Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Functions that interact with a dbnl Project
Click through to view all the SDK functions.
Below is a basic working example that highlights the SDK workflow. If you have not yet installed the SDK, follow these instructions.
The primary mechanism for submitting data to Distributional is through our Python SDK. This section contains information about how to set up the SDK and use it for your AI testing purposes.
The name for the dbnl . Project names must be unique; an error will be raised if there exists a Project with the same name.
Functions related to dbnl RunConfig
Functions related to Column and Scalar data uploaded within a Run.
As a convenience for reporting results and creating a Run, you can also check out report_run_with_results
Retrieve the specified dbnl Project or create a new one if it does not exist
name
description
An optional description for the dbnl Project, defaults to None. Description is limited to 255 characters.
Description cannot be updated with this function.
A new Project will be created with the specified name if there does not exist a Project with this name already. If there does exist a project with the name, the pre-existing Project will be returned.
Create a new dbnl RunConfig
project
columns
A list of column schema specs for the uploaded data, required keys name and type, optional key component, description and greater_is_better. type can be int, float, category, boolean, or string. component is a string that indicates the source of the data. e.g. "component" : "sentiment-classifier" or "component" : "fraud-predictor". Specified components must be present in the components_dag dictionary. greater_is_better is a boolean that indicates if larger values are better than smaller ones. False indicates smaller values are better. None indicates no preference.
Example:
columns=[{"name": "pred_proba", "type": "float", "component": "fraud-predictor"}, {"name": "decision", "type": "boolean", "component": "threshold-decision"}, {"name": "requests", "type": "string", "description": "curl request response msg"}]
scalars
NOTE: scalars is available in SDK v0.0.15 and above.
A list of scalar schema specs for the uploaded data, required keys name and type, optional key component, description and greater_is_better. type can be int, float, category, boolean, or string. component is a string that indicates the source of the data. e.g. "component" : "sentiment-classifier" or "component" : "fraud-predictor". Specified components must be present in the components_dag dictionary. greater_is_better is a boolean that indicates if larger values are better than smaller ones. False indicates smaller values are better. None indicates no preference. An example RunConfig scalars: scalars=[{"name": "accuracy", "type": "float", "component": "fraud-predictor"}, {"name": "error_type", "type": "category"}]
Scalar schema is identical to column schema.
description
An optional description of the RunConfig, defaults to None. Descriptions are limited to 255 characters.
display_name
An optional display name of the RunConfig, defaults to None. Display names do not have to be unique.
row_id
An optional list of the column names that can be used as unique identifiers, defaults to None.
components_dag
Column names can only be alphanumeric characters and underscores.
The following type supported as type in column schema
float
int
boolean
string
Any arbitrary string values. Raw string type columns do not produce any histogram or scatterplot on the web UI.
category
list
Currently only supports list of string values. List type columns do not produce any histogram or scatterplot on the web UI.
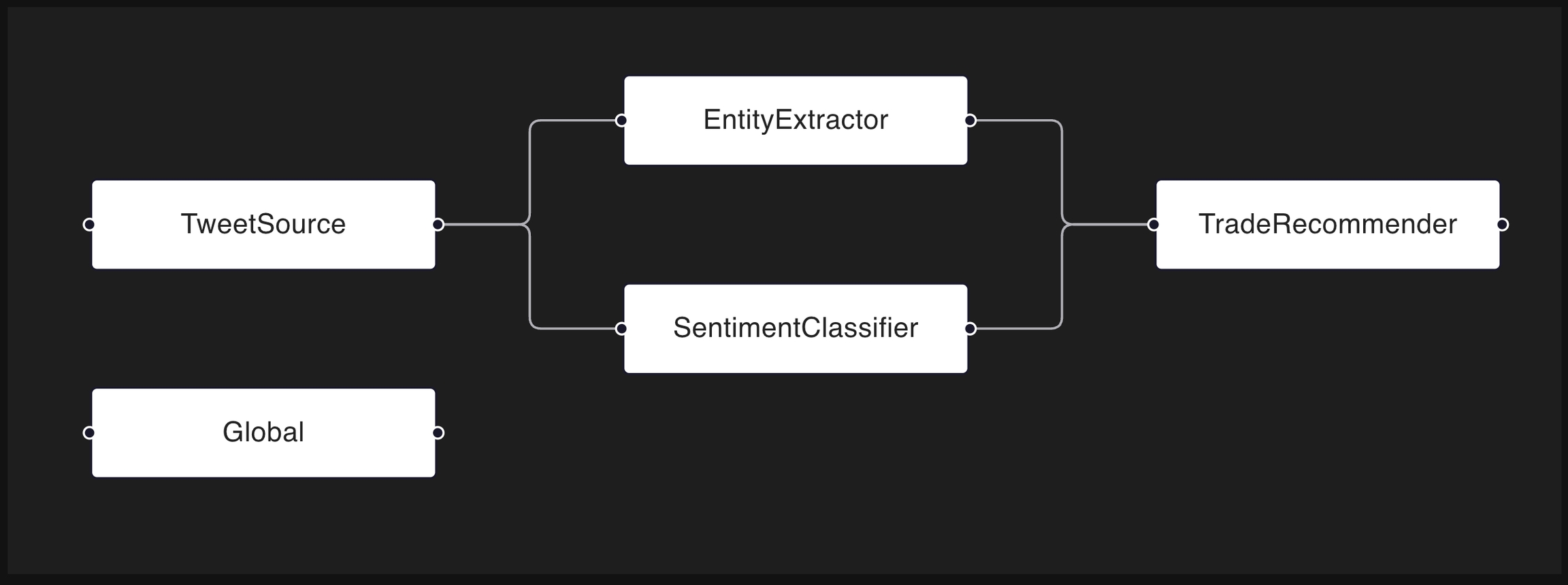
The optional component key is for specifying the source of the data column in relationship to the AI/ML app subcomponents. Components are used in visualizing the components DAG.
