An AI Testing strategy can and often includes popular reliability modalities such as model evaluation and traditional monitoring of summary statistics.
Evaluation frameworks are an important tool in the development phase of AI application and can provide insights such as “based on X metric, model A is better than model B on this test set.” In development, the primary role of evaluations is to ensure that the application is performing at an acceptable level. After the app is deployed to production, online evaluations can be performed on production data to check how key performance metrics vary over time. Evaluation frameworks provide a set of off-the shelf metrics that you can use to perform evaluations, however many people choose to write custom evaluations related to business metrics or other objectives specific to their use case.
Observability/monitoring tools log and can respond to events in production. By nature, observability tools catch issues after the fact, treating users as tests, and often miss subtle degradations. Most observability tools look at summary statistics (e.g. P90, P50, accuracy, F1-score, BLEU, ROUGE) over time, but do not provide insights on the underlying distributions of those metrics, and across time.
In an AI Testing framework, you can use eval metrics as the basis for tests by setting thresholds and an alert when that test, or some set of tests fails. With Distributional in particular, you can bring your own custom evals, eval metrics from an open source library, or use the off-the-shelf eval metrics provided by the platform.
Tests can also evaluate more abstract concepts such as whether or not your app looks similar to the day (or week) before.
Getting Access to Distributional
Getting Access
To gain access to the Distributional platform, please reach out to our team. We’ll guide you through the process and ensure you have everything you need to get started.
What is AI Testing?
Understanding AI Testing
Unlike traditional software applications that follow a straightforward input-to-output path, AI applications present unique testing challenges. A typical AI system combines multiple components like search systems, vector databases, LLM APIs, and machine learning models. These components work together, creating a more complex system than traditional software.
Traditional software testing works by checking if a function produces an expected output given a specific input. For example, a payment processing function should always calculate the same total given the same items and tax rate. However, this approach falls short for AI applications for three key reasons, as illustrated in the diagram:
First, AI applications are multi-component systems where changes in one part can affect others in unexpected ways. For instance, a change in your vector database could affect your LLM's responses, or updates to a feature pipeline could impact your machine learning model's predictions.
Distributional Testing
Why we need to test distributions
AI testing requires a very different approach than traditional software testing. The goal of testing is to enable teams to define a steady baseline state for any AI application, and through testing, confirm that it maintains steady state, and where it deviates, figure out what needs to evolve or be fixed to reach steady state once again. This process needs to be discoverable, logged, organized, consistent, integrated and scalable.
AI testing needs to be fundamentally reimagined to include statistical tests on distributions of quantities to detect meaningful shifts that warrant deeper investigation.
Distributions > Summary Statistics: Instead of only looking at summary statistics (e.g. mean, median, P90), we need to analyze distributions of metrics, over time. This accounts for the inherent variability in AI systems while maintaining statistical rigor.
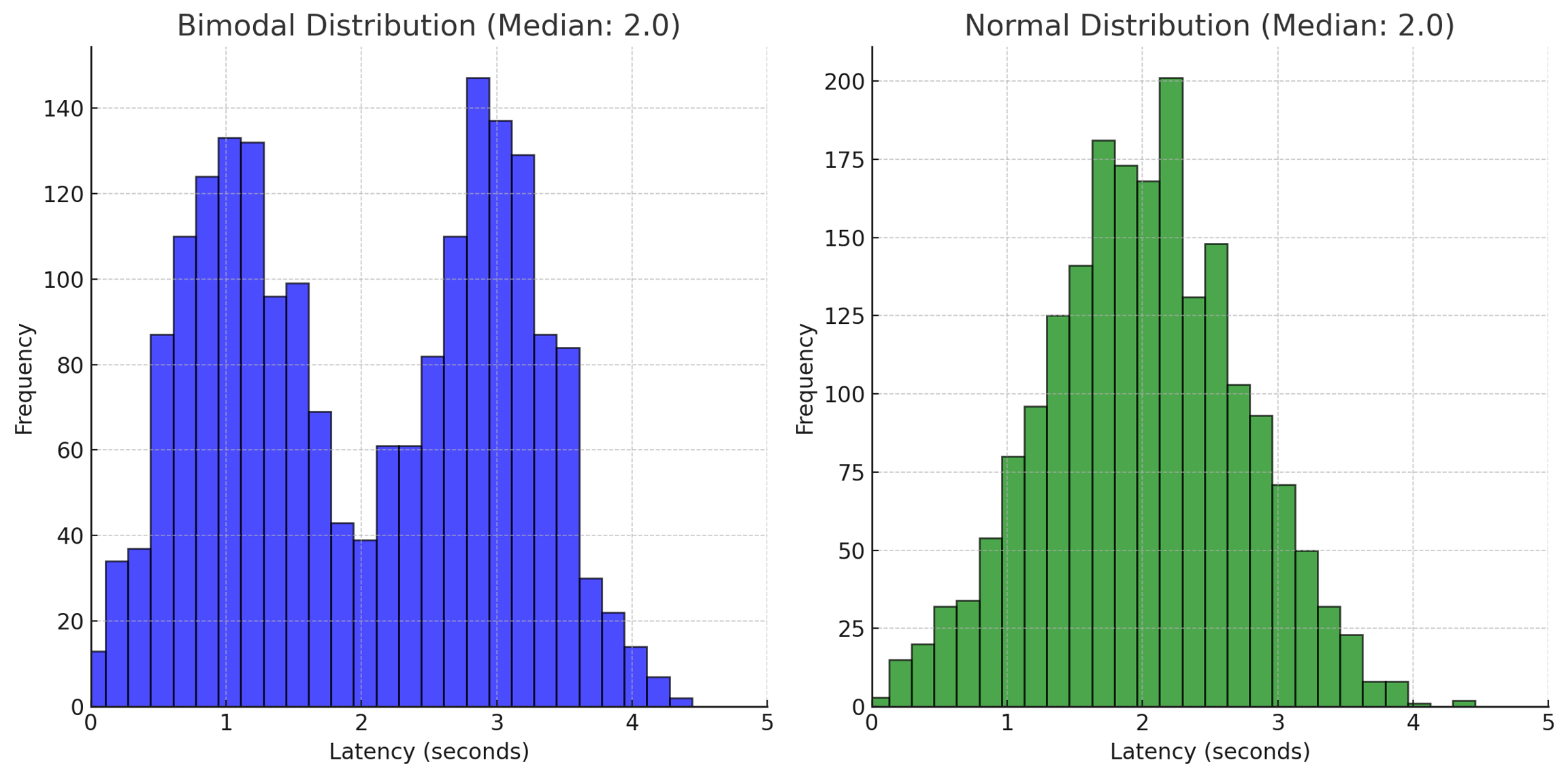
Why is this useful? Imagine you have an application that contains an LLM and you want to make sure that the latency of the LLM remains low and consistent across different types of queries. With a traditional monitoring tool, you might be able to easily monitor P90 and P50 values for latency. P50 represents the latency value below which 50% of the requests fall and will give you a sense of the typical (median) response time that users can expect from the system. However, the P50 value for a normal distribution and bimodal distribution can be the same value, even though the shape of the distribution is meaningfully different. This can hide significant (usage-based or system-based) changes in the application that affect the distribution of the latency scores. If you don’t examine the distribution, these changes go unseen.
Stages in the AI Software Development Lifecycle
Key Stages in the AI Development Lifecycle
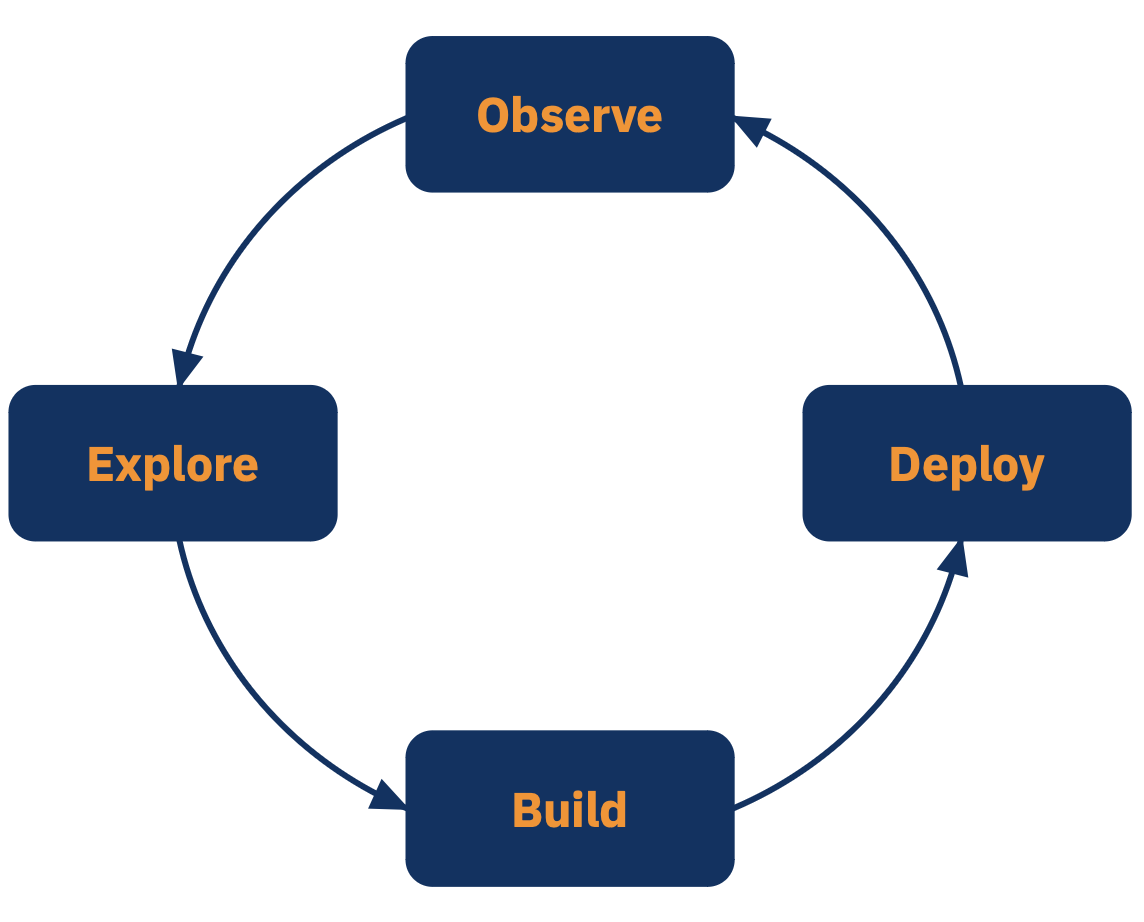
The AI Software Development Life Cycle (SDLC) differs from the traditional SDLC in that organizations typically progress through these stages in cycles, rather than linearly. A GenAI project might start with rapid prototyping in the Build phase, circle back to Explore for data analysis, then iterate between Build and Deploy as the application matures.
The unique challenges of AI systems require a specialized approach to testing throughout the entire life cycle. Testing happens across four key stages, each addressing different aspects of AI behavior: Explore, Build, Deploy, and Observe.
Explore - The identification and isolation of motivating factors (often business factors) which have inspired the creation/augmentation of the AI-powered app.
Motivation
Why AI Testing Matters
Problem
Unlike traditional software applications, AI applications exhibit continuously evolving behavior due to factors such as updates to language models, shifts in context, data drift, and changes in prompt engineering or system integrations. Changing behavior is of great concern to almost any organization building these applications, and is something that they constantly need to address.
If not addressed it is hard for organizations to:
Defining Desired Behavior
Organizations struggle to define what "good" looks like for their AI applications. Current metrics fail to capture the full scope of desired behavior because:
Context Matters – AI behavior differs across applications, use cases, and environments.
Metrics Have Limits – No single set of measurements can fully capture performance across all dimensions.
Evolving Requirements – Business needs, regulations, and user expectations shift over time, requiring continuous refinement.
Understanding and Addressing Changes
When applications changes from expected behavior, organizations struggle to:
Pinpointing Root Causes – Identifying why behavior changed can be complex.
Adapting vs. Fixing – Deciding whether to refine behavior definitions or modify the application itself.
Prioritizing Solutions – Knowing where to start when addressing issues.
Ensuring Effectiveness – Validating that changes lead to meaningful improvements.
The uncertainty of AI applications often prevents AI applications from seeing the light of day. For those that reach production, teams lack the tools to effectively monitor and maintain their performance.
Solution
Distributional helps organizations understand and track how your AI application behaves in two main ways:
First, it watches your application's inputs and outputs over time, building a picture of “expected” behavior. Think of it like your AI applications fingerprint - when your applications fingerprint changes Distributional notices and alerts you. If something goes wrong, it shows you exactly what changed and helps you figure out why, making it easier to fix problems quickly.
Secondly, the system keeps track of everything it learns about your application's behavior, saving these insights for future use. Organizations can apply what they learn from one AI application to similar ones, helping them test and improve new applications more quickly. This creates a consistent way to test AI applications across an organization and ensures that your AI application reaches maximum up-time.
Defining Tests in Distributional
What's in a test?
Tests are the core mechanism for asserting acceptable app behavior within Distributional. In this section, we introduce the necessary tools and explain how they can be used -- either with guidance from Distributional or by users based on unique needs.
At its core, a Test is a combination of a Statistic, derived from a run, which defines some behavior of the run, and an Assertion which enumerates the acceptable values of that statistic (and, thus, the acceptable behavior of a run). The run under consideration in a test is referred to as the Experiment run; often, there will also be a Baseline run used for comparison.
Test Tags can be created and applied to tests to group them together for, among other purposes, signaling the shared purpose of several tests (e.g., tests for text sentiment).
When a group of tests is executed on a chosen Experiment and Baseline Run, the output is a Test Session containing which assertions Pass and Fail.
Living in your VPC
Distributional runs on data, but we know that your data is incredibly valuable and sensitive. This is why Distributional is built to be deployed in your private cloud. We have AWS and GCP installations today and are working towards an Azure installation. There is also a SaaS version available for demonstrations or proofs of concept.
Second, AI applications are non-stationary, meaning their behavior changes over time even if you don't change the code. This happens because the world they interact with changes - new data comes in, language patterns evolve, and third-party models get updated. A test that passes today might fail tomorrow, not because of a bug, but because the underlying conditions have shifted.
Third, AI applications are non-deterministic. Even with the exact same input, they might produce different outputs each time. Think of asking an LLM the same question twice - you might get two different, but equally valid, responses. This makes it impossible to write traditional tests that expect exact matches.
