows in the column data.
run_schema – An optional RunSchema to use for the Run. Will be inferred from the data if not provided.
metadata – Any additional key:value pairs you want to track.
wait_for_close – If True, the function will block for up to 3 minutes until the Run is closed, defaults to True.
row_id – (Deprecated) Do not use. Use index instead.
run_config_id – (Deprecated) Do not use. Use run_schema instead.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
Returns: The closed Run with the uploaded data.
If no schema is provided, the schema will be inferred from the data. If provided, the schema will be used to validate the data.
Implicit Schema
Explicit Schema
Create a new Run, report results to it, and close it. Wait for close to finish and start a TestSession with the given inputs.
Parameters:
project – The Project to create the Run in.
column_data – A pandas DataFrame with the results for the columns.
scalar_data – An optional dictionary or DataFrame with the results for the scalars, if any.
display_name – An optional display name for the Run.
index – An optional list of column names to use as the unique identifier for rows in the column data.
run_schema – An optional RunSchema to use for the Run. Will be inferred from the data if not provided.
metadata – Any additional key:value pairs you want to track.
wait_for_close – If True, the function will block for up to 3 minutes until the Run is closed, defaults to True.
baseline – DBNL Run or RunQuery to use as the baseline run, defaults to None. If None, the baseline defined in the TestConfig is used.
include_tags – Optional list of Test Tag names to include in the Test Session.
exclude_tags – Optional list of Test Tag names to exclude in the Test Session.
require_tags – Optional list of Test Tag names to require in the Test Session.
row_id – (Deprecated) Do not use. Use index instead.
run_config_id – (Deprecated) Do not use. Use run_schema instead.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
Returns: The closed Run with the uploaded data.
If no schema is provided, the schema will be inferred from the data. If provided, the schema will be used to validate the data.
Report scalar results to dbnl
Parameters:
run – The Run that the scalars will be reported to
data – A dictionary or single-row pandas DataFrame with the scalar results to report to dbnl.
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
All data should be reported to dbnl at once. Calling dbnl.report_scalar_results more than once will overwrite the previously uploaded data.
Once a Run is closed, you can no longer call report_scalar_results to send data to dbnl.
Set the given Run as the Baseline Run in the Project’s Test Config
Parameters:run – The Run to set as the Baseline Run.
Raises:DBNLResourceNotFoundError – If the test configurations are not found for the project.
Set a given RunQuery as the Baseline Run in a Project’s Test Config
Parameters:run_query – The RunQuery to set as the Baseline RunQuery.
Raises:DBNLResourceNotFoundError – If the test configurations are not found for the project.
Wait for a Run to close. Polls every polling_interval_s seconds until it is closed.
Parameters:
run – Run to wait for
timeout_s – Total wait time (in seconds) for Run to close, defaults to 180.0
polling_interval_s – Time between polls (in seconds), defaults to 3.0
Raises:
DBNLNotLoggedInError – dbnl SDK is not logged in
DBNLError – Run did not close after waiting for the timeout_s seconds
For access to the Helm chart and to get registry credentials, .
A Kubernetes cluster (e.g. , ).
An or controller (e.g. , )
A PostgreSQL database (e.g. , ).
An object store bucket (e.g. , ) to store raw data.
A Redis database (e.g. , ) to act as a messaging queue.
An RSA key pair to sign the .
Install and set the Kubernetes cluster context.
Install .
The Helm chart can be installed directly using or using your chart release management tool of choice such as or .
All data accesses are mediated by the API ensuring the enforcement of access controls. For more details on permissions, see .
Direct object store access is required to upload or download raw run data using the SDK. are used to provide limited direct access. This access is limited in both time and scope, ensuring only data for a specific run is accessible and that it is only accessible for a limited time.
The LLM-as-judge in dbnl.eval support OpenAI, Azure OpenAI and any other third-party LLM / embedding model provider that is compatible with the OpenAI python client. Specifically, third-party endpoints should (mostly) adhere to the schema of:
endpoint for LLMs
endpoint for embedding models
The dbnl CLI is installed as part of the SDK and allows for interacting with the dbnl platform from the command line.
To install the SDK, run:
The dbnl CLI.
Options
--version
Show the version and exit.
Info about SDK and API.
Login to dbnl.
Options
--api-url <api_url>
API url
--app-url <app_url>
App url
--namespace-id <namespace_id>
Namespace id
Arguments
API_TOKEN
Required argument
Environment variables
DBNL_API_TOKEN
Provide a default for
API_TOKEN
DBNL_API_URL
Provide a default for
--api-url
DBNL_APP_URL
Provide a default for
--app-url
DBNL_NAMESPACE_ID
Provide a default for
--namespace-id
Logout of dbnl.
Subcommand to interact with the sandbox.
Delete sandbox data.
Exec a command on the sandbox.
Arguments
COMMAND
Optional argument(s)
Tail the sandbox logs.
Start the sandbox.
Options
-u, --registry-username <registry_username>
Registry username
-p, --registry-password <registry_password>
Required Registry password
--registry
Registry
Default:'us-docker.pkg.dev/dbnlai/images'
--version
Sandbox version
Default:'0.23'
--base-url <base_url>
Sandbox base url
Default:'http://localhost:8080'
Get sandbox status.