The components_dag dictionary specifies the topological layout of the AI/ML app. For each key-value pair, the key represents the source component, and the value is a list of the leaf components. The following code snippet describes the DAG shown above.
A new dbnl RunConfig
RunConfig with scalars
Authenticate dbnl SDK
Setup dbnl SDK to make authenticated requests. After login is run successfully, the dbnl client will be able to issue secure and authenticated requests against hosted endpoints of the dbnl service.
dbnl.login must be run before any other functions in the DBNL workflow
api_token
namespace_id
Namespace ID to use for the session; available namespaces can be found with get_my_namespaces().
api_url
The base url of the Distributional API. For SaaS users, set this variable to api.dbnl.com. For other users, please contact your sys admin.
app_url
An optional base url of the Distributional app. If this variable is not set, the app url is inferred from the DBNL_API_URL variable. For on-prem users, please contact your sys admin if you cannot reach the Distributional UI.
Retrieve results from dbnl
run
pandas.DataFrame
You can only call get_column_results after the run is closed.
Retrieve results from dbnl
run
ResultData
You can only call get_results after the run is closed.
Report all scalar results to dbnl
Report all column results to dbnl
Report all results to dbnl
report_results is the equivalent of calling both report_column_results and report_scalar_results .
All data should be reported to dbnl at once. Calling dbnl.report_results more than once will overwrite the previously uploaded data.
Once a Run is . You can no longer call report_results to send data to DBNL.
Functions interacting with dbnl
The to export as json.
The name for the dbnl . A new Project will be created with this name if there does not exist a Project with this name already. If there does exist a project with this name, the pre-existing Project will be returned.
JSON object representing the Project, generally based on a exported via . Example:
The this RunConfig is associated with.
The the most recent Run is associated with.
The ID of the dbnl . RunConfig ID starts with the prefix runcfg_ . Run ID can be found at the Run detail page or Project detail page. An error will be raised if there does not exist a RunConfig with the given run_config_id.
The this RunConfig is associated with.
See the section below for more information.
An optional dictionary representing the direct acyclic graph (DAG) of the specified components, defaults to None. Every component listed in the columns schema must be present in the components_dag. Example: components_dag={"fraud-predictor": ["threshold-decision"], 'threshold-decision': []}
See the section below for more information.
Equivalent of pandas . Currently only supports category of string values.
The API token used to authenticate your DBNL account. You can generate your API token at (also, see ). If none is provided, theDBNL_API_TOKEN will be used by default.
The name for the existing dbnl . An error will be raised if there is no Project with the given name.
The dbnl from which to retrieve the results.
A of the data for the particular Run.
The dbnl from which to retrieve the results.
A named tuple that comprises of columns and scalars fields. These are the s of the data for the particular Run.
project
The Project to copy.
name
The name for the new dbnl Project. Project names must be unique; an error will be raised if there exists a Project with the same name.
description
An optional description for the dbnl Project, defaults to None. Description is limited to 255 characters.
The newly created dbnl Project.
run_id
The ID of the dbnl Run. Run ID starts with the prefix run_ . Run ID can be found at the Run detail page. An error will be raised if there does not exist a Run with the given run_id.