Comparison of traditional software vs. AI workflows
Consider a scenario where the distribution of LLM latency started with a normal distribution, but due to changes in a third-party data API that your app uses to inform the response of the LLM, the latency distribution becomes bimodal, though with the same median (and P90 values) as before. What could cause this? Here’s a practical example of how something like this could happen. The engineering team of the data API organization made an optimization to their API which allows them to return faster responses for a specific subset of high value queries, and routes the remainder of the API calls to a different server which has a slower response rate.
The effect that this has on your application is that now half of your users are experiencing an improvement in latency, and now a large number of users are experiencing “too much” latency and there’s an inconsistent performance experience among users. Solutions to this particular example include modifying the prompt, switching the data provider to a different source, format the information that you send to the API differently or a number of other engineering solutions. If you are not concerned about the shift and can accept the new steady state of the application, you can also choose to not make changes and declare a new acceptable baseline for the latency P50 value.
Bimodal vs Normal distribution of Latency
Build - Iteration through possible designs and constraints to produce something viable.
Deploy - The process of converting the developed AI-powered app into a service which can be deployed robustly.
Observe - Continual review and analysis of the behavior/health of the AI-powered app, including notifying interested parties of discordant behavior and motivating new Build goals. Without continuous feedback from the Observe phase, there’s a substantial risk that the application does not behave as expected - for example, the output of an LLM could provide nonsensical or incorrect responses. Additionally, the performance of the application degrades over time as the distributions of the input data shifts.
Testing Across the AI SDLC
AI Reliability Stack: AI Testing spans the AI SDLC
Existing AI reliability methods - such as evaluations and monitoring - play crucial roles in the AI SDLC. However, they often focus on narrow aspects of reliability. AI testing, on the other hand, encompasses a more comprehensive approach, ensuring models behave as expected before, during, and after deployment.
Distributional is designed to help continuously ask and answer the question “Is my AI-powered app performing as desired?” In pursuit of this goal, we consider testing at three different elements of this lifecycle.
Production testing: Testing actual app usages observed in production to identify any unsatisfactory or unexpected app behavior.
This occurs during the Observe step.
Deployment testing: Testing the app currently deployed with a fixed (a.k.a. golden) dataset to identify any nonstationary behavior in components of the app (e.g., a third party LLM.)
This occurs during the Deploy step and in the arrow to the Observe step
Development testing: Testing new app versions on a chosen dataset to confirm that bugs have been fixed or improvements have been implemented.
This occurs between Build and Deploy.
AI SDLC
Welcome to Distributional
Introduction to Distributional AI Testing Platform
At Distributional, we make AI testing easy, so you can build with confidence. Here’s how it works:
✅ Connect to your existing data sources.
🔄 Run automated tests on a regular schedule.
📢 Get alerts when your AI application needs your attention.
Simple, seamless, and built for peace of mind. Let's help you improve your AI uptime.
For getting access to the Distributional platform, .
AI Test Cases
When do you need AI Testing? To get a sense of what testing could look like in practice, here are some questions that you can answer through AI Testing across the AI Software Development Lifecycle:
During Development
During Deployment
During Production
If you are interested in finding the answers to the above, Distributional can help. The Distributional platform provides a standardized approach to AI testing across all of your applications.
Ready to start using Distributional? Head straight to to get set up on the platform and start testing your AI application.
If you would first like to learn more about the Distributional platform, head over to the section. If you are new to AI Testing or would like to know how it fits in to the AI Software Development Cycle, continue forward in the Introduction to AI Testing section, starting with the and pages.
Reviewing Test Sessions and Runs in Distributional
Test sessions provide an opportunity to learn about your app's behavior
After you define and execute tests, dbnl creates a Test Session to mark a permanent statement of how your app behaved relative to expectations. You can explore this Test Session, as well as the Runs that were tested, to learn about your app -- both its behavior and about how users interacted with it.
The is available for all tests, including any tests you may have created with . In this section, we highlight key insights that can be gained from the automated Production tests, insights from elsewhere in the Distributional UI, and how you can be notified about your Test Session status in whatever fashion you prefer.
Distributional runs on data, but our goal is to enable you to operate on data you already have available. If you are using a golden dataset to guide your development, we want you to use that to power your Development and Deployment testing. If you have actual Question-Answer pairs from production that are sitting in your data warehouse, we recommend that you to execute Production testing on that data to continually assert that your app is not misbehaving.
Generally, data is organized on Distributional in the form of a parquet file full of app usages, e.g., the prompts and summaries observed in the last 24 hours. This data is then packaged up and shipped to Distributional’s API, primarily through our SDK. This could include any contextual information that can help determine if the app is behaving as desired, such as the day of the week.
Prior to shipping the data to dbnl, the dbnl Eval library can be used to augment your data (especially text data) with additional columns for a more complete testing experience.
SDK
Tests can be programmatically created using the python SDK. Users must provide a JSON dictionary that adheres to the dbnl Test Spec and instantiates the key elements of a Test. The Testing Strategies section has sample content around creating tests using JSON. Additionally, the test creation page will soon also have the ability to convert a test from dropdowns to JSON, so that many tests of similar structure can be created in JSON after the first one is designed in the web UI.
Data in Distributional
Data goes in, insights come out
Distributional runs on data, so we make it easy for you to:
Push data into Distributional
Augment your unstructured data, such as text, to facilitate testing
Organize your data to enable more insightful testing
Review data that has been sent to Distributional
Creating Tests
There are several ways for dbnl users to create tests, each of which may be useful in different circumstances and for different users within the same organization.
Functions
Click through to view all the SDK functions.
Data Storage Integrations
As Distributional continues to evolve, we have made it our mission to meet customers where they, and their data, live. As such, we are building out integrations to pull in data from common cloud storage systems including, but not limited to, Snowflake and Databricks. Please contact your dedicated engineer to discuss the status of our integrations and implementing them in your system.
Testing Strategies
Like in traditional software testing, it is paramount to come up with a testing strategy that has both breadth and depth. Such a set of tests gives confidence that the AI-powered app is behaving as expected, or it alerts you that the opposite may be true.
To build out a comprehensive testing strategy it is important to come up with a series of assertions and statistics on which to create tests. This section explains several goals when testing and how to create tests to assert desired behavior.
Executing Tests
After tests are created for an associated project, there are two ways that they can be executed.
Manually via the UI on the Project Details page
Via the SDK using the create_test_session method
Python SDK
The primary mechanism for submitting data to Distributional is through our Python SDK. This section contains information about how to set up the SDK and use it for your AI testing purposes.
Objects
How well do my evals map to production behavior?
When do I increase coverage in my golden dataset to address edge cases?
If something changes in one component of my application, how do I assess the cascading impact to other dependent components?
Are end-users catching issues that my evals miss?
How do I compare new application updates to prior ones in my production environment?
What’s the impact to behavior if the model, data, or usage shifts?
Do I know when shifts happen?
How do I understand what’s causing anomalous behavior?
What happens if I switch to another LLM?
How do I give other teams visibility into shifts that happen?
What’s the impact of pushing any change to my application? Am I able to push changes to production or is it a new dev cycle?
Distributional can automate your Production testing process
Production testing is the core tool in the Distributional toolkit – it provides the ability to continually state whether your app is performing as desired.
To make Production testing easy to start using, we have developed some automated Production test creation capabilities. Using sample data that you upload to our system, we can craft tests which help determine if there has been a shift in behavior for your app.
From this page, you can ask Distributional to create Tests and query Runs to define a baseline.
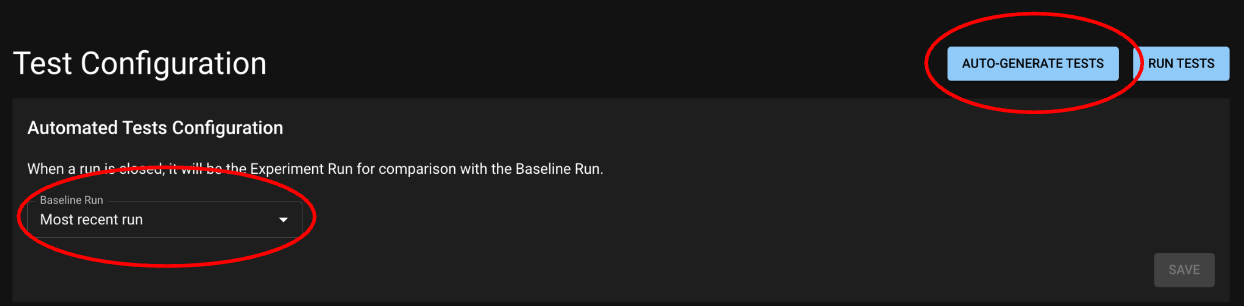
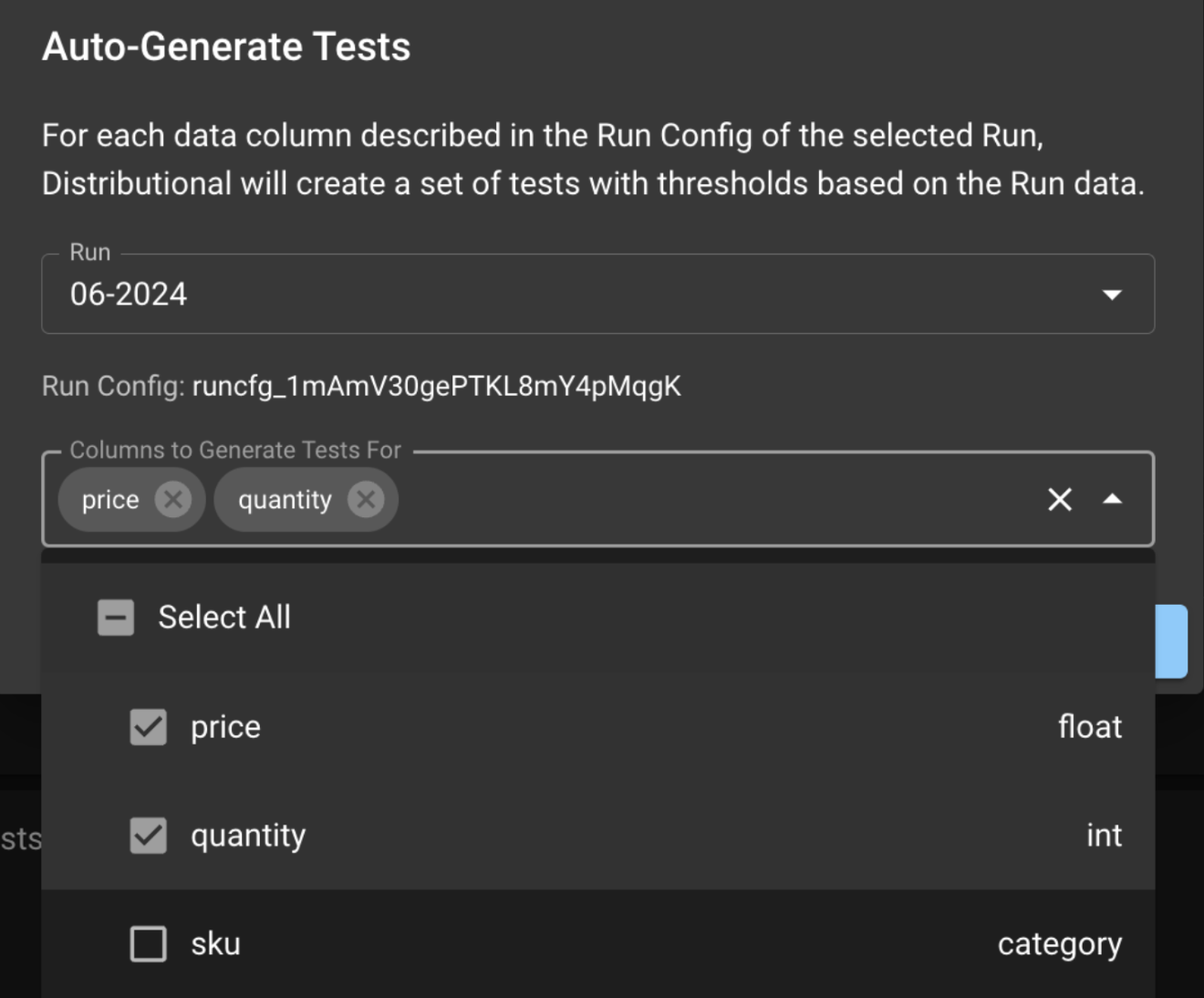
The Auto-Generate Tests button takes you to the modal below, which allows you to choose the columns on which you want to test for app consistency.
Select a Run from which to create Production tests,
and select columns that should be tested.
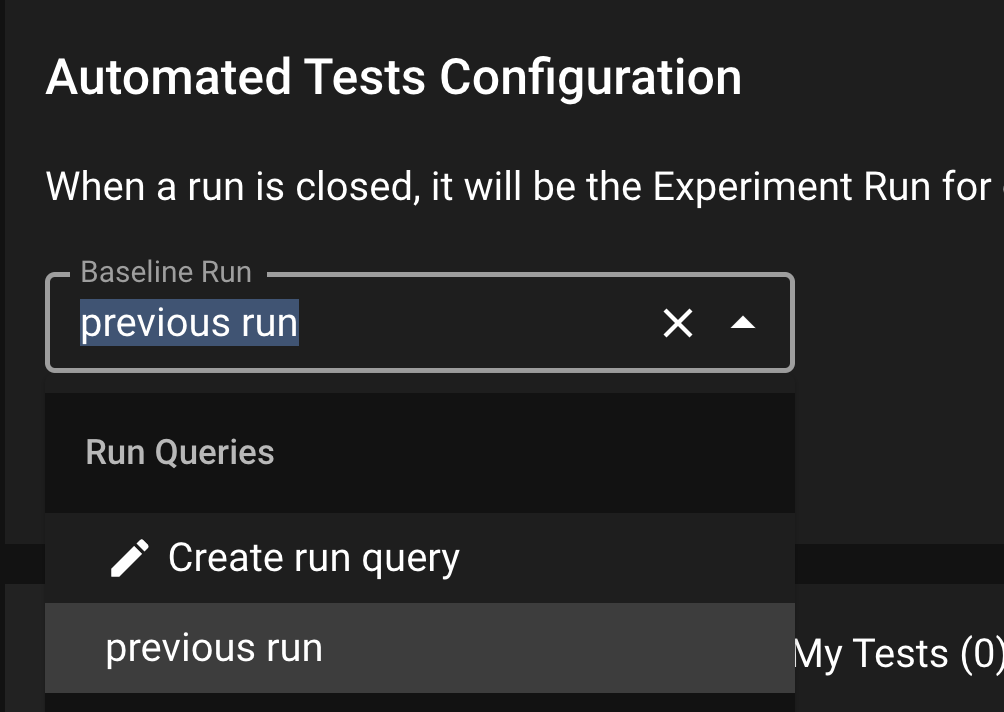
Setting a Baseline through a Run Query
You also have the opportunity to set a Baseline Run Query, which gives you the freedom to define how far into the past you want to look to define “consistency”. After setting the Baseline, your tests will utilize it by default; you can override it at test creation time. Over time, your project will graphically render the health of your app, as shown below.