Stop the sandbox.
Many generative AI applications focus on text generation. It can be challenging to create metrics for insights into expected performance when dealing with unstructured text.
dbnl.eval is a special module designed for evaluating unstructured text. This module currently includes:
Adaptive metric sets for generic text and RAG applications
12+ simple statistical local library powered text metrics
15+ LLM-as-judge and embedding powered text metrics
Support for user-defined custom LLM-as-judge metrics
LLM-as-judge metrics compatible with OpenAI, Azure OpenAI
Building dbnl tests on these evaluation metrics can then drive rich insights into an AI application's stability and performance.
Alias for field number 0
Alias for field number 1
text_metrics()Basic metrics for generic text comparison and monitoring
token_count
word_count
flesch_kincaid_grade
automated_readability_index
bleu
levenshtein
rouge1
rouge2
rougeL
rougeLsum
llm_text_toxicity_v0
llm_sentiment_assessment_v0
llm_reading_complexity_v0
llm_grammar_accuracy_v0
inner_product
llm_text_similarity_v0
question_and_answer_metrics()Basic metrics for RAG / question answering
llm_accuracy_v0
llm_completeness_v0
answer_similarity_v0
faithfulness_v0
mrr
context_hit
The metric set helpers are adaptive in that :
The metrics returned encode which columns of the dataframe are input to the metric computation
e.g., rougeL_prediction__ground_truth is the rougeL metric run with both the column named prediction and the column named ground_truth as input
The metrics returned support any additional optional column info and LLM-as-judge or embedding model clients. If any of this optional info is not provided, the metric set will exclude any metrics that depend on that information
The metric set helpers return an adaptive list of metrics, relevant to the application type. See the for details on all the metric functions available in the eval SDK.
See the for concrete examples of adaptive text_metrics() usage
See the for question_and_answer_metrics() usage
Create a new RunSchema from column results, scalar results, and metrics.
This function assumes that the metrics have already been evaluated on the original, un-augmented data. In other words, the column data for the metrics should also be present in the column_data.
Parameters:
column_data – DataFrame with the results for the columns
scalar_data – Dictionary or DataFrame with the results for the scalars, defaults to None
index – List of column names that are the unique identifier, defaults to None
metrics – List of metrics to report with the run, defaults to None
Raises:DBNLInputValidationError – Input does not conform to expected format
Returns: RunSchema with the desired schema for columns and scalars, if provided
Evaluates a set of metrics on a dataframe, returning an augmented dataframe.
Parameters:
df – input dataframe
metrics – metrics to compute
inplace – whether to modify the input dataframe in place
Returns: input dataframe augmented with metrics
Gets the run schema column schemas for a dataframe that was augmented with a list of metrics.
Parameters:
df – Dataframe to get column schemas from
metrics – list of metrics added to the dataframe
Returns: list of columns schemas for dataframe and metrics
Gets the run schema column schemas from a list of metrics.
Parameters:metrics – list of metrics to get column schemas from
Returns: list of column schemas for metrics
Gets the run schema column schemas from a list of metrics.
Parameters:metrics – list of metrics to get column schemas from
Returns: list of column schemas for metrics
Create a new Run, report results to it, and close it.
If run_schema is not provided, a RunSchema will be created from the data. If a run_schema is provided, the results are validated against it.
If metrics are provided, they are evaluated on the column data before reporting.
Parameters:
project – DBNL Project to create the Run for
column_data – DataFrame with the results for the columns
scalar_data – Dictionary or DataFrame with the results for the scalars, if any. Defaults to None
display_name – Display name for the Run, defaults to None.
index – List of column names that are the unique identifier, defaults to None. Only used when creating a new schema.
run_schema – RunSchema to use for the Run, defaults to None.
metadata – Additional key:value pairs user wants to track, defaults to None
metrics – List of metrics to report with the run, defaults to None
wait_for_close – If True, the function will block for up to 3 minutes until the Run is closed, defaults to True
Raises:
DBNLNotLoggedInError – DBNL SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
Returns: Run, after reporting results and closing it
Create a new Run, report results to it, and close it. Start a TestSession with the given inputs. If metrics are provided, they are evaluated on the column data before reporting.
Parameters:
project – DBNL Project to create the Run for
column_data – DataFrame with the results for the columns
scalar_data – Dictionary or DataFrame with the scalar results to report to DBNL, defaults to None.
display_name – Display name for the Run, defaults to None.
index – List of column names that are the unique identifier, defaults to None. Only used when creating a new schema.
run_schema – RunSchema to use for the Run, defaults to None.
metadata – Additional key:value pairs user wants to track, defaults to None
baseline – DBNL Run or RunQuery to use as the baseline run, defaults to None. If None, the baseline defined in the TestConfig is used.