The dbnl Run with the given ID.
project
The dbnl Project that this Run will be associated with.
column_data
A pandas DataFrame with all the column results to report to dbnl. If run_config_id is provided, the columns of the DataFrame must match the columns described in the RunConfig.
scalar_data
A dict or pandas DataFrame with all the scalar results to report to dbnl. If run_config_id is provided, the key of the dict must match the scalars described in the RunConfig.
display_name
An optional display name for the Run. Display names do not have to be unique.
row_id
An optional list of the column names that can be used as unique identifiers.
run_config_id
ID of the RunConfig to use for the Run, defaults to None. If provided, the RunConfig is used as is and the results are validated against it. If not provided, a new Run Config is inferred from the column_data.
metadata
Any additional key-value pairs information the user wants to track.
The closed Run with the uploaded data.
project
The dbnl Project that this Run will be associated with.
run_config
The dbnl RunConfig that this Run will be associated with. Two Runs with the same RunConfig can be compared in the web UI and associated in Tests. The associated RunConfig must be from the same Project.
display_name
An optional display name for the Run. Display names do not have to be unique.
metadata
Any additional key-value pairs information the user wants to track.
A new dbnl Run for reporting results.
run
The dbnl Run that the results will be reported to.
data
A dict or a single-row pandas DataFrame with all the scalar values to report to dbnl.
run
The dbnl Run from which to retrieve the results.
pandas.DataFrame
A pandas DataFrame of the uploaded scalar data for the particular Run.
run
The dbnl Run that the results will be reported to.
data
A pandas DataFrame with all the results to report to dbnl. The columns of the DataFrame must match the columns described in the RunConfig associated with the Run.
run
The DBNL Run that the results will be reported to.
column_data
A pandas DataFrame with all the column results to report to DBNL. The columns of the DataFrame must match the columns described in the RunConfig associated with the Run.
scalar_data
A dict or pandas Dataframe with all the scalar results to report to DBNL. The key of the dict must match the scalars described in the RunConfig associated with the Run.
run
The dbnl Run to be finalized.
Functions that interact with dbnl TestSession
Functions that interact with dbnl Baseline concept
Create a TestSession
Start evaluating Tests associated with a Run. Typically, the Run you just completed will be the "Experiment" and you'll compare it to some earlier "Baseline Run".
The Run must already have and be closed before a Test Session can begin.
A Run must be closed for all to be shown on the UI.
Suppose we have the following Tests with the associated Tags in our Project
Test1 with tags ["A", "B"]
Test2 with tags ["A"]
Test3 with tags ["B"]
dbnl.create_test_session(..., include_tags=["A", "B"]) will trigger Tests 1, 2, 3 to be executed.
dbnl.create_test_session(..., require_tags=["A", "B"]) will only trigger Test 1.
dbnl.create_test_session(..., exclude_tags=["A"]) will trigger Test 3.
dbnl.create_test_session(..., include_tags=["A"], exclude_tags=["B"]) will trigger Test 2.
The dbnl this will be associated with
A new dbnl RunQuery, typically used for finding a for a Test Session
id
str
The ID of the RunConfig. RunConfig ID starts with the prefix runcfg_
project_id
str
The ID of the Project this RunConfig is associated with.
columns
list[dict[str, str]]
A list of column schema specs for the uploaded data, required keys name and type, optional key component and description. Example:
columns=[{"name": "pred_proba", "type": "float", "component": "fraud-predictor"}, {"name": "decision", "type": "boolean", "component": "threshold-decision"}, {"name": "requests", "type": "string", "description": "curl request response msg"}]
See the column schema section on the dbnl.create_run_config page for more information.
scalars
list[dict[str, str]]
An optional list of scalar schema specs for the uploaded scalar data, required keys name and type, optional key component, description and greater_is_better. type can be int, float, category, boolean, or string. component is a string that indicates the source of the data. e.g. "component" : "sentiment-classifier" or "component" : "fraud-predictor". Specified components must be present in the components_dag dictionary. greater_is_better is a boolean that indicates if larger values are better than smaller ones. False indicates smaller values are better. None indicates no preference. An example RunConfig scalars: scalars=[{"name": "accuracy", "type": "float", "component": "fraud-predictor"}, {"name": "error_type", "type": "category"}]
Scalar schema is identical to column schema.
description
str
An optional description of the RunConfig. Descriptions are limited to 255 characters.
display_name
str
An optional display name of the RunConfig.
row_id
list[str]
An optional list of the column names that are used as unique identifiers.
components_dag
dict[str, list[str]]
An optional dictionary representing the direct acyclic graph (DAG) of the specified components. Every component listed in the columns schema is present incomponents_dag.