Recalibrating tests
You may later deactivate or any of the automatically generated tests as you feel the desire to adapt these tests to meet your needs. In particular, we recommend that you review the first several test sessions in a new Project and recalibrate based on observed behavior. If you believe that no significant difference exists between tested runs, you should recalibrate the generated tests to pass.
The flow of data
Your data + dbnl testing == insights about your app's behavior
Distributional uses data generated by your AI-powered app to study its behavior and alert you to valuable insights or worrisome trends. The diagram below gives a quick summary of this process:
Each app usage involves input(s), the resulting output(s), and context about that usage
Example: Input is a question about the city of Toronto; Output is your app’s answer to that question; Context is the time/day that the question was asked.
As the app is used, you record and store the usage in a data warehouse for later review
Example: At 2am every morning, an airflow job parses all of the previous day’s app usages and sends that info to a data warehouse.
When data is moved to your data warehouse, it is also submitted to dbnl for testing.
Example: The 2am airflow job is amended to include data augmentation by dbnl Eval and uploading of the resulting dbnl Run to trigger automatic app testing.
You can read more about the dbnl specific terms . Simply stated, a dbnl Run contains all of the data which dbnl will use to test the behavior of your app – insights about your app’s behavior will be derived from this data.
A dbnl Run usually contains many (e.g., dozens or hundreds) rows of inputs + outputs + context, where each row was generated by an app usage. Our insights are statistically derived from the distributions estimated by these rows.
is our library that provides access to common, well-tested GenAI evaluation strategies. You can use dbnl Eval to augment data in your app, such as the inputs and outputs. Doing so produces a broader range of tests that can be run, and it allows dbnl to produce more powerful insights.
The Distributional Framework
Key Distributional concepts and their role relative to your app
The expected flow of app information to Distributional for run creation within a project
Distributional testing requires more information than standard deterministic testing to address the motivating bullets (nondeterminism, nonstationarity, interactions) described earlier. Each time you want to measure the behavior of the app, Distributional wants you to:
Record outcomes at all of the app’s components, and
Push a distribution of inputs through the app to study behavior across the full spectrum of possible app usage.
The inputs, outputs, and outcomes associated with a single app usage are grouped in a Result, with each value in a result described as a Column. The group of results that are used to measure app behavior is called a Run. To determine if an app is behaving as expected, you create a Test, which involves statistical analysis on one or more runs. When you apply your tests to the runs that you want to study, you create a Test Session, which is a permanent record of the behavior of an app at a given time.
Notifications
Customize how you want to be alerted to new Runs, new Test Sessions, and high severity failures
Distributional analyzes your data and executes your tests, but we also want to alert you about the status of your tests and the health of your app as new data arrives. We provide a notifications suite, to enable you to receive updates about your app’s health as you desire.
Customize your notifications at the Project Detail page.
Notifications are configured as part of a Project, as seen in the screenshot above. When a test session fails by some predefined margin (e.g., more than 20% failures), members of your team can receive an alert, such as a Pagerduty. Or, if certain tests concern only certain members of your team, notifications to those members can be limited to only those tests failing.
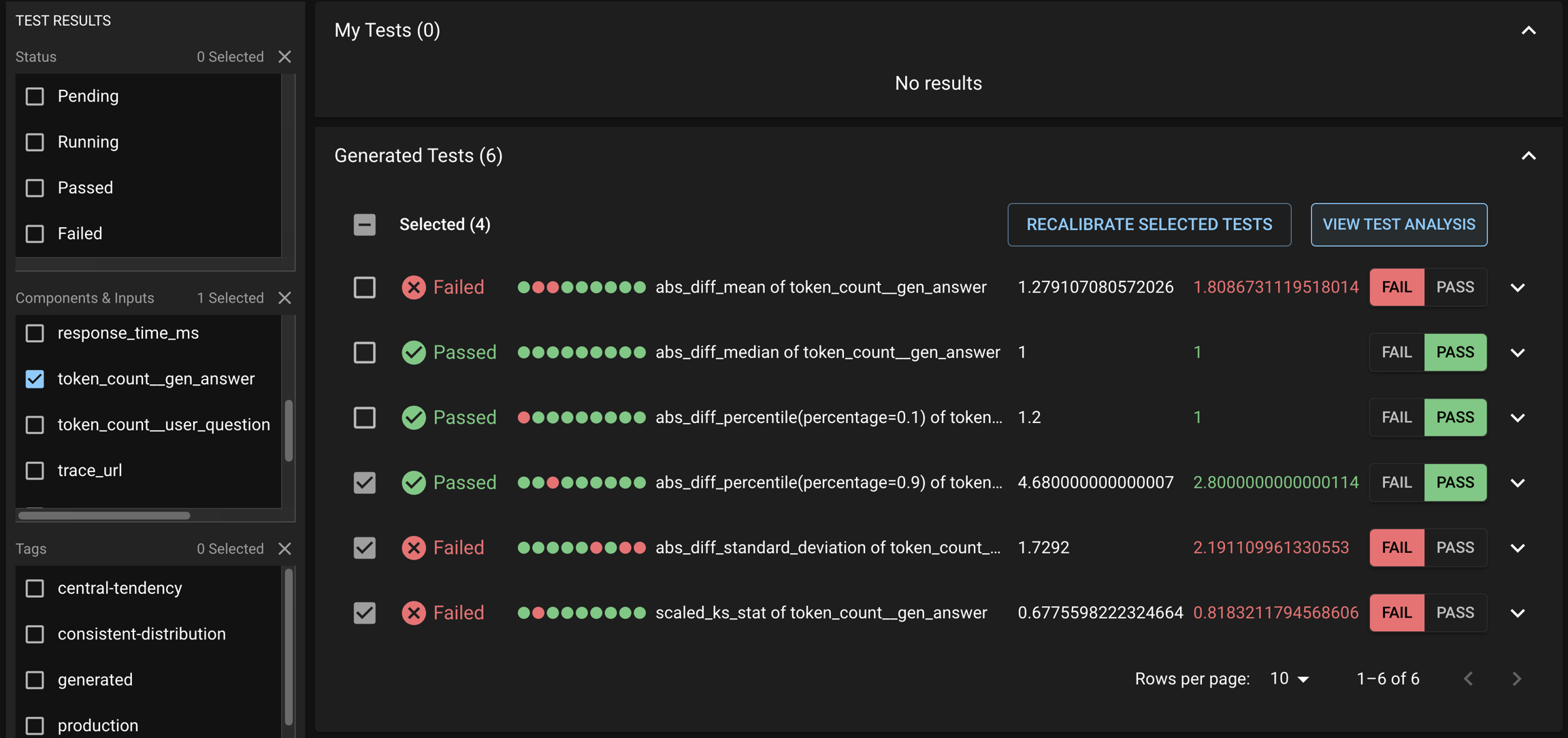
After a Test Session is executed, users might want to introspect on which Tests passed and failed. In addition, they want to understand what caused a Test or a group of Tests to fail; in particular, which subset of results from the Run likely caused the Tests to fail.
Notable results are only presented for Distributional generated tests
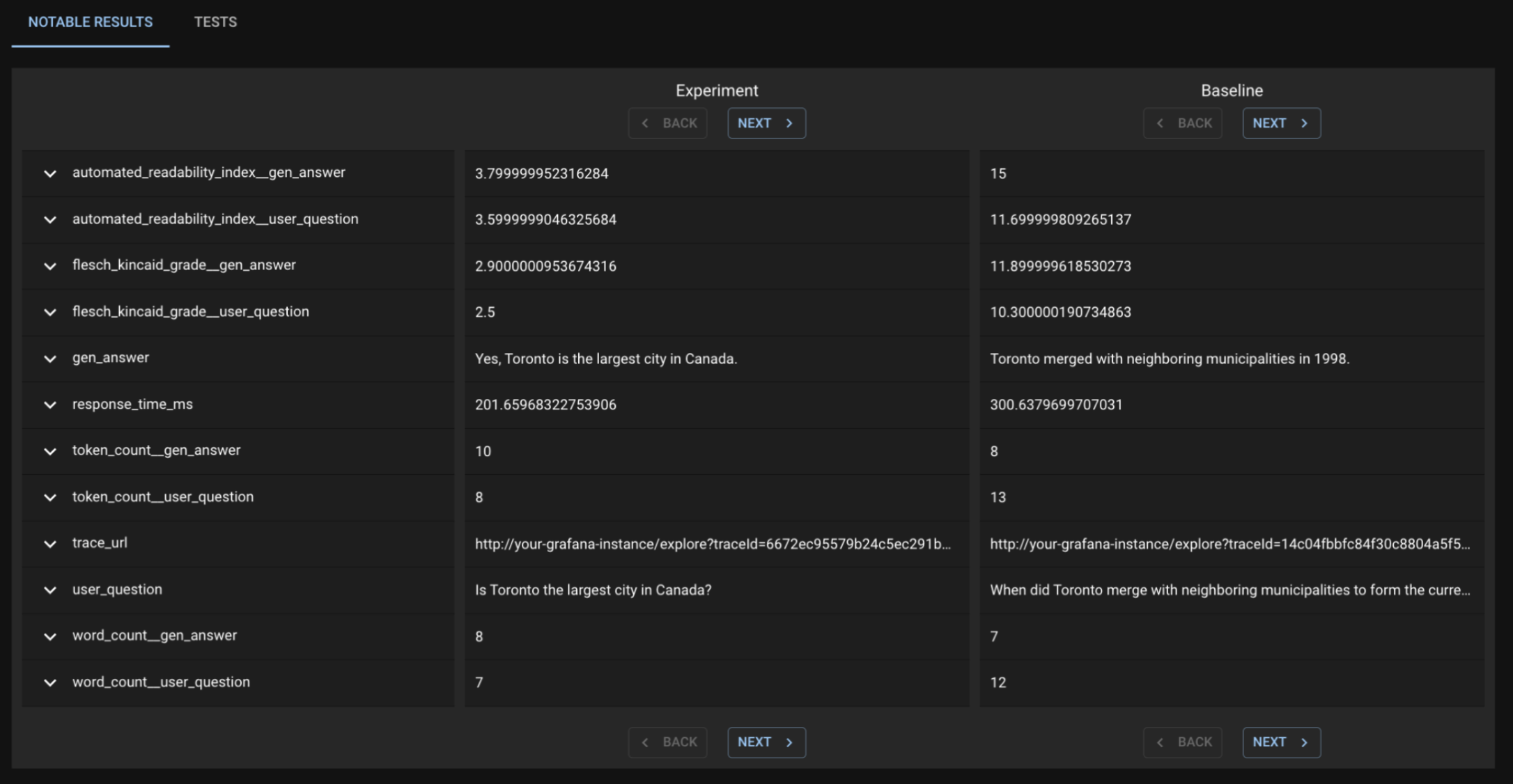
Reviewing notable results
To review the notable results, first select the desirable set of Generated Tests that you want to study from the Test Session details page. This may include both failed and passed Tests.
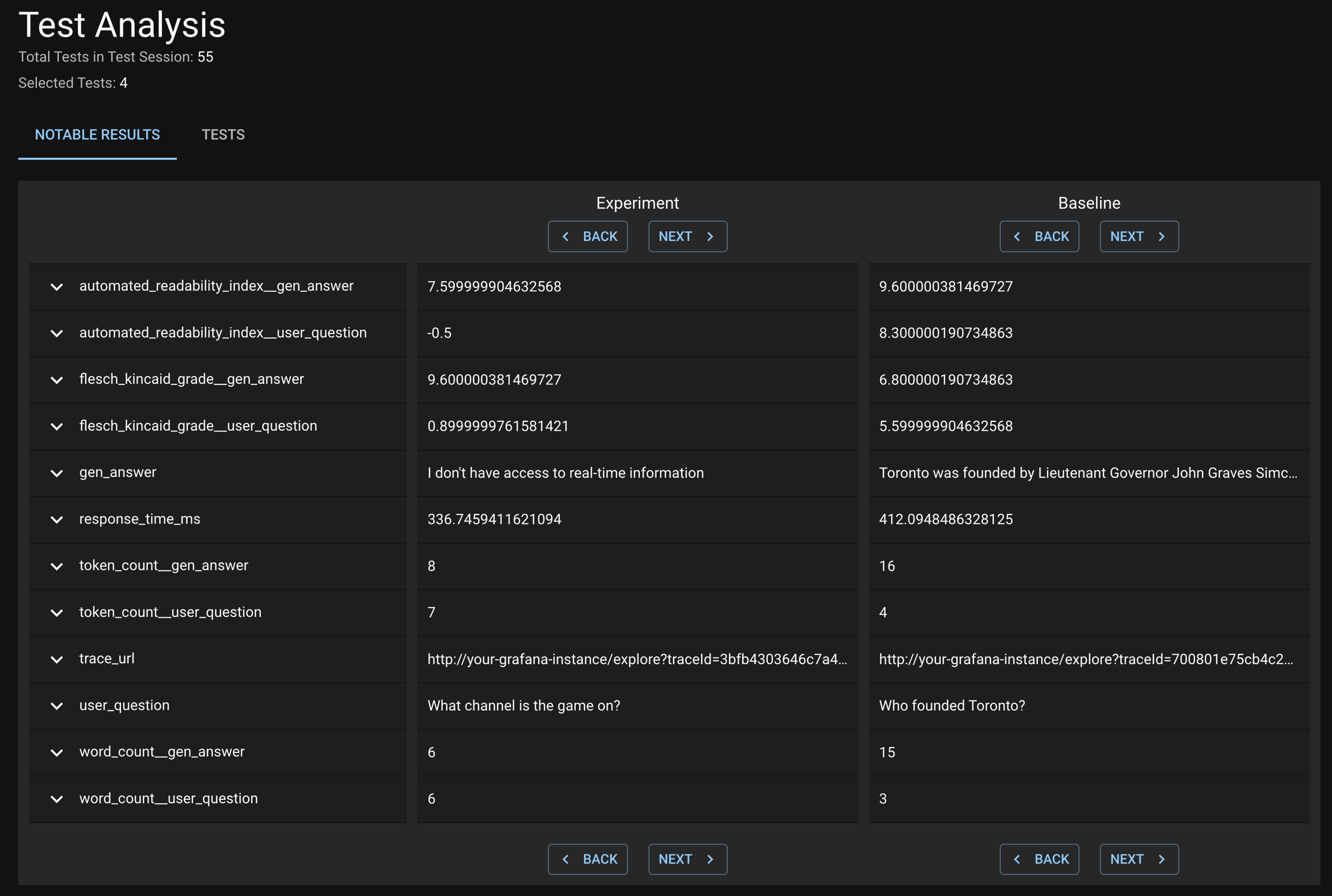
Click VIEW TEST ANALYSIS button to enter the Test Analysis page. On this page, you can review the notable results for the Experiment Run and Baseline Run under the Notable Results tab.