include_tags – List of Test Tag names to include in the Test Session
exclude_tags – List of Test Tag names to exclude in the Test Session
require_tags – List of Test Tag names to require in the Test Session
metrics – List of metrics to report with the run, defaults to None
Raises:
DBNLNotLoggedInError – DBNL SDK is not logged in
DBNLInputValidationError – Input does not conform to expected format
Returns: Run, after reporting results and closing it
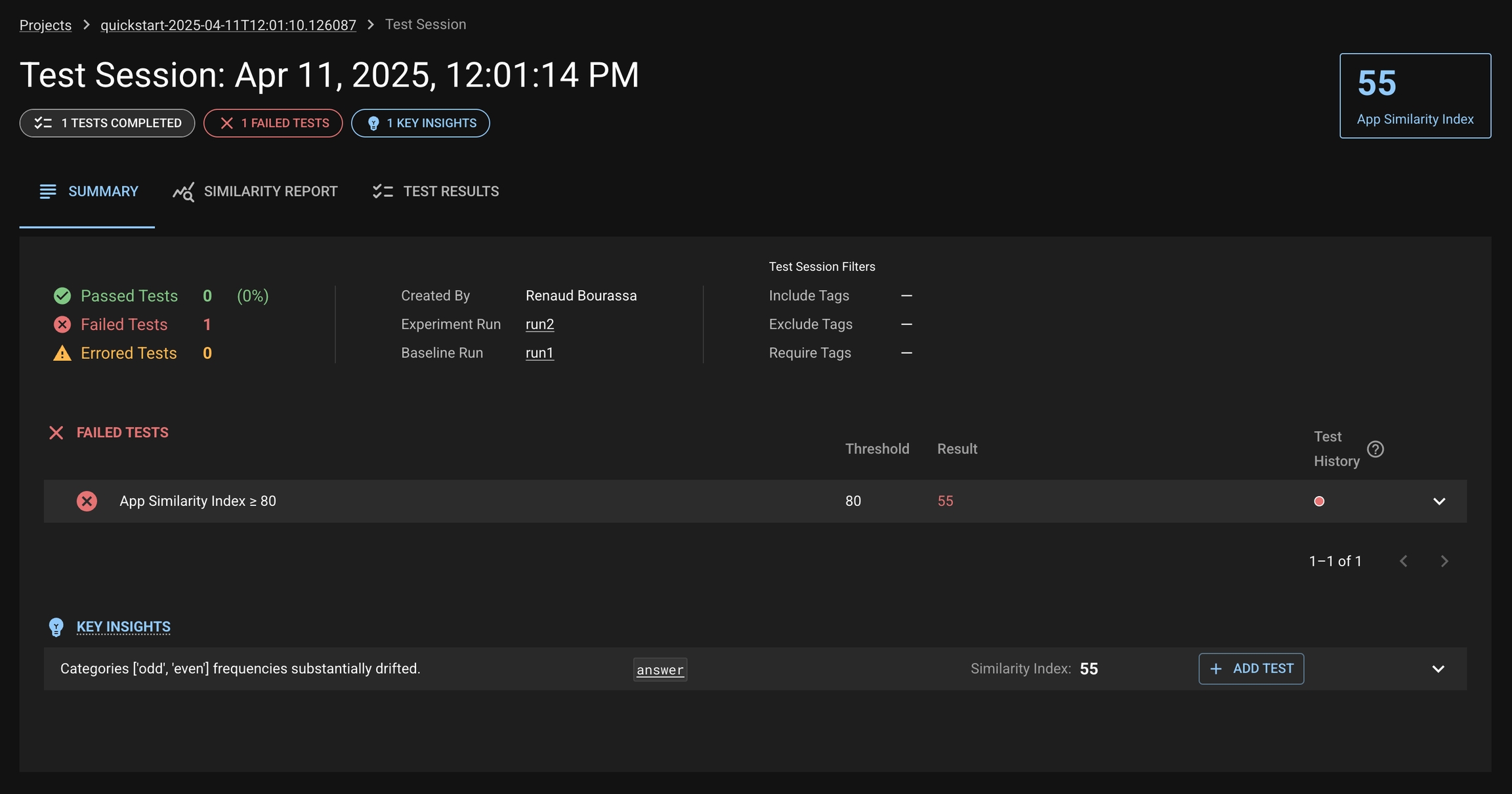
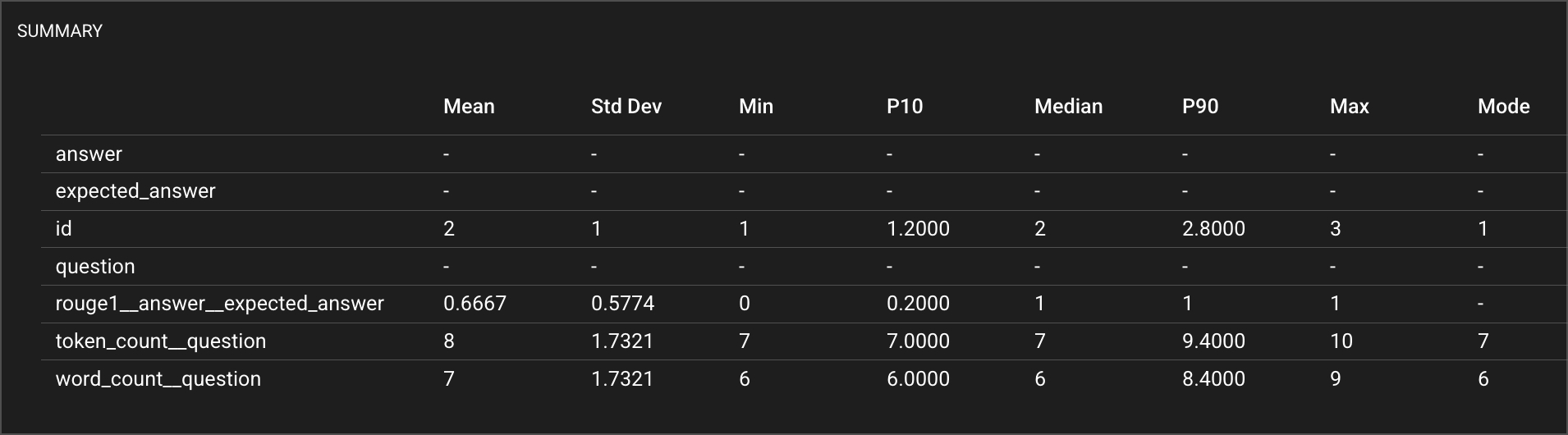
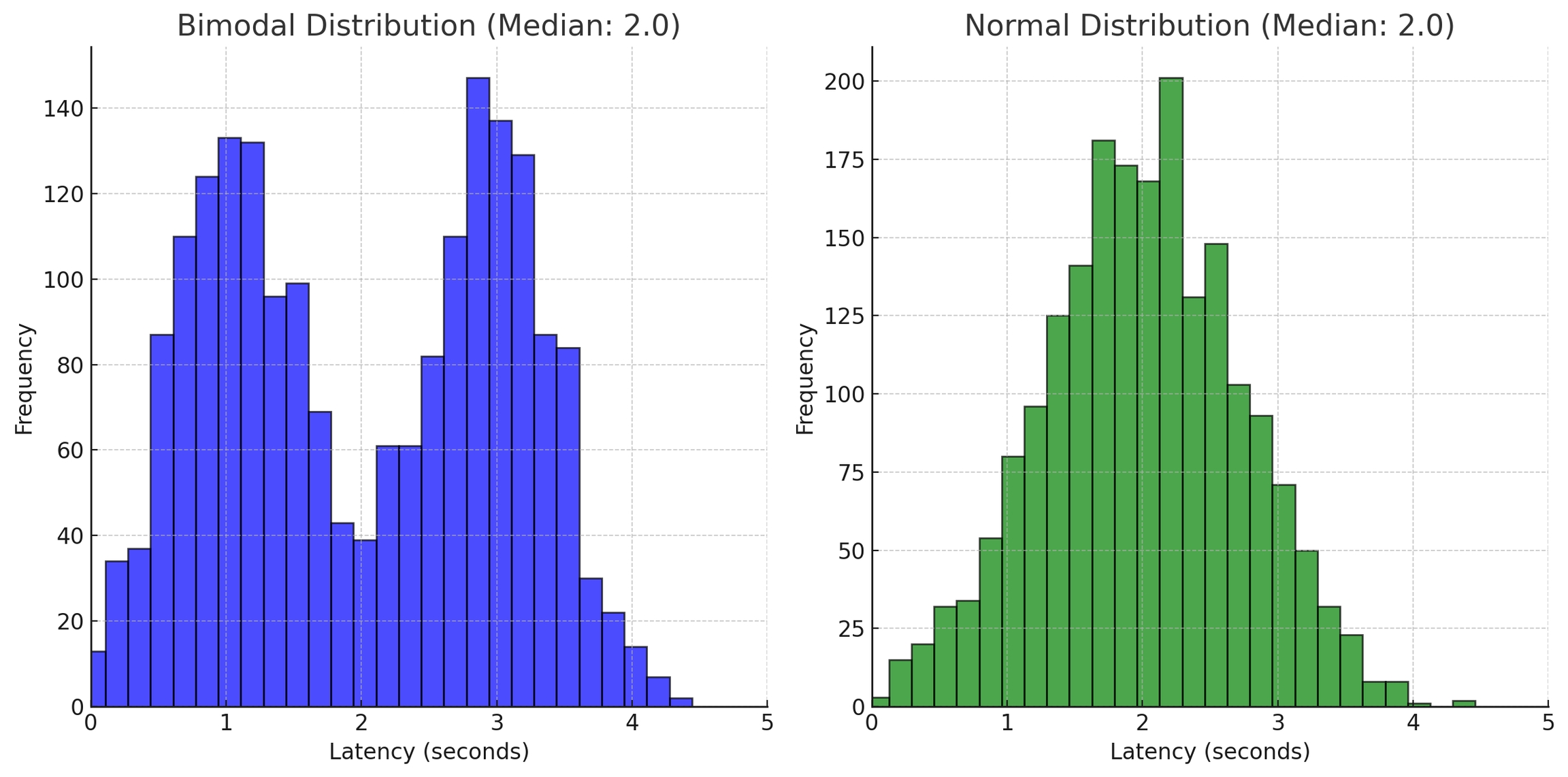
Create a client to power LLM-as-judge text metrics [optional]
Generate a list of metrics suitable for comparing text_A to reference text_B
Use dbnl.eval to evaluate to compute the list metrics.