test_spec_dict
A dictionary of the expected Test Spec schema
Dict[str, Any]
The JSON dict of the created Test Spec object. The return JSON will contain the id of the Test Spec.
id
str
The ID of the Run. Run ID starts with the prefix run_
project_id
str
The ID of the Project this Run is associated with.
run_config_id
str
The ID of the RunConfig this Run is associated with. Runs with the same RunConfig can be compared in the UI.
display_name
str
An optional display name of the Run.
metadata
Dict[str, str]
Any additional key-value pairs information the user wants to track.
run_config
The RunConfig associated with this Run object.
id
str
The ID of the Project. Project ID starts with the prefix proj_
name
str
The name of the Project. Project names have to be unique.
description
str
An optional description of the Project. Descriptions are limited to 255 characters.
id
str
The ID of the Run. Run ID starts with the prefix run_
project_id
str
The ID of the Project this RunQuery is associated with.
name
str
The name of the RunQuery.
query
dict[str, Any]
The dbnl RunQuery, typically used for finding a Dynamic Baselinefor a Test Session
experiment_run
The dbnl Run to create the TestSession for.
baseline
include_tags
An optional list of Test Tags to be included. All Tests with any of the tags in this list will be ran after the run is complete.
exclude_tags
An optional list of Test Tags to be excluded. All Tests with any of the tags in this list will be skipped after the run is complete.
require_tags
An optional list of Test Tags that are required. Only tests with all the tags in this list will be ran after the run is complete.
SDK experimental functions are in early development and are not fully tested. These functions are light-weight wrappers of the API endpoints, and are mostly interacting via JSONs/dicts.
Function names and signature are expected to be changed when they are elevated to standard SDK functions in the future.
Many generative AI applications focus on text generation. It can be challenging to create metrics for insights into expected performance when dealing with unstructured text.
dbnl.eval is a special module designed for evaluating unstructured text. This module currently includes:
Adaptive metric sets for generic text and RAG applications
12+ simple statistical local library powered text metrics
15+ LLM-as-judge and embedding powered text metrics
Support for user-defined custom LLM-as-judge metrics
LLM-as-judge metrics compatible with OpenAI, Azure OpenAI
Building dbnl tests on these evaluation metrics can then drive rich insights into an AI application's stability and performance.
If a TestSession has completed and some of the generated Tests had incorrect outcomes, you can tell Distributional that these tests should have had different results.
Only applies to Tests generated by Distributional, not custom, user-defined Tests.
test_session
The TestSession the user wants to recalibrate
feedback
either "PASS" or "FAIL", to redefine the Test outcomes.
test_ids
List of Tests to apply the feedback to. If None, then all generated Tests will be set with the given feedback.
TestRecalibrationSession
If some generated Tests failed when they should have passed, and some passed when they should have failed, the user will need to submit 2 separate calls, for each feedback result.
Retrieve the completed TestSession
test_session
The dbnl to wait for completion.
timeout_s
An optional timeout (in seconds) parameter for waiting for the TestSession to complete. An exception will be raised if the TestSession did not complete before timeout_s has elapsed.
TestSession
The completed TestSession
test_recalibration_session
The dbnl to wait for completion.
timeout_s
An optional timeout (in seconds) parameter for waiting for the TestRecalibrationSession to complete. An exception will be raised if the TestRecalibrationSession did not complete before timeout_s has elapsed.
TestRecalibrationSession
The completed TestRecalibrationSession
Formats an incomplete Test Spec JSON
If a TestSession has completed and some of the generated Tests had incorrect outcomes, you can tell Distributional that these tests should have had different results.
Only applies to Tests generated by Distributional, not custom Tests
The following 2 examples are equivalent:
To generate tests for all columns, leave columns out:
To use dbnl.eval, you will need to install the extra 'eval' package as described in .
Create a client to power LLM-as-judge text metrics [optional]
Generate a list of metrics suitable for comparing text_A to reference text_B
Use dbnl.eval to evaluate to compute the list metrics.
Publish the augmented dataframe and new metric quantities to DBNL
You can inspect a subset of the the aug_eval_df rows and for example, one of the columns created by one of the metrics in the text_metrics list : llm_text_similarity_v0
The values of llm_text_similarity_v0qualitatively match our expectations on semantic similarity between the prediction and ground_truth
The column names of the metrics in the returned dataframe include the metric name and the columns that were used in that metrics computation
For example the metric named llm_text_similarity_v0 becomes llm_text_similarity_v0__prediction__ground_truth because it takes as input both the column named prediction and the column named ground_truth
The object that was created. The status can be checked to determine when recalibration is complete.