Access
The following section introduces the concepts used to control access to the dbnl platform.
Tokens
Tokens are used for programmatic access to the dbnl platform.
Personal Access Tokens
A personal access token is a token that can be used for programmatic access to the dbnl platform through the SDK.
Tokens are not revocable at this time. Please remember to keep your tokens safe.
Permissions
A personal access token has the same permissions as the user that created it. See for more details about permissions.
Token permissions are resolved at use time, not creation time. As such, changing the user permissions after creating a personal access token will change the permissions of the personal access token.
Create a Personal Access Token
To create a new personal access token, go to ☰ > Personal Access Tokens and click Create Token.
Personal access tokens are implemented using and are not persisted. Tokens cannot be recovered if lost and a new token will need to be created.
Test Page
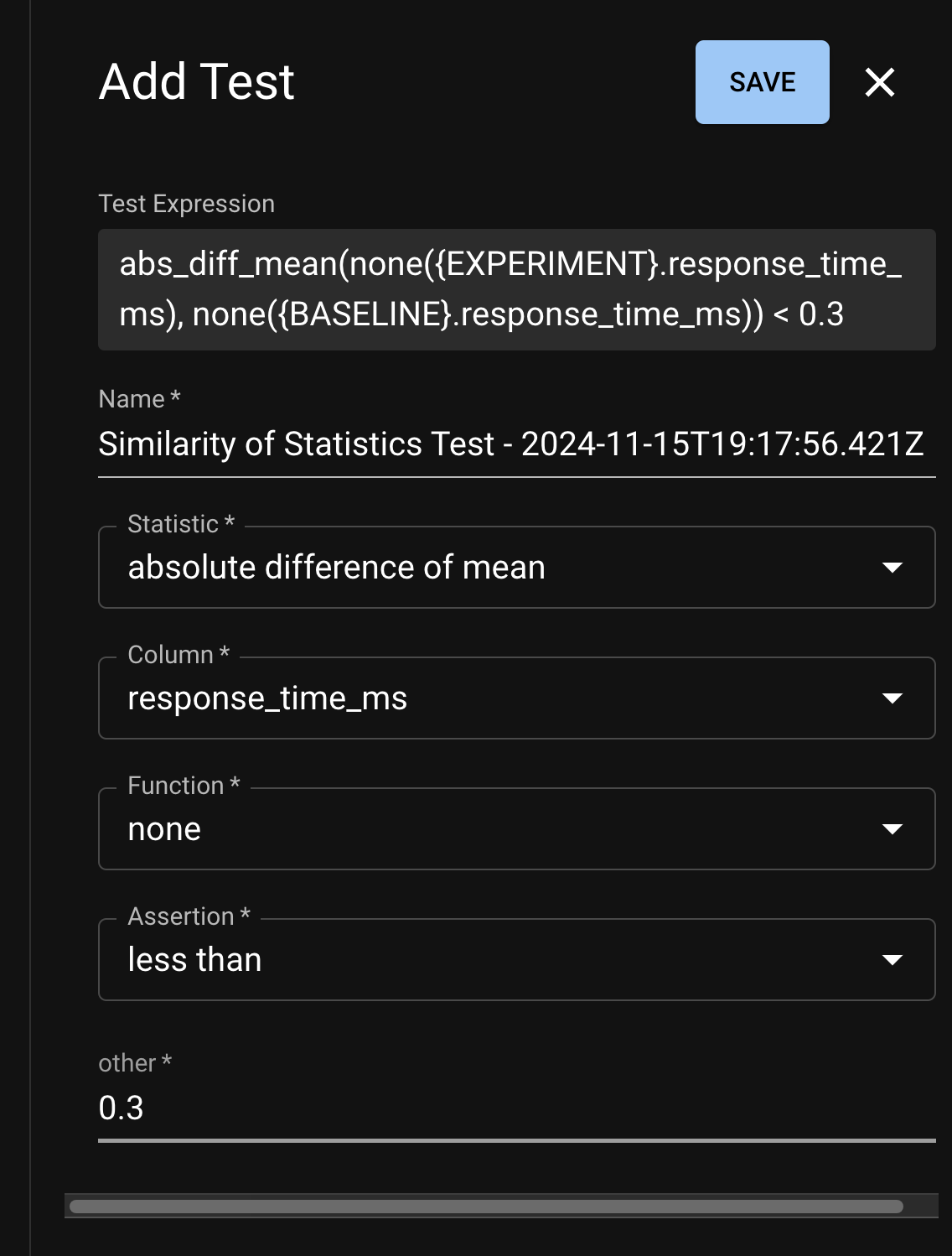
The base location at which a test can be created is the Test Configuration page, which is accessible from the Project Detail page.
Creating a Test
From here, you can click Add Test to open the test creation page, which will enable you to define your test through the dropdown menu on the left side of the window.
The full test creation page, with the modal on the left side and helping graphs on the right.
The graphs available on the right side of the window can help guide test development as you choose the statistics you want to study and the thresholds which define acceptable behavior.
Reviewing Tests
After the tests have been executed, what comes next?
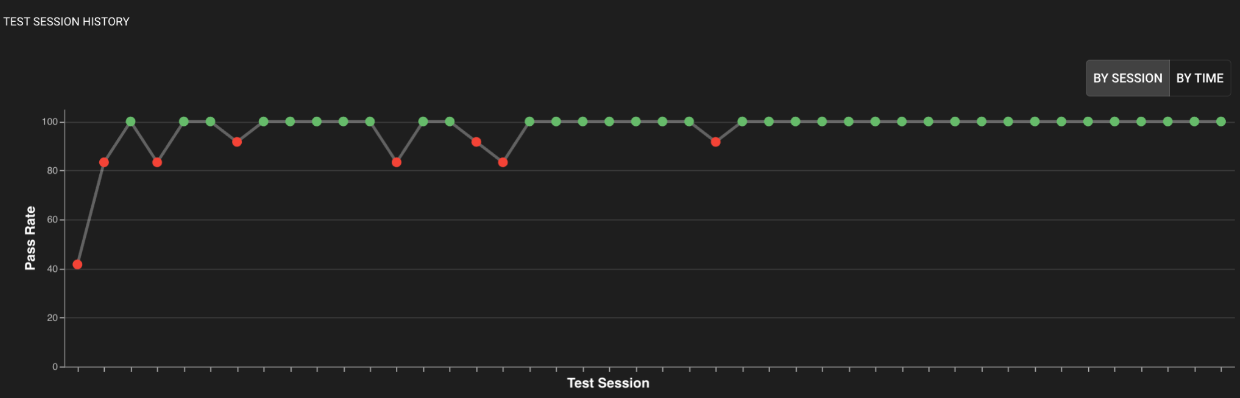
Executing tests creates a Test Session, which summarizes the specified tests associated with the session, specifically highlighting whether each test’s assertion has passed or failed.
A project detail page with two completed test sessions — the circled test session had two failed assertions.
The Test History section of the Project Detail pages is a record of all the test sessions created over time. Each row of the Test History table represents a Test Session. You can click anywhere on a Test Session row to navigate to the Test Session Detail page where more detailed information for each test can be viewed.
Insights surfaced elsewhere on Distributional
Test Sessions are not the only place to learn about your app
Distributional’s goal is to provide you the ability to ask and answer the question “Is my AI-powered app behaving as expected?” While testing is a key component of this, triage of a failed test and inspiration for new tests can come from many places in our web UI. Here, we show insights into app behavior which are uncovered with Distributional.
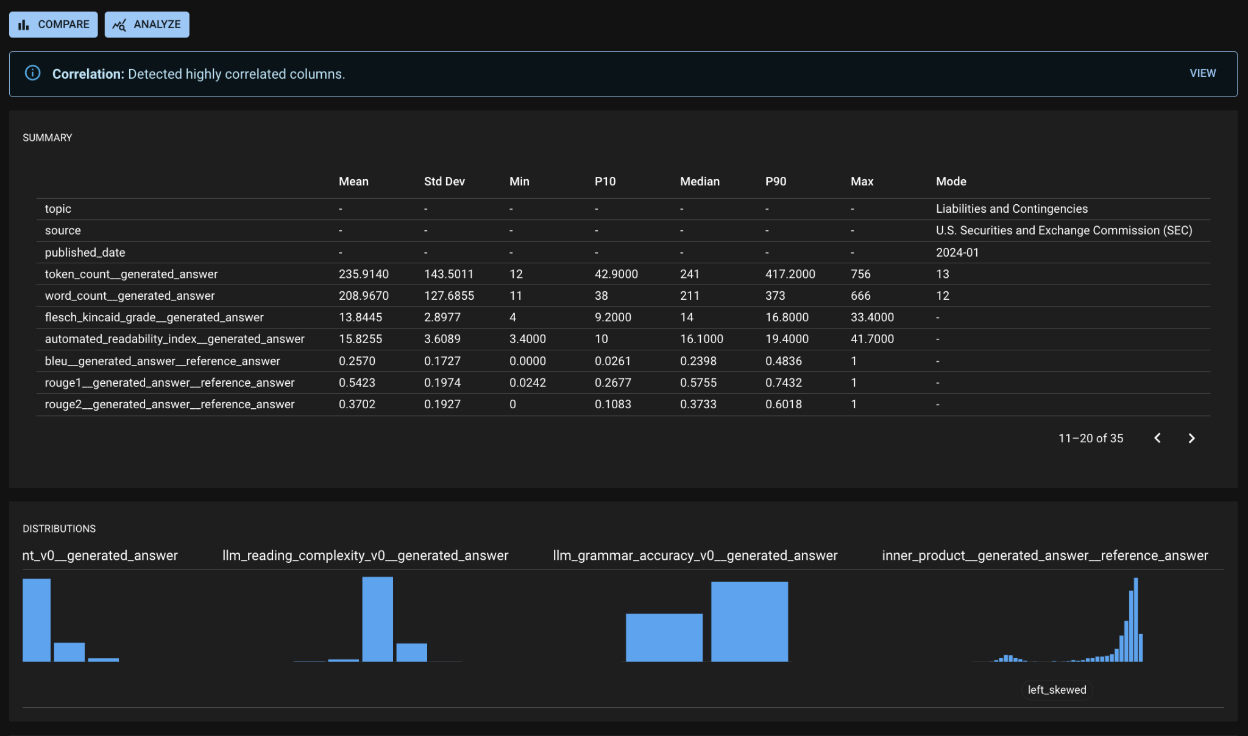
Run Detail page
Because each Run represents the recent behavior of your app, the Run Detail page is a useful source of insights about your app’s behavior. In the screenshot below, you can see:
Recalibration
When Distributional automatically generates the production tests, the thresholds are estimated from a single Run’s data. As a consequence, some of these thresholds may not reflect the user’s actual working condition. As the user continues to upload Runs and triggers new Test Sessions, they may want to adjust these thresholds. The recalibration feature offers a simple option to adjust these thresholds.
How to recalibrate tests
Recalibration solicits feedback from the user and adjusts the test thresholds. If a user wants a particular test or set of tests to pass in the future, the test thresholds will be relaxed to increase the likelihood of the test passing with similar statistics.
Data Objects
The objects needed to define a Run, the core data structure in DBNL
The core object for recording and studying an app’s behavior is the run, which contains:
a table where each row holds the outcomes from a single app usage,
structural information about the components of the app and how they relate, and
Organization and Namespaces
Resources in the dbnl platform are organized using organizations and namespaces.
Organization
An organization, or org for short, corresponds to a dbnl deployment.
Test Drawer Through Shortcuts
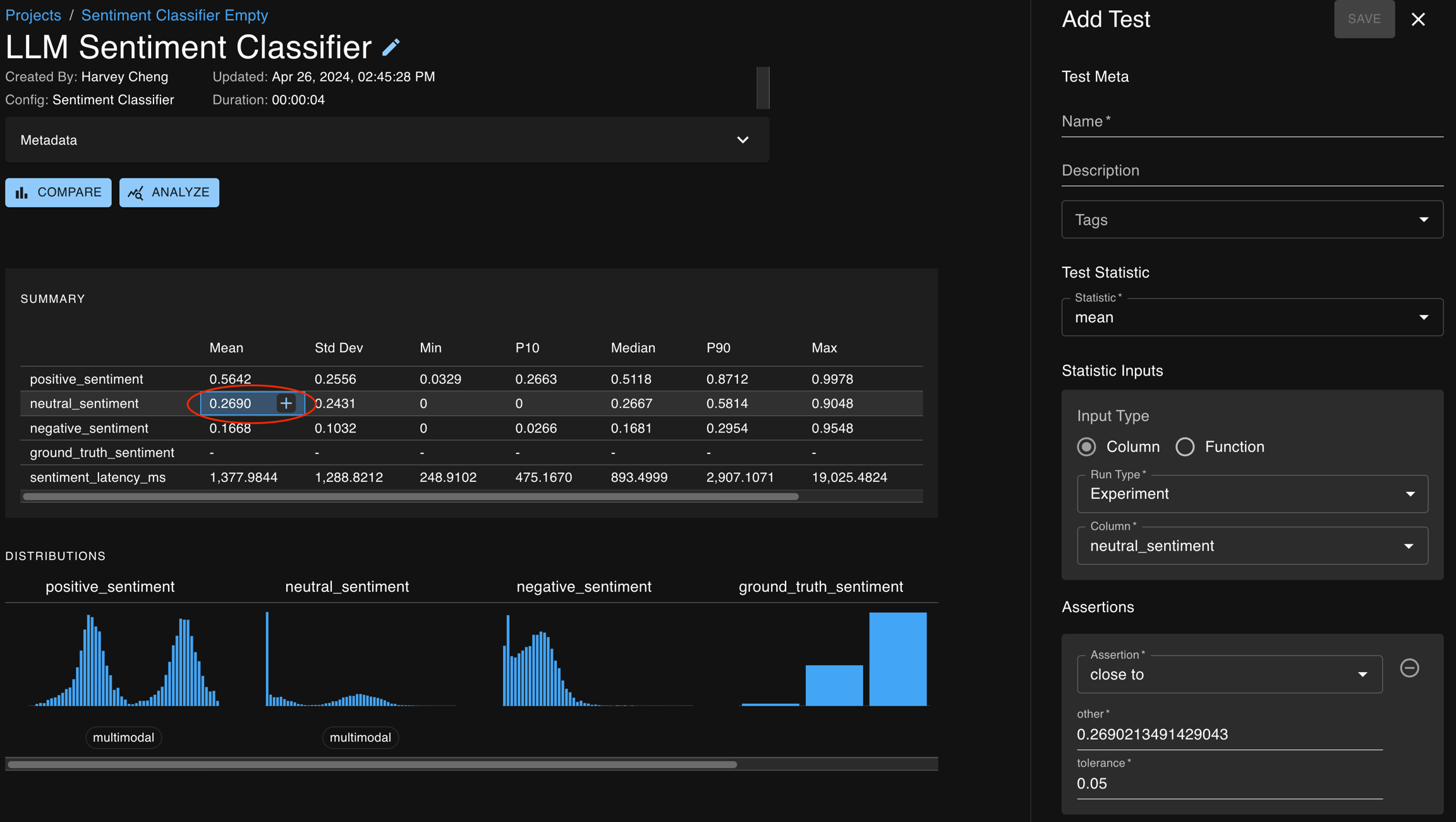
You can also create tests by clicking on the + icon button which appears in several places :
Cells in the summary statistics tables (found on the Run Detail page, Compare pages)
Mini charts (clicking on the title and the column feature button, found on Run Detail page)
Test That Specific Results Have Matching Behavior
When the results from a run have unique identifiers, one can create a special type of tests for testing matching behavior at a per-result level. One example would be testing the mean of per-result absolute difference does not exceed a threshold value.