Publish the augmented dataframe and new metric quantities to DBNL
You can inspect a subset of the the aug_eval_df rows and for example, one of the columns created by one of the metrics in the text_metrics list : llm_text_similarity_v0
0
France has no capital
The capital of France is Paris
1
1
The capital of France is Toronto
The capital of France is Paris
1
2
Paris is the capital
The capital of France is Paris
5
The values of llm_text_similarity_v0qualitatively match our expectations on semantic similarity between the prediction and ground_truth
The column names of the metrics in the returned dataframe include the metric name and the columns that were used in that metrics computation
For example the metric named llm_text_similarity_v0 becomes llm_text_similarity_v0__prediction__ground_truth because it takes as input both the column named prediction and the column named ground_truth
No problem, just don’t include an eval_llm_client or an eval_embedding_client argument in the call(s) to the evaluation helpers. The helpers will automatically exclude any metrics that depend on them.
No problem. You can simply remove the target argument from the helper. The metric set helper will automatically exclude any metrics that depend on the target column being specified.
There is an additional helper that can generate a list of generic metrics appropriate for “monitoring” unstructured text columns : text_monitor_metrics(). Simply provide a list of text column names and optionally an eval_llm_client for LLM-as-judge metrics.
You can write your own LLM-as-judge metric that uses your custom prompt. The example below defines a custom LLM-as-judge metric and runs it on an example dataframe.
You can also write a metric that includes only the prediction column specified and reference only {prediction} in the custom prompt. An example is below:
In RAG (retrieval-augmented generation or "question and answer") applications, the high level goal is:
Given a question, generate an answer that adheres to knowledge in some corpus
However, this is easier said than done. Data is often collected at various steps in the RAG process to help evaluate which steps might be performing poorly or not as expected. This data can help understand the following:
What question was asked?
Which documents / chunks (ids) were retrieved?
What was the text of those retrieved documents / chunks?
From the retrieved documents, what was the top-ranked document and its id?
What is the expected answer?
What is the expected document id and text that contains the answer to the question?
What was the generated answer?
Having data that answers some or all of these questions allows for evaluations to run, producing metrics that can highlight what part of the RAG system is performing in unexpected ways.
The short example below demonstrates what a dataframe with rich contextual data would look like for and how to use dbnl.eval to generate relevant metrics
You can inspect a subset of the the aug_eval_df rows and examine, for example, the metrics related to retrieval and answer similarity
We can see the first result (idx = 0) represents a complete failure of the RAG system. The relevant documents were not retrieved (mrr = 0.0) and the generated answer is very dissimilar from the expected answer (answer_similarity = 1).
The second result (idx = 1) represents a better response from the RAG system. The relevant document was retrieved, but ranked lower (mrr = 0.33333) and the answer is somewhat similar to the expected answer (answer_similarity = 3)
The final result (idx = 2) represents a strong response from the RAG system. The relevant document was retrieved and top ranked (mrr = 1.0) and the generated answer is very similar to the expected answer (answer_similarity = 5)
The signature for question_and_answer_metrics() highlights its adaptability. Again, the optional arguments are not required and the helper will intelligently return only the metrics that depend on the info that is provided.
To use dbnl.eval, you will need to install the extra 'eval' package as described in .
The call to takes a dataframe and metric list as input and returns a dataframe with extra columns. Each new column holds the value of a metric computation for that row
0
0.0
1
1
0.33333
3
2
1.0
5
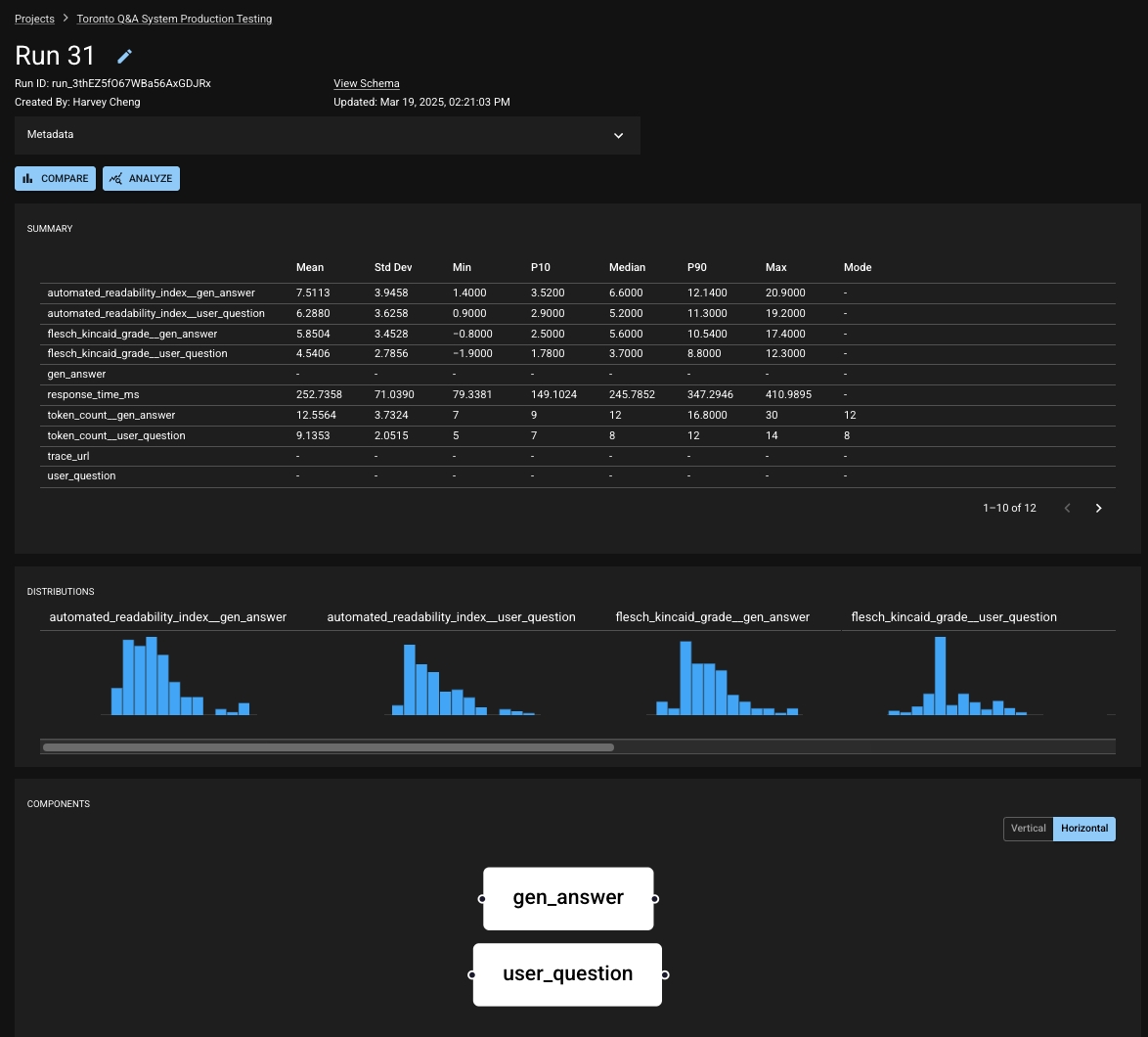