The call to takes a dataframe and metric list as input and returns a dataframe with extra columns. Each new column holds the value of a metric computation for that row
run
The Run to use when generating tests.
columns
Either a list of column names or a list of dictionaries with only 1 key, "name". These names must refer to the columns in the Run that dbnl will use to generate Tests. If None, then all columns in the Run will be used.
TestGenerationSession
The TestGenerationSession object that was created. The status can be checked to determine when test generation is complete.
0
France has no capital
The capital of France is Paris
1
1
The capital of France is Toronto
The capital of France is Paris
1
2
Paris is the capital
The capital of France is Paris
5
The metric set helpers return an adaptive list of metrics, relevant to the application type
text_metrics()Basic metrics for generic text comparison and monitoring
question_and_answer_metrics()Basic metrics for RAG / question answering
The metric set helpers are adaptive in that :
The metrics returned encode which columns of the dataframe are input to the metric computation
e.g., rougeL_prediction__ground_truth is the rougeL metric run with both the column named prediction and the column named ground_truth as input
The metrics returned support any additional optional column info and LLM-as-judge or embedding model clients. If any of this optional info is not provided, the metric set will exclude any metrics that depend on that information
See the How-To section for concrete examples of adaptive text_metrics() usage
See the RAG example for question_and_answer_metrics() usage
eval.metrics
Retrieve the specified dbnl Test Tag or create a new one if it does not exist
project_id
The dbnl Project that this Test Tag is associated with.
name
The name of the Test Tag to be retrieved. If a Tag with the name does not exist, it will create a new Tag. Tag names must be unique.
description
An optional description for the Tag. Descriptions are limited to 255 characters.
Dict[str, Any]
Test Tag JSON
Functions in the dbnl.eval module.
Evaluates a set of metrics on a dataframe, returning an augmented dataframe.
Parameters:
df – input dataframe
metrics – metrics to compute
inplace – whether to modify the input dataframe in place
Returns: input dataframe augmented with metrics
Get the run config column schemas for a dataframe that was augmented with a list of metrics.
Parameters:
df – Dataframe to get column schemas from
metrics – list of metrics added to the dataframe
Returns: list of columns schemas for dataframe and metrics
Get the run config column schemas from a list of metrics.
Parameters: metrics – list of metrics to get column schemas from
Returns: list of column schemas for metrics
No problem, just don’t include an eval_llm_client or an eval_embedding_client argument in the call(s) to the evaluation helpers. The helpers will automatically exclude any metrics that depend on them.
No problem. You can simply remove the target argument from the helper. The metric set helper will automatically exclude any metrics that depend on the target column being specified.
There is an additional helper that can generate a list of generic metrics appropriate for “monitoring” unstructured text columns : text_monitor_metrics(). Simply provide a list of text column names and optionally an eval_llm_client for LLM-as-judge metrics.
You can write your own LLM-as-judge metric that uses your custom prompt. The example below defines a custom LLM-as-judge metric and runs it on an example dataframe.
You can also write a metric that includes only the prediction column specified and reference only {prediction} in the custom prompt. An example is below:
In RAG (retrieval-augmented generation or "question and answer") applications, the high level goal is:
Given a question, generate an answer that adheres to knowledge in some corpus
However, this is easier said than done. Data is often collected at various steps in the RAG process to help evaluate which steps might be performing poorly or not as expected. This data can help understand the following:
What question was asked?
Which documents / chunks (ids) were retrieved?
What was the text of those retrieved documents / chunks?
From the retrieved documents, what was the top-ranked document and its id?
What is the expected answer?
What is the expected document id and text that contains the answer to the question?
What was the generated answer?
Having data that answers some or all of these questions allows for evaluations to run, producing metrics that can highlight what part of the RAG system is performing in unexpected ways.
The short example below demonstrates what a dataframe with rich contextual data would look like for and how to use dbnl.eval to generate relevant metrics
You can inspect a subset of the the aug_eval_df rows and examine, for example, the metrics related to retrieval and answer similarity
We can see the first result (idx = 0) represents a complete failure of the RAG system. The relevant documents were not retrieved (mrr = 0.0) and the generated answer is very dissimilar from the expected answer (answer_similarity = 1).
The second result (idx = 1) represents a better response from the RAG system. The relevant document was retrieved, but ranked lower (mrr = 0.33333) and the answer is somewhat similar to the expected answer (answer_similarity = 3)
The final result (idx = 2) represents a strong response from the RAG system. The relevant document was retrieved and top ranked (mrr = 1.0) and the generated answer is very similar to the expected answer (answer_similarity = 5)
The signature for question_and_answer_metrics() highlights its adaptability. Again, the optional arguments are not required and the helper will intelligently return only the metrics that depend on the info that is provided.