Example Test Spec
Data Access Controls
An overview of data access controls.
Data for a run is split between the object store (e.g. S3, GCS) and the database.
Metadata (e.g. name, schema) and aggregate data (e.g. summary statistics, histograms) are stored in the database.
Raw data is stored in the object store.
Components and the DAG for root cause analysis
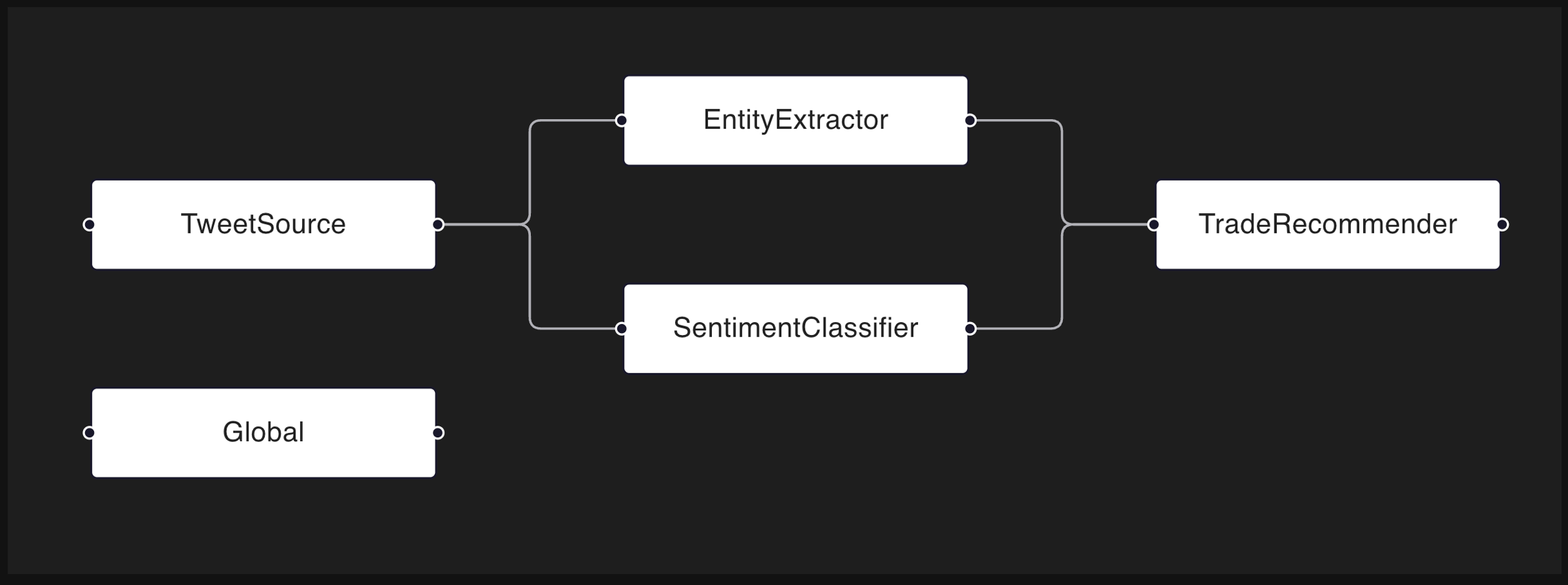
Distributional runs on data. When that data is well organized, Distributional can provide more powerful insights into your app’s behavior. One key way to do so is through defining components of your app and the organization of those components within your app.
Components are groupings of columns – they provide a mechanism for identifying certain columns as being generated at the same time or otherwise relating to each other. As part of your data submission, you can define that grouping as well as a flow of data from one component to another. This is referred to as the DAG, the directed acyclic graph.
In the example above, we see:
Data being input at TweetSource (1 column),
Defining Assertions
Assertions are the second half of test creation — defining what statistical values seem appropriate or aberrant
A test consists of statistical quantities that define the behavior of one or more runs and an associated threshold which determines whether those statistics define acceptable behavior. Essentially, a test passes or fails based on whether the quantities satisfy the thresholds. Common assertions include:
equal_to – Used most often to confirm that two distributions are exactly identical
close_to
Test That Distributions Are Not the Same
Another testing case is testing whether two distributions are not the same. Such a test involves the same statistics as a test of consistency, but a different assertion. One example could be to change the assertion from close_to to greater_than and thereby state that a passed test requires a difference bigger than some threshold.
Example Test Spec
Test That Distributions Have the Same Statistics
Another type of test is testing if a particular statistic is similar for two different distributions. For example, this can be testing if the absolute difference of medians of sentiment score between the experiment run and the baseline run is small — that is, the scores are close to one another.
Example Test Spec
Executing Tests Via SDK
Tests can also be executed via the SDK after results data has been reported. This requires the following steps.
Report an initial run and set that as a baseline
get_run_config
Retrieve a dbnl RunConfig
Parameters
Arguments
Description
Project
Functions that interact with a dbnl
Dynamic Baseline
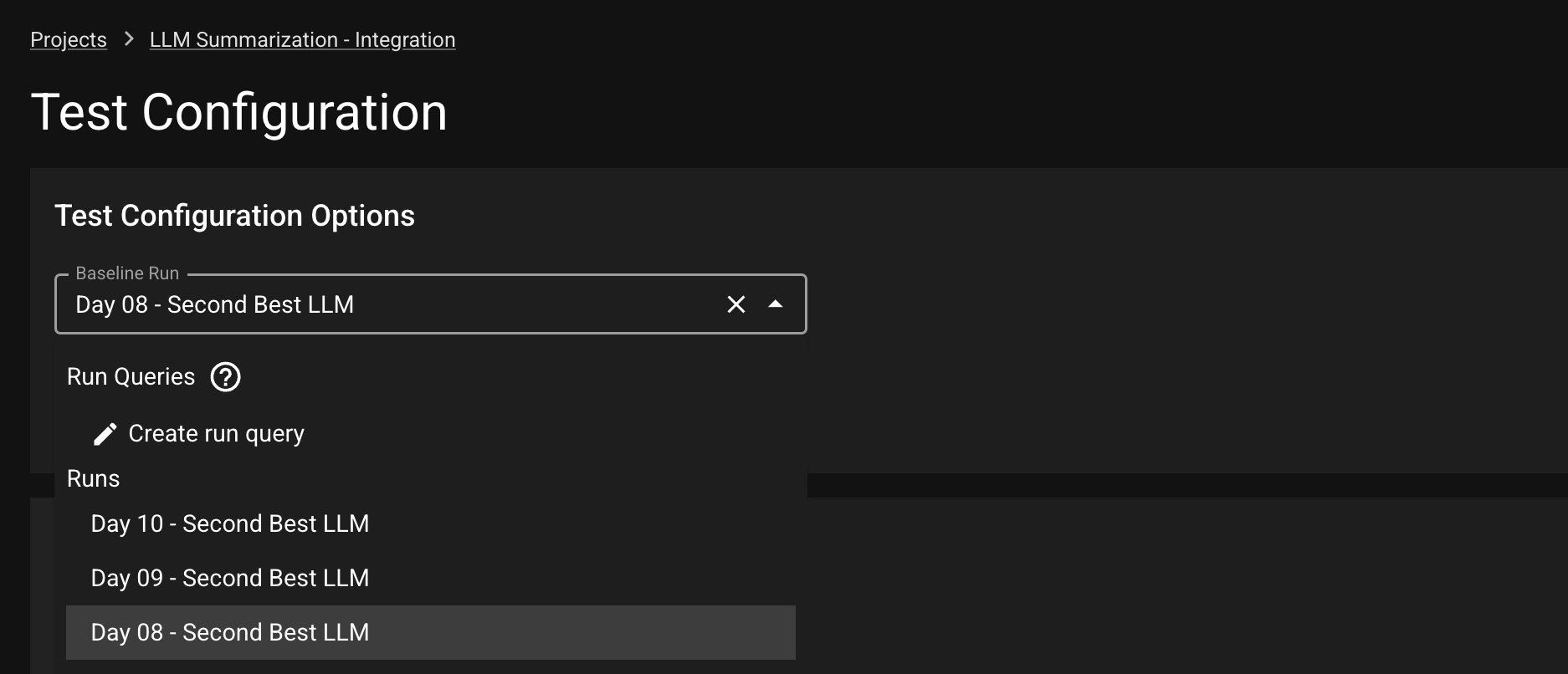
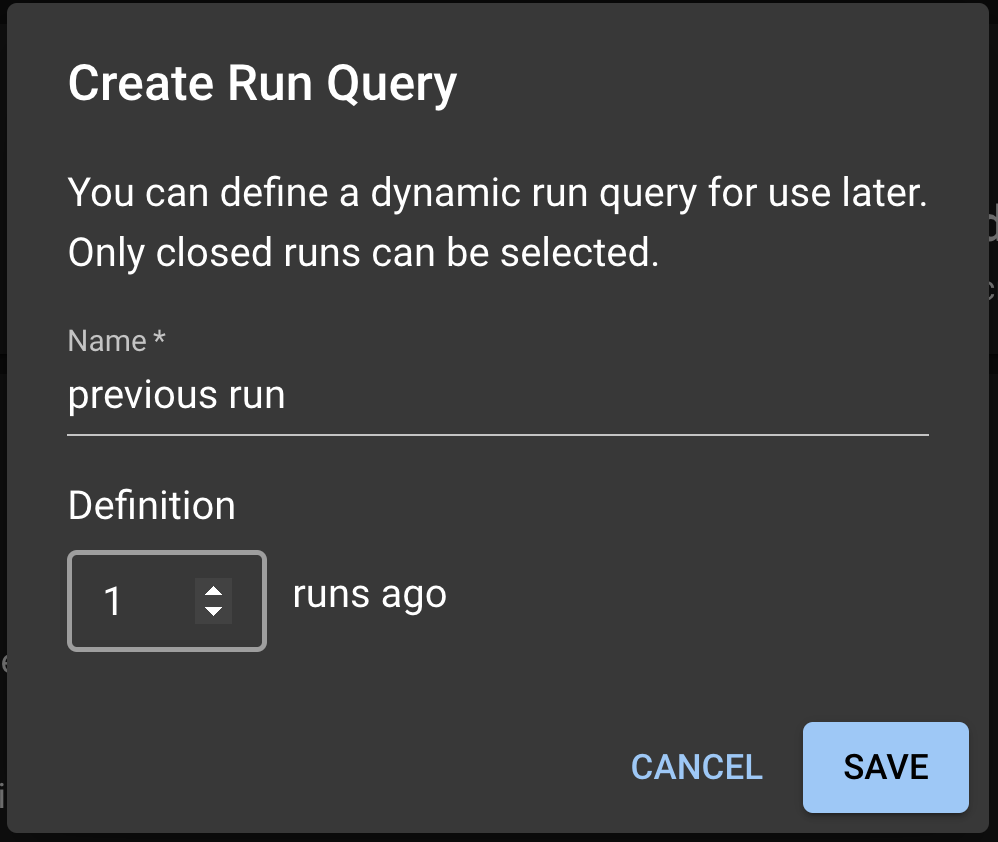
Instead of comparing the newest Run to a fixed Baseline Run, a user might want to dynamically shift the baseline. For example, one might want to compare the new Run to the most recently completed Run. To enable dynamic baseline, user needs to create a Run Query from the Test Config page.
Under the Baseline Run dropdown, select Create run query; this will prompt a Run Query modal. In the model, you can write the name of the Run Query and select the offsetting Run to be used for the dynamic baseline. For example: 1 implies each new Run is tested against the previous uploaded Run.
Click SAVE to save this Run Query. Back in the Test Config page, select the Run Query from the dropdown and click SAVE to save this setting as the dynamic baseline.
set_run_as_baseline
Set a given Run as the Baseline Run in a Project's Test Config
Parameters
Arguments
Description
Manually Running Tests Via UI
You can choose to run tests associated with a project by clicking on the Run Tests button on the project details page. This button will open up a modal that allows you to specify the baseline and experiment runs as well as the tags of the tests you would like to include or exclude from the test session.