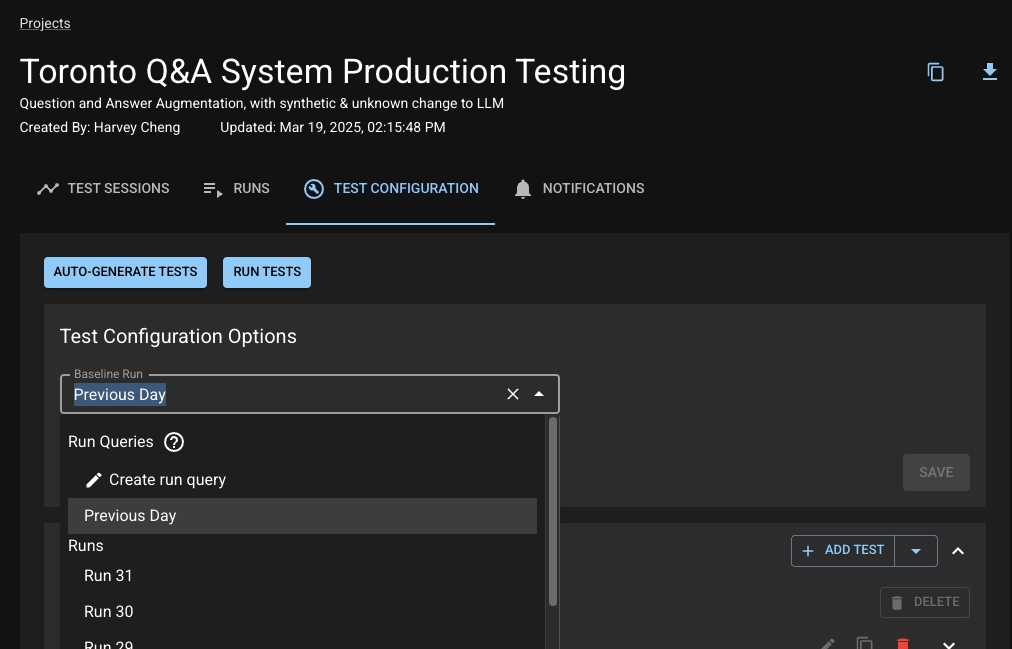
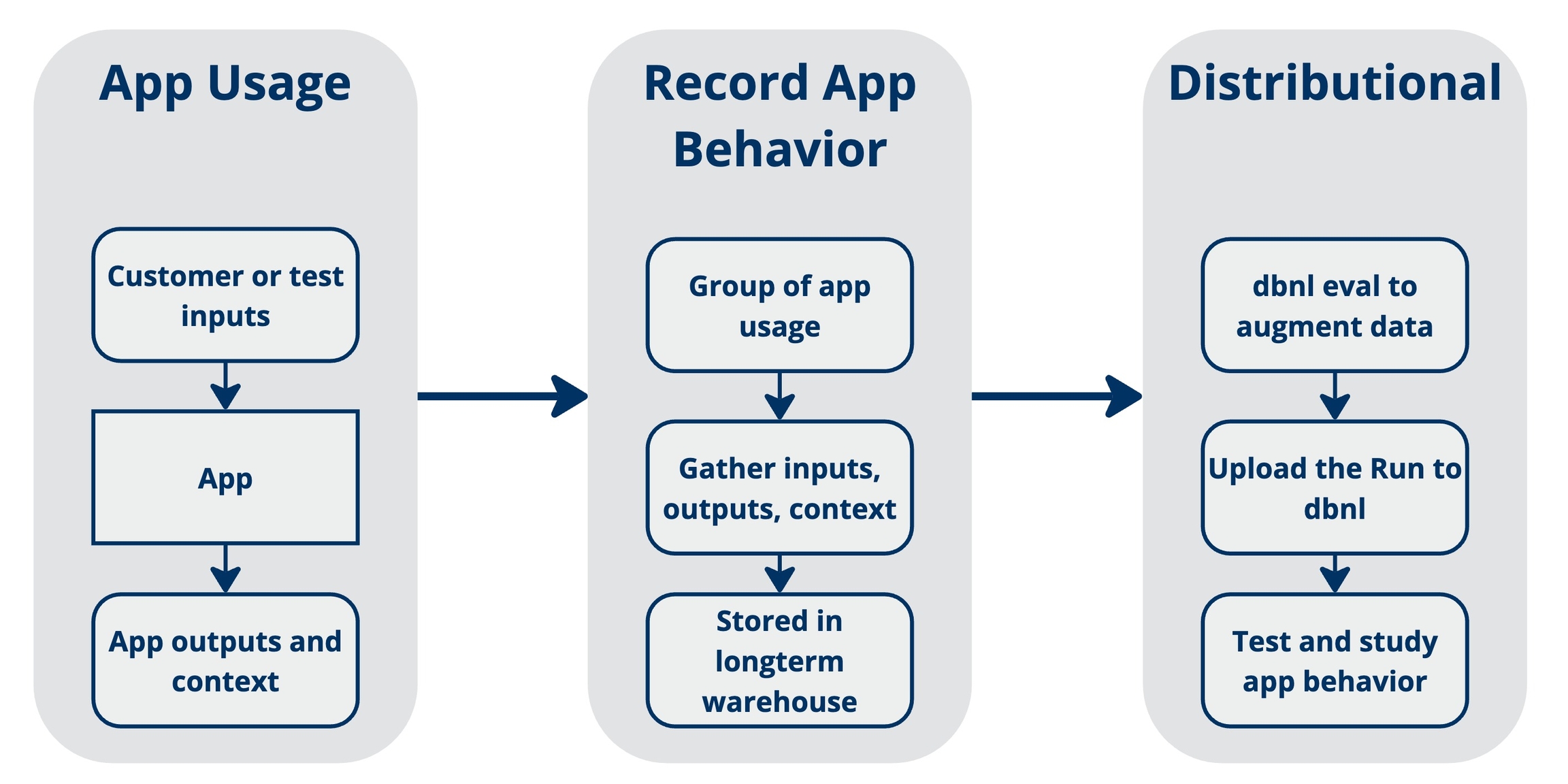
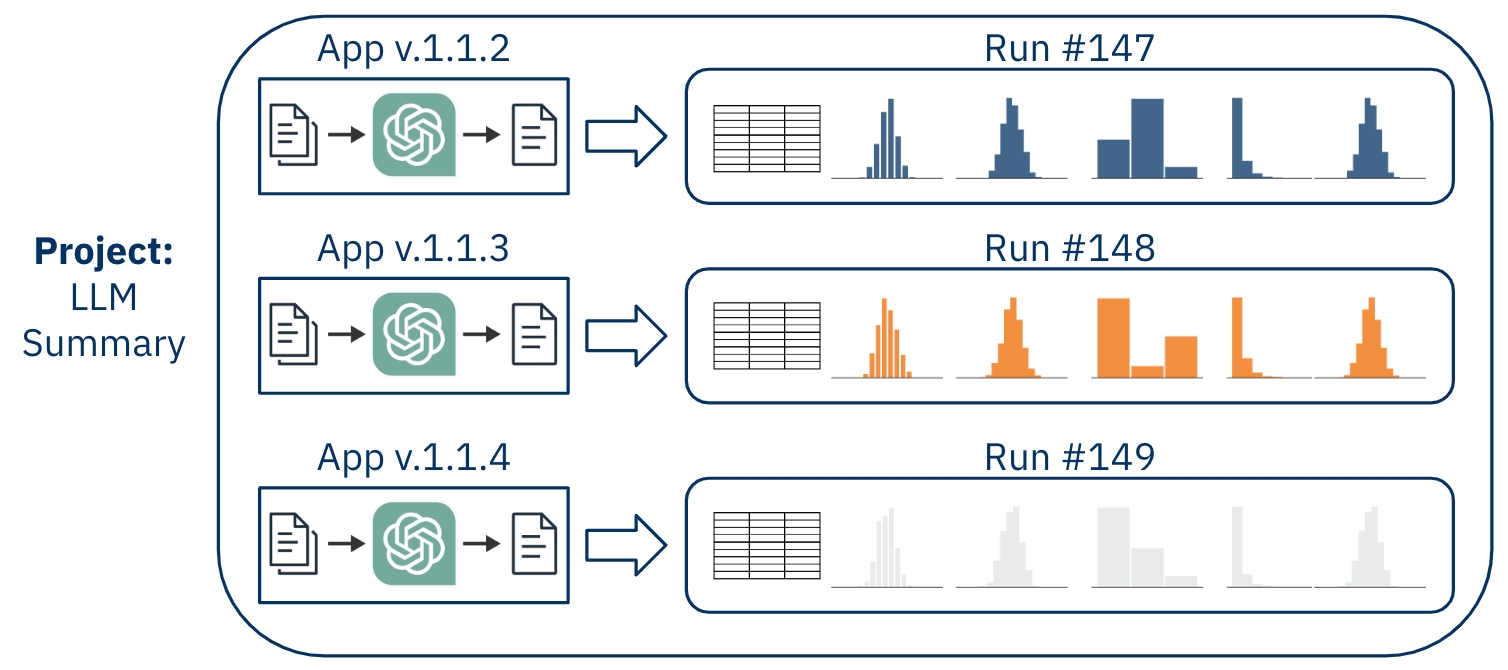
Similarity Index: Added initial computation, Likert scale support, history charts, test creation, and UI enhancements.
Metrics System: Introduced metric APIs, creation forms, and computation jobs
UI/UX:
Key Insights and summary detail view improvements
Summary chips, tooltips, sortable tables
Various UI and UX improvements, including column metrics pages and test creation shortcuts
Schema & Typing:
Parametrized type handling in UI
Improved type system: to_json_value, nullability, JSON unnesting
Schema unification
Helm & Dependency Management:
Updated helm charts and lock files
Repinned/upgraded Python and JS dependencies (e.g., alembic, ruff, identify)
UI/UX:
Improved Summary Tab and Test Session views
Fixed overlay defaults, sorted metrics table, and chart tooltips
Responsive layout tweaks and consistent styling
General improvements:
Code quality, cleanup (deprecated / legacy code), and improved organization
UI/UX: Fixed navigation issues, loading states, pagination, and flaky links.
Infrastructure: Resolved Helm/chart/tagging issues, GitHub Actions bugs, and sandbox setup problems.
Testing: Addressed test failures and integration test inconsistencies.
RunConfig or RunSchema for Runs (defaults to RunSchema on infer)
Integrated metrics into the RunSchema object
RunConfigdeprecated for future releases
Enabled metric creation and deletion
Added wait_for_run_close utility (now default behavior)
Improved command-line feedback and error handling (e.g., Docker not running)
Removed support for legacy types and deprecated DBNL_API_HOST
Adjusted version bounds for numpy and spacy
Fixed multiple issues with publishing wheels and builds
Improved SDK integration tests (including wait_for_close)
Cleaned up comments and enhanced docstrings
This patch release adds a critical bug fix to the sandbox authentication flow.
Fix a bug with the sandbox authentication flow that resulted in credentials being considered invalid
This release adds a sandbox environment with the dbnl platform which can be deployed to a single machine. Contact us for access!