Wait for a Test Generation Session to finish
test_generation_session
The dbnl to wait for completion.
timeout_s
An optional timeout (in seconds) parameter for waiting for the TestGenerationSession to complete. An exception will be raised if the TestGenerationSession did not complete before timeout_s has elapsed.
TestGenerationSession
The completed TestGenerationSession
A common strategy for evaluating unstructured text application is to use other LLMs and text embedding models to drive metrics of interest.
The LLM-as-judge in dbnl.eval support OpenAI, Azure OpenAI and any other third-party LLM / embedding model provider that is compatible with the OpenAI python client. Specifically, third-party endpoints should (mostly) adhere to the schema of:
endpoint for LLMs
endpoint for embedding models
The following examples show how to initialize an llm_eval_client and an eval_embedding_client under different providers.
It is possible for some of the LLM-as-judge metrics to occasionally return values that are unable to be parsed. These metrics values will surface as None
Distributional is able to accept dataframes including None values. The platform will intelligently filter them when applicable.
LLM service providers often impose request rate limits and token throughput caps. Some example errors that one might encounter are shown below:
In the event you experience these errors, please work with your LLM service provider to adjust your limits. Additionally, feel free to reach out to Distributional support with the issue you are seeing.
0
0.0
1
1
0.33333
3
2
1.0
5
Classes and methods in dbnl.eval.metrics.
Returns the column schema for the metric to be used in a run config.
Returns: _description_
Return type: ColumnSchema
Returns the description of the metric.
Returns: Description of the metric.
Evaluates the metric over the provided dataframe.
Parameters: df – Input data from which to compute metric.
Returns: Metric values.
Returns the expression representing the metric (e.g. rouge1(prediction, target)).
Returns: Metric expression.
If true, larger values are assumed to be directionally better than smaller once. If false, smaller values are assumged to be directionally better than larger one. If None, assumes nothing.
Returns: True if greater is better, False if smaller is better, otherwise None.
Returns: Metric name (e.g. rouge1).
Returns the fully qualified name of the metric (e.g. rouge1__prediction__target).
Returns: Metric name.
Returns the type of the metric (e.g. float)
Returns: Metric type.
Computes the accuracy of the answer by evaluating the accuracy score of the answer using a language model.
This metric is generated by an LLM using a specific prompt named llm_accuracy available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
context – context column name
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: accuracy metric
Returns the answer correctness metric.
This metric is generated by an LLM using a specific prompt named llm_answer_correctness available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
prediction – prediction column name
target – target column name
eval_llm_client – eval LLM client
Returns: answer correctness metric
Returns answer similarity metric.
This metric is generated by an LLM using a specific prompt named llm_answer_similarity available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
prediction – prediction column name
target – target column name
eval_llm_client – eval_llm_client
Returns: answer similarity metric
Computes the coherence of the answer by evaluating the coherence score of the answer using a language model.
This metric is generated by an LLM using a specific prompt named llm_coherence available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: coherence metric
Computes the commital of the answer by evaluating the commital score of the answer using a language model.
This metric is generated by an LLM using a specific prompt named llm_commital available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: commital metric
Computes the completeness of the answer by evaluating the completeness score of the answer using a language model.
This metric is generated by an LLM using a specific prompt named llm_completeness available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
prediction – prediction column
eval_llm_client – eval_llm_client
Returns: completeness metric
Computes the contextual relevance of the answer by evaluating the contextual relevance score of the answer using a language model.
This metric is generated by an LLM using a specific prompt named llm_contextual_relevance available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
context – context column name
eval_llm_client – eval_llm_client
Returns: contextual relevance metric
Returns the faithfulness metric.
This metric is generated by an LLM using a specific prompt named llm_faithfulness available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
context – context column name
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: faithfulness metric
Computes the grammar accuracy of the answer by evaluating the grammar accuracy score of the answer using a language model.
This metric is generated by an LLM using a specific prompt named llm_grammar_accuracy available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: grammar accuracy metric
Returns a set of metrics which evaluate the quality of the generated answer. This does not include metrics that require a ground truth.
Parameters:
input – input column name (i.e. question)
prediction – prediction column name (i.e. generated answer)
context – context column name (i.e. document or set of documents retrieved)
eval_llm_client – eval_llm_client
Returns: list of metrics
Computes the originality of the answer by evaluating the originality score of the answer using a language model.
This metric is generated by an LLM using a specific prompt named llm_originality available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: originality metric
Returns relevance metric with context.
This metric is generated by an LLM using a specific prompt named llm_relevance available in dbnl.eval.metrics.prompts.