Comprehensive testing with Distributional
This is how you test when you are a dbnl expert
When you start work with Distributional (dbnl), you should focus on creating and executing to ask and answer the question "Is my AI-powered app behaving as desired?" As you gain more confidence using dbnl, the full pattern of standard dbnl usage looks as follows:
Execute Production testing at a regular interval (e.g., nightly) on recent app usages
Execute Deployment testing at a regular interval (e.g., weekly) on a fixed dataset
Testing
Tests are the key tool within dbnl for asserting performance and consistency of runs. Possible goals during testing can include:
Asserting that a chosen column meets its minimum desired behavior (e.g., inference throughput);
Asserting that a chosen column has a distribution that roughly matches the baseline reference;
Run
Functions interacting with dbnl
Auto-Test Generation
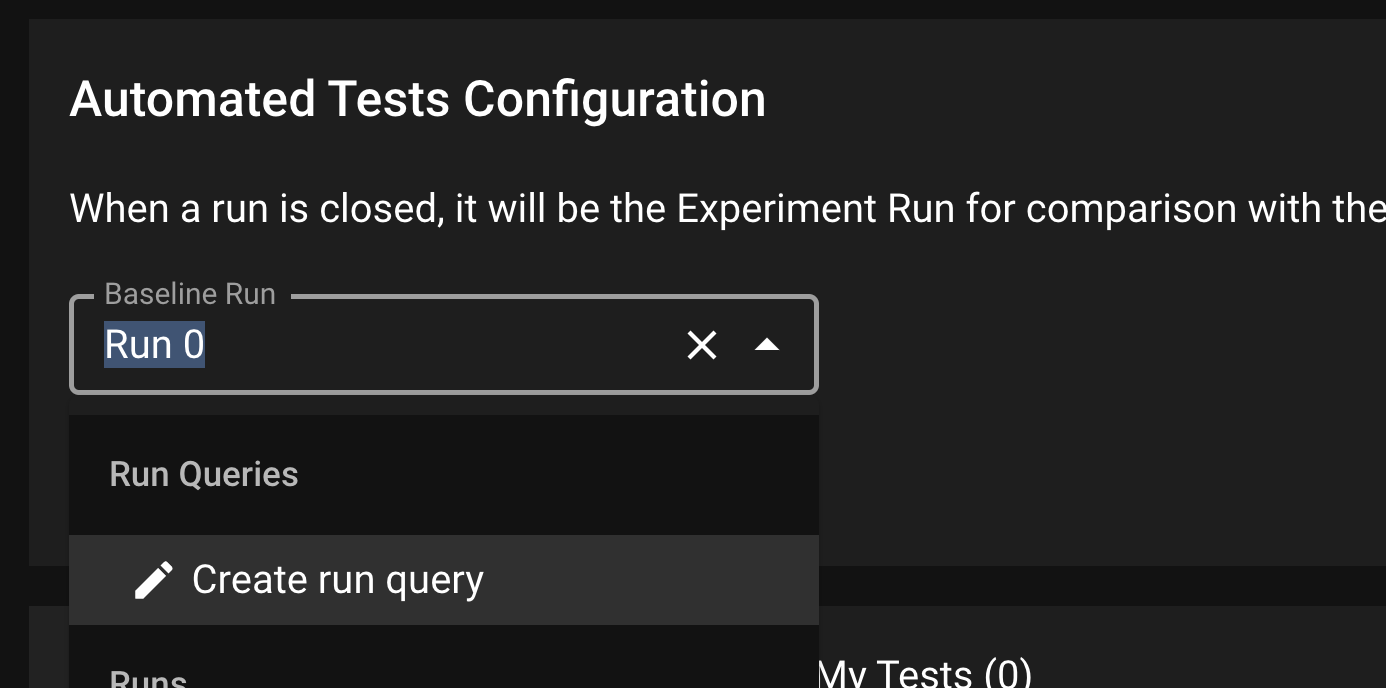
In order to facilitate production testing, Distributional can automatically generate a suite of Tests based on the user’s uploaded data. Distributional studies the Run results data and create the appropriate thresholds for the Tests.
Generate Production Tests
In the Test Config page, click the AUTO-GENERATE TESTS button; this will prompt a modal where the user can select the Run which the tests will be based on. Click Select All to generate tests for all columns or optionally sub-select the columns to generate tests. Click GENERATE TESTS to generate the production tests.
Run Results
Functions related to Column and Scalar data uploaded within a Run.
As a convenience for reporting results and creating a Run, you can also check out
Using Filters
Distributional allows users to apply filters on run data they have uploaded. Applying a filter selects for only the rows that match the filter criteria. The filtered rows can then be visualized or used to create tests.
We will show how filters can be used to explore the data created by the and build filtered tests.
Data
DBNL provides a in Python to organize this data, submit it to our system, and interact with our API. In this section we introduce key objects in the dbnl framework and describe using this SDK to interact with these objects.
Production Testing
What is production testing?
Production testing focuses on the need to regularly check in on the health of an app as it has behaved in the real world. Users want to detect changes in either their AI app behavior or the environment that it is operated in. At Distributional, we help users to confidently answer these questions.
set_run_query_as_baseline
Set a given RunQuery as the Baseline Run in a Project's Test Config
Parameters
Arguments
Description
Test Session
Functions that interact with dbnl
user-defined metadata for remembering the context of a run.
Runs live within a selected project, which serves as an organizing tool for the runs created for a single app.
The structure of a run is defined by its Run Configuration, or RunConfig. This informs dbnl about what information will be stored in each result (the columns) and how the app is organized (the components). A Component is a mechanism for grouping columns based on their role within the app; this information is stored in the run configuration.
Using the row_id functionality within the run configuration, you also have the ability to designate Unique Identifiers – specific columns which uniquely identify matching results between runs. Adding this information enables specific tests of individual result behavior.
The data associated with each run is passed to dbnl through the SDK as a pandas dataframe.
– Can be used to confirm that two quantities are near each other, e.g., that the 90th
less_than – Can be used to confirm that nonparametric statistics are small enough to indicate that two distributions are suitably similar
Choosing a threshold can be simple, or it can be complicated. When the statistic under analysis has easily interpreted values, these thresholds can emerge naturally.
Example: The 90th percentile of the app latency must be less than 123ms.
Here, the statistic is the percentile(EXPERIMENT.latency, 90), and the threshold is “less than 123”.
Example: No result should have more than a 0.098 difference in probability of fraud prediction against the baseline.
Here, the statistic is max(matched_abs_diff(EXPERIMENT.prob_fraud, BASELINE.prob_fraud)) and the threshold is “less than 0.098”.
In situations where nonparametric quantities, like the scaled Kolmogorov-Smirnov statistic, are used to state whether two distributions are sufficiently similar, it can be difficult to identify the appropriate threshold. This is something that may require some trial and error, as well as some guidance from your dedicated Applied Customer Engineer. Please reach out as you would like our support developing thresholds for these statistics.
Research into Adaptive Testing Strategies
Additionally, we are hard at work developing new strategies for adaptively learning thresholds for our customers based on their preferences. If you would like to be a part of this development and beta testing process, please inform your Applied Customer Engineer.
Asserting that no individual results have a severely divergent behavior from a baseline.
In this section, we explore the objects required for testing, methods for creating tests, suggested testing strategies, reviewing/analyzing tests, and best practices.
How does Distributional do production testing?
In the case of production testing, Distributional recommends testing the similarity of distributions of the data related to the AI app between the current Run and a baseline Run. Users can start with the auto-test generation feature to let Distributional generate the necessary production tests for a given Run.
Discover how dbnl manages user permissions through a layered system of organization and namespace roles—like org admin, org reader, namespace admin, writer, and reader.
Users
A user is an individual who can log into a dbnl organization.
Permissions
Permissions are settings that control access to operations on resources within a dbnl organization. Permissions are made up of two components.
Resource: Defines which resource is being controlled by this permission (e.g. projects, users).
Verb: Defines which operations are being controlled by this permission (e.g. read, write).
For example, the projects.read permission controls access to the read operations on the projects resource. It is required to be able to list and view projects.
Roles
A role consists in a set of permissions. Assigning a role to a user gives the user all the permissions associated with the role.
Roles can be assigned at the organization or namespace level. Assigning roles at the namespace level allows for giving users granular access to projects and their related data.
Org Roles
An org role is a role that can be assigned to a user within an organization. Org role permissions apply to resources across all namespaces.
There are two default org roles defined in every organization.
Org admin
The org admin role has read and write permissions for all org level resources making it possible to perform organization management operations such as creating namespaces and assigning users roles.
By default, the first user in an org is assigned the org admin role.
Org reader
The org reader role has read-only permissions to org level resources making it possible to navigate the organization by listing users and namespaces.
By default, all users are assigned the org reader role.
Assigning a User an Org Role
To assign a user an org role, go to ☰ > Settings > Admin > Users, scroll to the relevant user and select the an org role from the dropdown in the Org Role column.
Assigning a user an org role requires having the org admin role.
Namespace Roles
A namespace role is a role that can be assigned to a user within a namespace. Namespace role permissions only apply to resources defined within the namespace in which the role is assigned.
There are three default namespace roles defined in every organization.
Namespace admin
The namespace admin role has read and write permissions for all namespace level resources within a namespace making it possible to perform namespace management operations such as assigning users roles within a namespace.
By default, the creator of a namespace is assigned the namespace admin role in that namespace.
Namespace writer
The namespace admin role has read and write permissions for all namespace level resources within a namespace except for those resources and operations related to namespace management such as namespace role assignments.
By default, all users are assigned the namespace writer role in the default namespace.
(Experimental) Namespace reader
The namespace reader role has read-only permissions for all namespace level resources within a namespace.
This is an experimental role that is available through the API, but is not currently fully supported in the UI.
Assigning a User a Namespace Role
To assign a user a namespace role within a namespace, go to ☰ > Settings > Admin > Namespaces, scroll and click on the relevant namespace and then click + Add User.
Assigning a user a namespace role requires having the org admin role or the namespace admin role in that namespace.
Baseline
Functions that interact with dbnl Baseline concept
The dbnl Run to be set as the Baseline Run in its Project Test Config.
Quick Start
Below is a basic working example that highlights the SDK workflow. If you have not yet installed the SDK, follow these instructions.
import dbnl
import numpy as np
import pandas as pd
num_results = 500
test_data = pd.DataFrame({
"idx": np.arange(num_results),
"age": np.random.randint(5,95, num_results),
"loc": np.random.choice(["NY", "CA", "FL"], num_results),
"churn_gtruth": np.random.choice([True, False], num_results)
})
# example user ml app / model
def churn_predictor(input):
return 1.0 / (1.0 + np.exp(-(input["age"] / 10.0 - 3.5)))
def evaluate_predicton(data):
return (data["churn_score"] > 0.5 and data["churn_gtruth"]) or \
(data["churn_score"] < 0.5 and not data["churn_gtruth"])
test_data["churn_score"] = test_data.apply(churn_predictor, axis=1)
test_data["pred_correct"] = test_data.apply(evaluate_predicton, axis=1)
test_data = test_data.astype({"age": "int", "loc": "category"})
# Use DBNL
dbnl.login(api_token="<COPY_PASTE_DBNL_API_TOKEN>")
proj = dbnl.get_or_create_project(name="example_churn_predictor")
run = dbnl.report_run_with_results(
project=proj,
column_results=test_data,
row_id=["idx"],
)
dbnl-generated alerts regarding highly correlated columns (in depth on a separate screen),
Summary statistics for columns (along with shortcuts to create tests for any statistics of note), and
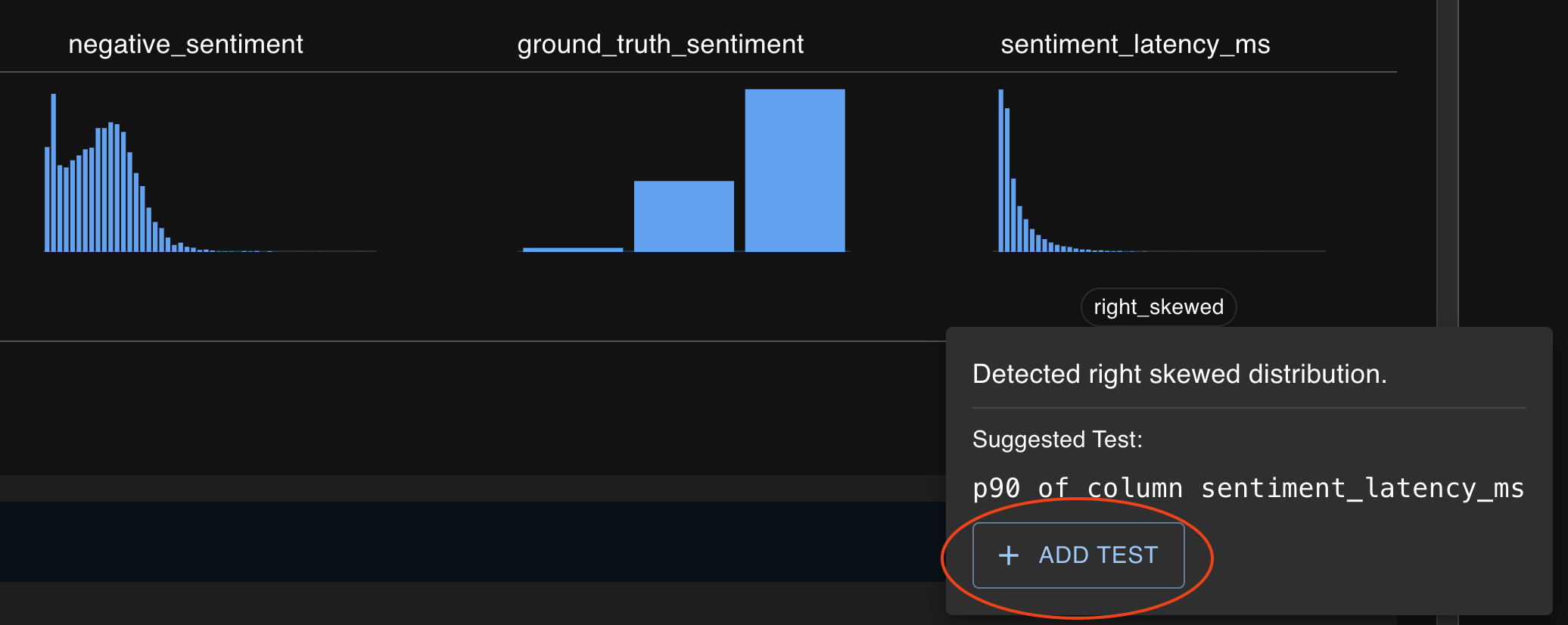
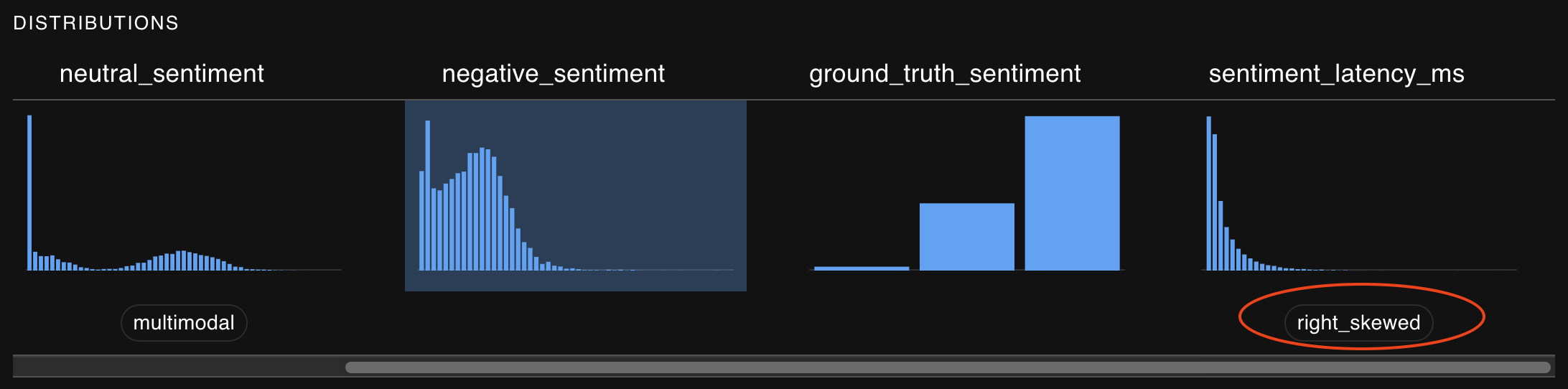
Notable behavior for columns, such as a skewed or multimodal distribution.