New Sandbox deployment option
Support for RunSchema on Run creation in the API
Add install option to set dev tokens expiration policy
Link to versioned documentation from the UI
Terms of service updates
Remove link to "View Test Analysis" page
[UI] Only allow closed runs when selecting a default run for comparison in UI
[UI] Allow selecting more than 10 columns in test session summary page
[SDK] Fixed default namespace in URL for project upon get_or_create
New SDK CLI interface
Changes in minimum and maximum versions for some libraries (pyarrow, numpy, spacy)
This release adds a number of new features, improvements, and bug fixes.
New Test History feature in Test Spec detail page that enables users to understand a single tests' behavior over time, including its recalibration history
Added support for Slack notifications in UI
Close runs in the UI
Viewable dbnl version in sidebar
UI performance improvements
Update color of links
Preserve input expressions in test spec editor
Extend scope of Project export
Export Tags by name for Project export
Better error messages for Project import
Improve namespace support for multi-org users
Miscellaneous package updates
Validate results on run close
/projects redirects to home page
Fix broken pagination
Fix broken Histogram title
Fix Results Table rendering issue for some Tests
Fix support for decimal values in assertion params
Fix rendering of = and != Assertions
Test spec editor navigation bugfix
Check compatibility with API version
Add support for double and long values
Improved errors for invalid API URL configuration
Remove en-core-web-sm from requirements to enable PyPI support
Updated helm-charts for on-prem
Highlights in this version:
Improvements to the project import/export feature including support for notifications.
Support for new versioning and release process.
Better dependency management.
Too many bug fixes and UX improvements to list in detail.
This release includes several new features that allow users to more easily view and diagnose behavioral shifts in their test sessions. Check out , our way of quantifying drift, and create new tests based on the key insights we surface!