Parameters:
input – input column name
context – context column name
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: answer relevance metric with context
Returns a list of metrics relevant for a question and answer task.
Parameters:
prediction – prediction column name (i.e. generated answer)
eval_llm_client – eval_llm_client
Returns: list of metrics
Computes the reading complexity of the answer by evaluating the reading complexity score of the answer using a language model.
This metric is generated by an LLM using a specific prompt named llm_reading_complexity available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: reading complexity metric
Computes the sentiment of the answer by evaluating the sentiment assessment score of the answer using a language model.
This metric is generated by an LLM using a specific prompt named llm_sentiment_assessment available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: sentiment assessment metric
Computes the text fluency of the answer by evaluating the perplexity of the answer using a language model.
This metric is generated by an LLM using a specific prompt named llm_text_fluency available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: text fluency metric
Computes the toxicity of the answer by evaluating the toxicity score of the answer using a language model.
This metric is generated by an LLM using a specific prompt named llm_text_toxicity available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
eval_llm_client – eval_llm_client
Returns: toxicity metric
Returns the Automated Readability Index metric for the text_col_name column.
Calculates the Automated Readability Index (ARI) for a given text. ARI is a readability metric that estimates the U.S. school grade level necessary to understand the text, based on the number of characters per word and words per sentence.
Parameters: text_col_name – text column name
Returns: automated_readability_index metric:
Returns the bleu metric between the prediction and target columns.
The BLEU score is a metric for evaluating a generated sentence to a reference sentence. The BLEU score is a number between 0 and 1, where 1 means that the generated sentence is identical to the reference sentence.
Parameters:
prediction – prediction column name
target – target column name
Returns: bleu metric
Returns the character count metric for the text_col_name column.
Parameters: text_col_name – text column name
Returns: character_count metric
Returns the context hit metric.
This boolean-valued metric is used to evaluate whether the ground truth document is present in the list of retrieved documents. The context hit metric is 1 if the ground truth document is present in the list of retrieved documents, and 0 otherwise.
Parameters:
ground_truth_document_id – ground_truth_document_id column name
retrieved_document_ids – retrieved_document_ids column name
Returns: context hit metric
Returns a set of metrics relevant for a question and answer task.
Parameters: text_col_name – text column name
Returns: list of metrics
Returns the Flesch-Kincaid Grade metric for the text_col_name column.
Calculates the Flesch-Kincaid Grade Level for a given text. The Flesch-Kincaid Grade Level is a readability metric that estimates the U.S. school grade level required to understand the text. It is based on the average number of syllables per word and words per sentence.
Parameters: text_col_name – text column name
Returns: flesch_kincaid_grade metric
Returns a set of metrics relevant for a question and answer task.
Parameters:
prediction – prediction column name (i.e. generated answer)
target – target column name (i.e. expected answer)
Returns: list of metrics
Returns a set of metrics relevant for a question and answer task.
Parameters:
ground_truth_document_id – ground_truth_document_id column name
retrieved_document_ids – retrieved_document_ids column name
Returns: list of metrics
Returns the inner product metric between the ground_truth_document_text and top_retrieved_document_text columns.
This metric is used to evaluate the similarity between the ground truth document and the top retrieved document using the inner product of their embeddings. The embedding client is used to retrieve the embeddings for the ground truth document and the top retrieved document. An embedding is a high-dimensional vector representation of a string of text.
Parameters:
ground_truth_document_text – ground_truth_document_text column name
top_retrieved_document_text – top_retrieved_document_text column name
embedding_client – embedding client
Returns: inner product metric
Returns the inner product metric between the prediction and target columns.
This metric is used to evaluate the similarity between the prediction and target columns using the inner product of their embeddings. The embedding client is used to retrieve the embeddings for the prediction and target columns. An embedding is a high-dimensional vector representation of a string of text.
Parameters:
prediction – prediction column name
target – target column name
embedding_client – embedding client
Returns: inner product metric
Returns the levenshtein metric between the prediction and target columns.
The Levenshtein distance is a metric for evaluating the similarity between two strings. The Levenshtein distance is an integer value, where 0 means that the two strings are identical, and a higher value returns the number of edits required to transform one string into the other.
Parameters:
prediction – prediction column name
target – target column name
Returns: levenshtein metric
Returns the mean reciprocal rank (MRR) metric.
This metric is used to evaluate the quality of a ranked list of documents. The MRR score is a number between 0 and 1, where 1 means that the ground truth document is ranked first in the list. The MRR score is calculated by taking the reciprocal of the rank of the first relevant document in the list.