At the Run Detail page, you can gain quick insights regarding your app's behavior and add tests on those insights as you desire.
Compare page
At the top of the Run Detail page, there are links to the Compare and Analyze pages, where you can conduct more in depth and customized analysis. You can drive your own analysis at these pages to uncover key insights about your app.
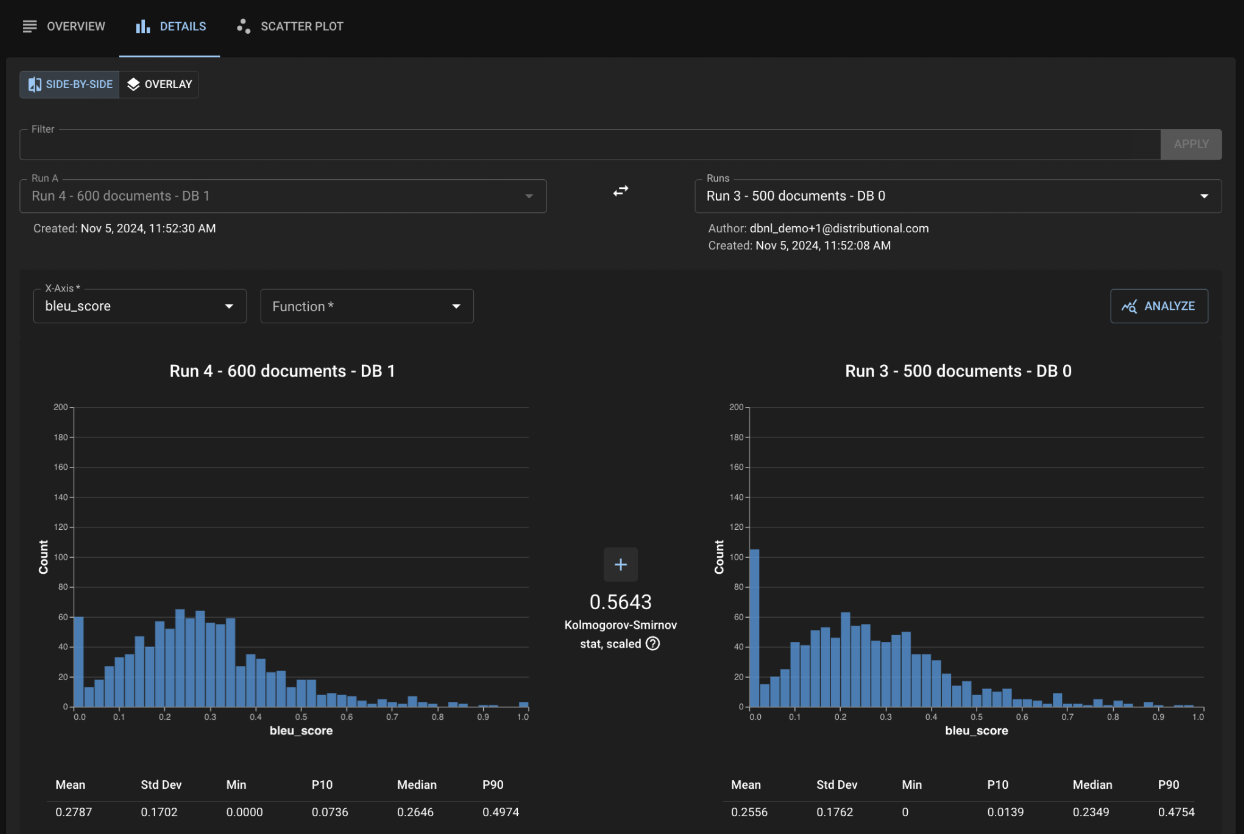
For example, after seeing a failed Test Session in a RAG (Q & A) application, you may visit the Compare page to understand the impact of adding new documents to your vector database. The image below shows a sample Compare page, which reveals a sizable decrease in the population of poorly-retrieved questions (drop in the low bleu value between Baseline and Experiment).
The Compare Page exposes a significant drop in low-performing bleu scores when new documents are added to the vector database.
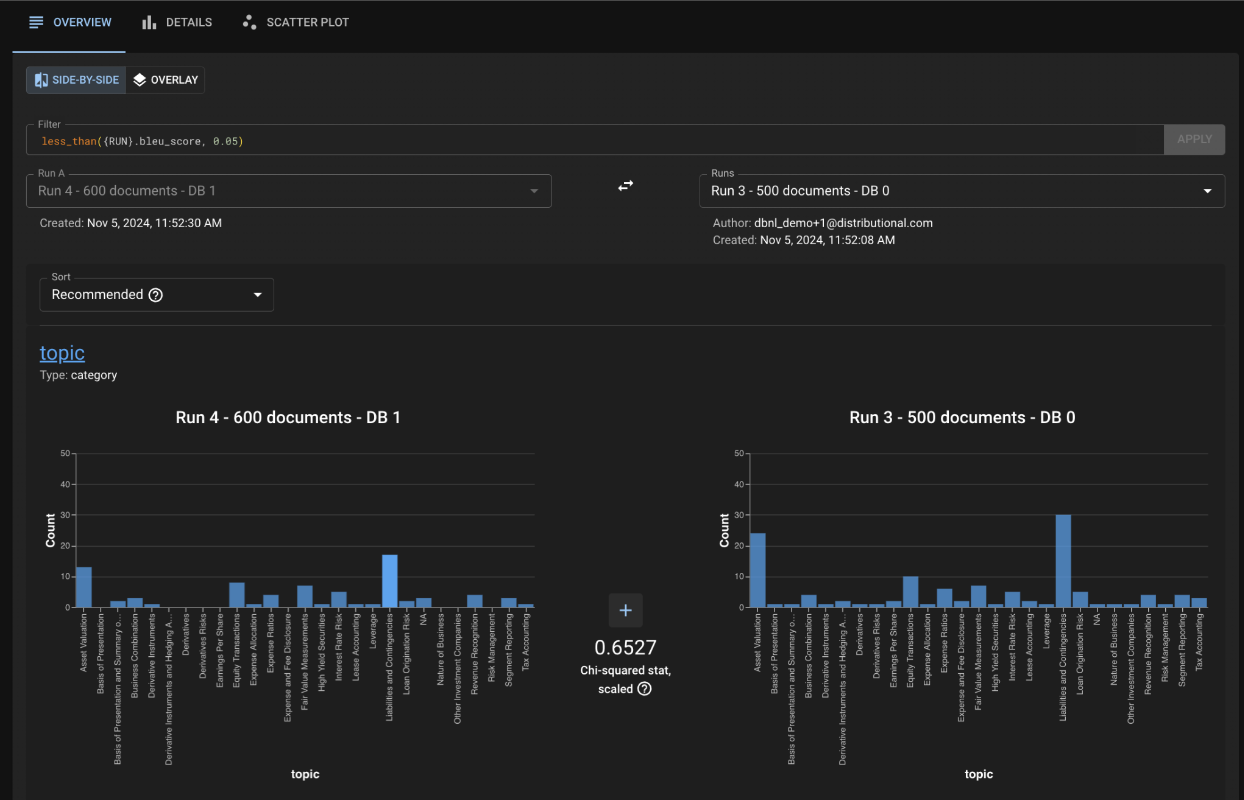
Filtering for those columns (the screenshot below) gives a valuable insight about the impact of the extra documents. You see that, previously, the RAG app was incorrectly retrieving documents from “Liabilities and Contingencies” as well as “Asset Valuations.” Adding the new documents improved your app’s quality, and now you can confidently answer, “Yes, my app’s behavior has changed, and I am satisfied with its new behavior.”
Applying a filter for low bleu score values allows you to identify which documents are being better retrieved with the extra 100 documents in the vector database.
Recalibrate all tests
Click the RECALIBRATE ALL TESTS button at the top right of the Generated Tests table in the Test Session page.
This will take you to the Test Configuration page, where it will prompt you with a modal for the you to select to have all the tests to pass or fail in the future.
Recalibration modal in Test Configuration page
Recalibrate multiple tests
First select the tests you want to recalibrate, then click the RECALIBRATE <#> TESTS button under the Generated Tests tab. This will prompt the same modal for the user to select to have these tests pass or fail in the future.
Organization Resources
Some resources, such as users, are defined at the organization level. Those resources are sometimes referred to as organization resources or org resources.
Namespaces
A namespace is a unit of isolation within a dbnl organization.
Namespace Resources
Most resources, including projects and their related resources, are defined at the namespace level. Resources defined within a namespace are only accessible within that namespace providing isolation between namespaces.
Default Namespace
All organizations include a namespace named default. This namespace cannot be modified or deleted.
By default, users are assigned the namespace reader role in the default namespace.
Switching Namespace
To switch namespace, use the namespace switcher in the navigation bar.
Creating a Namespace
To create a namespace, go to ☰ > Settings > Admin > Namespaces and click the + Create Namespace button.
Creating a namespace requires having the org admin role.
At each of these locations, a test creation drawer will open on the right side of the page with several of the fields pre-populated based on the context of the button.
Example of the Summary Statistics Table
Here, each entry in the summary statistics table (on the Run Detail page) can be used to seed creation of a test for that chosen statistic.
Example of the Mini Charts
If an interesting statistical property is present for a given distribution, you may be alerted to that fact above the mini charts on the Run Detail page.
Expanding out this alert will generate a possible test of interest which can then be edited and saved at the test creation drawer.
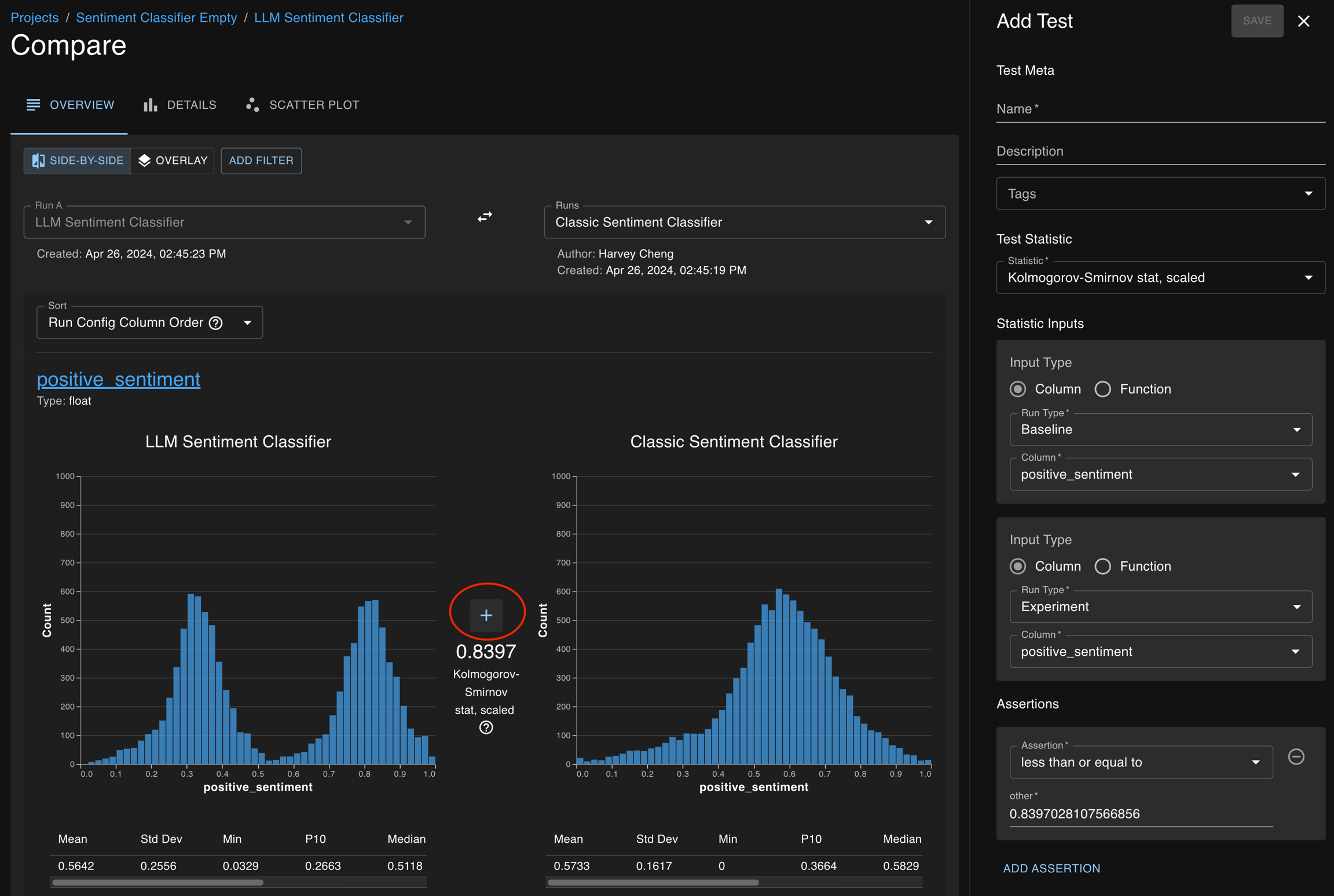
Example on the Compare Page
When two distributions are being studied at the compare page, a suggested nonparametric statistic will be presented to guide potential test creation for asserting consistency of that distribution between runs.
All data accesses are mediated by the API ensuring the enforcement of access controls. For more details on permissions, see Users and Permissions.
Database
Database access is always done through the API with the API enforcing access controls to ensure users only access data for which they have permission.