Parameters:
ground_truth_document_id – ground_truth_document_id column name
retrieved_document_ids – retrieved_document_ids column name
Returns: mrr metric
Returns a set of metrics relevant for a question and answer task.
Parameters: prediction – prediction column name (i.e. generated answer)
Returns: list of metrics
Returns a set of metrics relevant for a question and answer task.
Parameters:
prediction – prediction column name (i.e. generated answer)
target – target column name (i.e. expected answer)
input – input column name (i.e. question)
context – context column name (i.e. document or set of documents retrieved)
ground_truth_document_id – ground_truth_document_id containing the information in the target
retrieved_document_ids – retrieved_document_ids containing the full context
ground_truth_document_text – text containing the information in the target (ideal is for this to be the top retrieved document)
top_retrieved_document_text – text of the top retrieved document
eval_llm_client – eval_llm_client
eval_embedding_client – eval_embedding_client
Returns: list of metrics
Returns a set of all metrics relevant for a question and answer task.
Parameters:
prediction – prediction column name (i.e. generated answer)
target – target column name (i.e. expected answer)
input – input column name (i.e. question)
context – context column name (i.e. document or set of documents retrieved)
ground_truth_document_id – ground_truth_document_id containing the information in the target
retrieved_document_ids – retrieved_document_ids containing the full context
ground_truth_document_text – text containing the information in the target (ideal is for this to be the top retrieved document)
top_retrieved_document_text – text of the top retrieved document
eval_llm_client – eval_llm_client
eval_embedding_client – eval_embedding_client
Returns: list of metrics
Returns a set metrics relevant for generic text applications
Parameters:
prediction – prediction column name (i.e. generated answer)
target – target column name (i.e. expected answer)
eval_llm_client – eval_llm_client
eval_embedding_client – eval_embedding_client
Returns: list of metrics
Returns the rouge1 metric between the prediction and target columns.
ROUGE-1 is a recall-oriented metric that calculates the overlap of unigrams (individual words) between the predicted/generated summary and the reference summary. It measures how many single words from the reference summary appear in the predicted summary. ROUGE-1 focuses on basic word-level similarity and is used to evaluate the content coverage.
Parameters:
prediction – prediction column name
target – target column name
Returns: rouge1 metric
Returns the rouge2 metric between the prediction and target columns.
ROUGE-2 is a recall-oriented metric that calculates the overlap of bigrams (pairs of words) between the predicted/generated summary and the reference summary. It measures how many pairs of words from the reference summary appear in the predicted summary. ROUGE-2 focuses on word-level similarity and is used to evaluate the content coverage.
Parameters:
prediction – prediction column name
target – target column name
Returns: rouge2 metric
Returns the rougeL metric between the prediction and target columns.
ROUGE-L is a recall-oriented metric based on the Longest Common Subsequence (LCS) between the reference and generated summaries. It measures how well the generated summary captures the longest sequences of words that appear in the same order in the reference summary. This metric accounts for sentence-level structure and coherence.
Parameters:
prediction – prediction column name
target – target column name
Returns: rougeL metric
Returns the rougeLsum metric between the prediction and target columns.
ROUGE-LSum is a variant of ROUGE-L that applies the Longest Common Subsequence (LCS) at the sentence level for summarization tasks. It evaluates how well the generated summary captures the overall sentence structure and important elements of the reference summary by computing the LCS for each sentence in the document.
Parameters:
prediction – prediction column name
target – target column name
Returns: rougeLsum metric
Returns all rouge metrics between the prediction and target columns.
Parameters:
prediction – prediction column name
target – target column name
Returns: list of rouge metrics
Returns the sentence count metric for the text_col_name column.
Parameters: text_col_name – text column name
Returns: sentence_count metric
Returns a set of metrics relevant for a summarization task.
Parameters:
prediction – prediction column name (i.e. generated summary)
target – target column name (i.e. expected summary)
Returns: list of metrics
Returns the token count metric for the text_col_name column.
A token is a sequence of characters that represents a single unit of meaning, such as a word or punctuation mark. The token count metric calculates the total number of tokens in the text. Different languages may have different tokenization rules. This function is implemented using the nltk library.
Parameters: text_col_name – text column name
Returns: token_count metric
Returns the word count metric for the text_col_name column.
Parameters: text_col_name – text column name
Returns: word_count metric
Computes the similarity of the prediction and target text by evaluating using a language model.
This metric is generated by an LLM using a specific specific prompt named llm_accuracy available in dbnl.eval.metrics.prompts.
Parameters:
prediction – prediction column name
target - target (expected value) column name
eval_llm_client – Eval LLM client
Returns: text similarity metric