Object Store
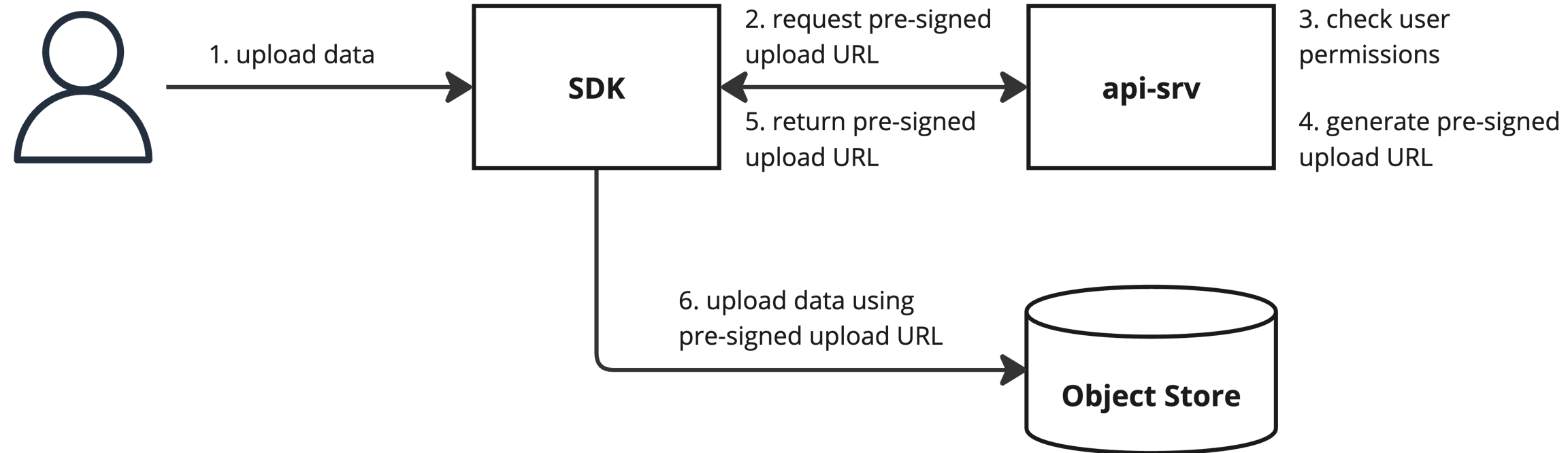
Direct object store access is required to upload or download raw run data using the SDK. Pre-signed URLs are used to provide limited direct access. This access is limited in both time and scope, ensuring only data for a specific run is accessible and that it is only accessible for a limited time.
When uploading or downloading data for a run, the SDK first sends a request for a pre-signed upload or download URL to the API. The API enforces access controls, returning an error if the user is missing the necessary permissions. Otherwise, it returns a pre-signed URL which the SDK then uses to upload or download the data.
Data upload
Uploading data to a run in a given namespace requires write permission to runs in that namespace. Downloading data from a run in a given namespace requires read permission to runs in that namespace.
An EntityExtractor (2 columns) and a SentimentClassifier (4 columns) parsing that data, and
A TradeRecommender (2 columns) taking the Entities and Sentiments and choosing to execute a stock trade.
Tests were created to confirm the satisfactory behavior of the app. We can see that the TradeRecommender seems to be misbehaving, but so is the SentimentClassifier. Because the SentimentClassifier appears earlier in the DAG, we start our triage of these failed tests there.
This DAG suggests that failed tests in the TradeRecommender are likely attributed to the SentimentClassifier.
Setting baseline in SDK
Alternatively, you can also set a Run as baseline using the set_run_as_baseline function.
Close a new run in that project
Executing the close_run command for a new run in that same project will finalize the data, enabling it for use in Tests.
Create Test Session
Execute the create_test_session command, providing your new run as the "experiment". Tests will then use the previously-defined baseline for comparisons.
From the project details page, click configure tests.
Select the baseline run in the dropdown against which you would like new experiment runs to be compared.
Returns
Type
Description
The dbnl RunConfig with the given ID.
Examples
run_config_id
The ID of the dbnl . RunConfig ID starts with the prefix runcfg_ . Run ID can be found at the Run detail page or Project detail page. An error will be raised if there does not exist a RunConfig with the given run_config_id.
Auto-Generate Tests Modal
Once the Tests are generated, you can view them under the Generated Tests section.
Runs in dbnl are created from data produced during the normal operation of your app, such as prompts (inputs) and responses (outputs).
Example Test on mean of absolute difference of toxicity_score
{"name":"test_mean_abs_diff_sentiment","description":"Test mean absolute difference of negative sentiment per result","statistic_name":"mean","statistic_params":{},"assertion":{"name":"less_than_or_equal_to","params":{"other":0.05,},},"statistic_inputs":[{"select_query_template":{"select":"abs({EXPERIMENT}.toxicity_score - {BASELINE}.toxicity_score)"}},],}
Example Test on signed difference of mean of toxicity_score
{"name":"test_lower_toxicity_score","description":"Test mean of the toxicity score is lower than baseline","statistic_name":"diff_mean","statistic_params":{},"assertion":{"name":"less_than","params":{"other":-0.1,},},"statistic_inputs":[{"select_query_template":{"select":"{EXPERIMENT}.toxicity_score"}},{"select_query_template":{"select":"{BASELINE}.toxicity_score"}},],}
Example test on absolute difference of medians of positive_sentiment_score
{"name":"median_sentiment_similar","description":"Test the absolute difference of median on sentiment","statistic_name":"abs_diff_median","statistic_params":{},"assertion":{"name":"close_to","params":{"other":0.0,"tolerance":0.01,},},"statistic_inputs":[{"select_query_template":{"select":"{EXPERIMENT}.positive_sentiment_score"}},{"select_query_template":{"select":"{BASELINE}.positive_sentiment_score"}},],}
Test That Columns Are Similarly Distributed
One general approach to test if two columns are similarly distributed is using a nonparametric statistic. DBNL offers two such statistics: scaled_ks_stat for testing ordinal distributions and scaled_chi2_stat for testing nominal distributions.
Example Test Spec
{"name":"discrepancy_of_text_coherence_score",
Example test on discrepancy of distribution of coherence_score
report_scalar_results
Report all scalar results to dbnl
Parameters
Arguments
Description
run
Limitations
All data should be reported to dbnl at once. Calling dbnl.report_scalar_results more than once will overwrite the previously uploaded data.
Once a Run is . You can no longer call report_scalar_results to send data to DBNL.
Examples
Test Templates
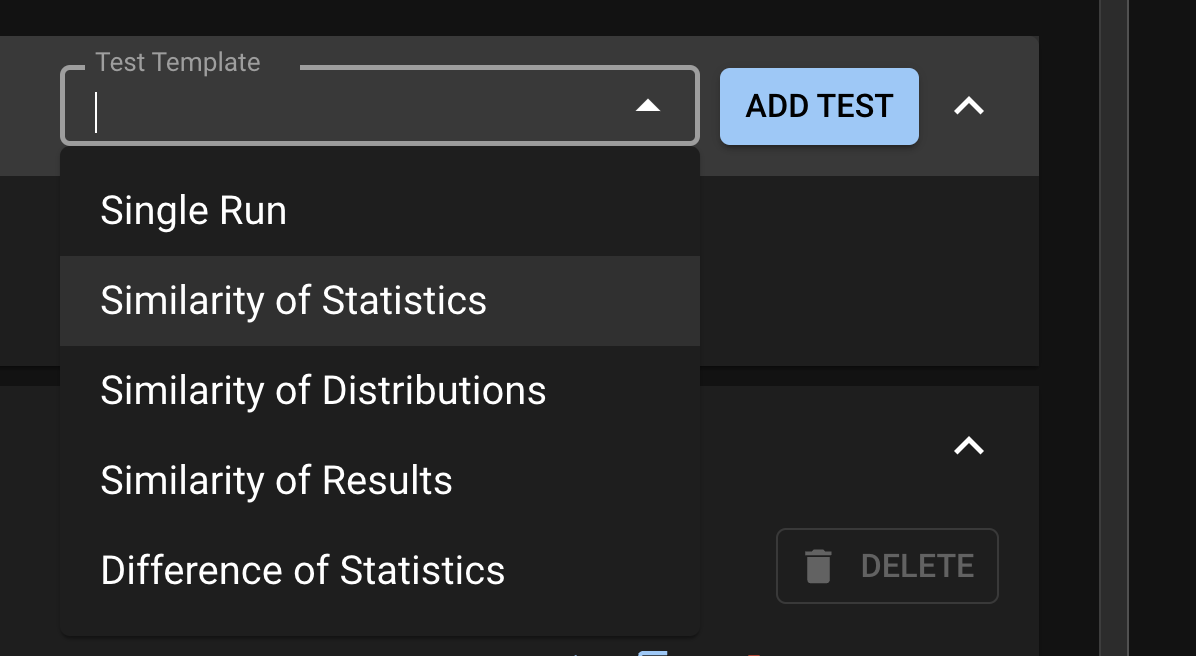
Test templates are macros for basic test patterns recommended by Distributional. It allows the user to quickly create tests from a builder in the UI. Distributional provides five classes of Test Templates.
Single Run: These are parametric statistics of a column.
Similarity of Statistics: These test if the absolute difference of a statistic of a column between two runs is less than a threshold.
: These test if the column from two different runs are similarly distributed is using a nonparametric statistic.
: These are tests on the row-wise absolute difference of result
: These tests the signed difference of a statistic of a column between two runs
Creating Test from Test Templates
From the Test Configuration page, click the Test Template dropdown under My Tests.
Select from one of the five options and click ADD TEST. A Test Creation drawer will appear and the user can edit the statistic, column, and assertion that they desire. Note that each Test Template has a limited set of statistics that it supports.
Reviewing and recalibrating automated Production tests
Directing dbnl to execute the tests you want
A key part of the dbnl offering is the creation of automated Production tests. After their creation, each Test Session offers you the opportunity to Recalibrate those tests to match your expectations. For GenAI users, we think of this as the opportunity to “codify your vibe checks” and make sure future tests pass or fail as you see fit.
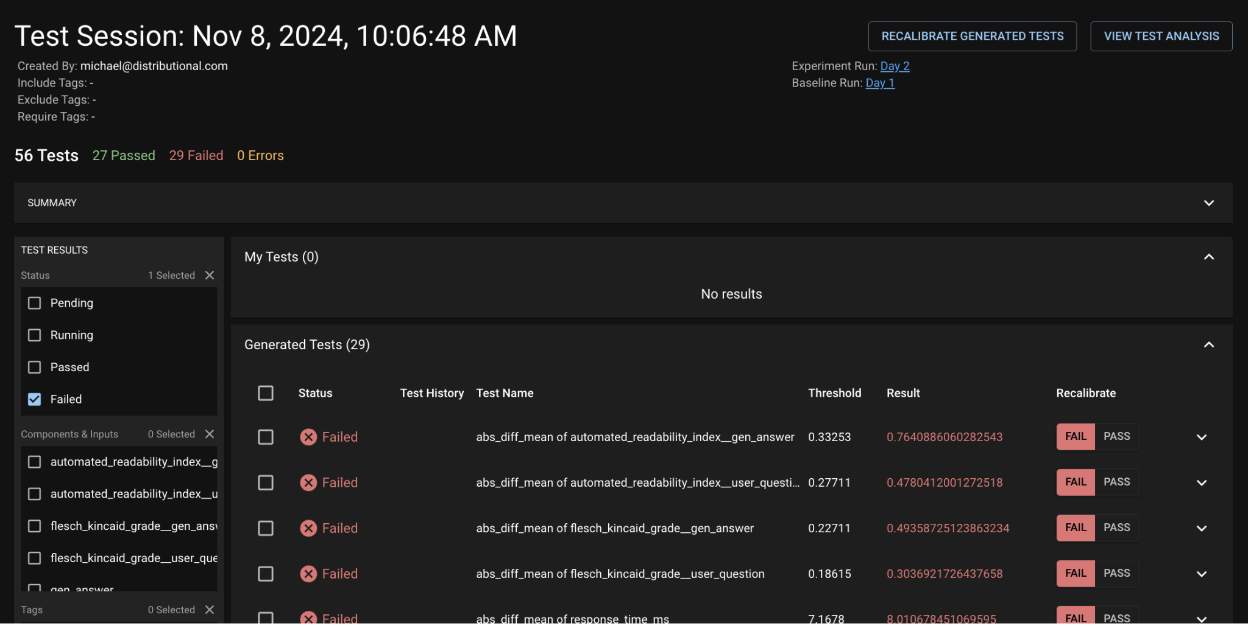
The previous section showed a brief snapshot of a test session to understand how your app has been performing. Our UI also provides advanced capabilities that allow you to dig deeper into our automated Production tests. Below we can see a sample Test Session with a suite of dbnl-generated tests. The View Test Analysis button lets you dig deeper into any subset of tests – in this image, we have subselected only the failed tests to try and learn whether there is something sufficiently concerning that should fail.
You can filter to only the failed tests to better understand how the app is violating test expectations and whether the tests should be recalibrated to pass in the future.
In the subsequent page, there is a Notable Results tab where dbnl provides a subset of app usages that we feel are the most extremely different between the Baseline and Experiment run. When you leaf through these Question/Answer pairs, we do not see anything terribly frightening— just the standard randomness of LLMs. As such, on the original page, I choose to Recalibrate Generated Tests to pass, and I will not be alerted in the future.
After subselecting tests, or selecting the full Test Session, dbnl provides a list of Notable Results that demonstrate the largest devioation from previously observed behavior.
We recommend that you always inspect the first 4-7 test sessions for a new Project. This helps ensure that the tests effectively incorporate the nondeterministic nature of your app. After those initial Recalibration actions, you can define notifications to only trigger when too many tests fail.
get_results
Retrieve results from dbnl
Parameters
Arguments
Description
run
Returns
Type
Description
You can only call get_results after the run is .
Examples
get_column_results
Retrieve results from dbnl
Parameters
Arguments
Description
run
Returns
Type
Description
You can only call get_column_results after the run is .
Examples
get_run_config_from_latest_run
Retrieve a dbnl RunConfig from the most recent Run in a Project
Incorporate your expertise alongside our automated tests
While we expect everyone to use our automated Production test creation capabilities, we also recognize that many users bring significant expertise to their testing experience. Distributional provides you a suite of test creation tools and patterns that match your needs.
Most tests in dbnl are statistically-motivated to better measure and study fundamentally nondeterministic AI-powered apps. Means, percentiles, Kolmogorov-Smirnov, and other statistical entities are provided to allow you to study the behavior of your app as you would like. We provide templates to guide you through our suggested testing strategies.
Menu of common testing strategies that are supported by templates in dbnl.
The manual test creation process can be configured in any of three locations: in the main web UI test configuration page, through shortcuts to the test drawer scattered throughout the web UI, or through the SDK. This gives you the flexibility to systematically control test generation, or quickly respond to insights for which you would like to test in the future.
The core testing capability is supplemented by the ability to define filters on tests. These filters empower you to test for consistency within subsets of your user base. Filtering also allows you to test for bias in your app and help triage cases of undesired behavior.
Learn more about how to create your own tests .
copy_project
Copy a dbnl Project with a new name and description
Parameters
Arguments
Description
project
Returns
Type
Description
Examples
get_or_create_project
Retrieve the specified dbnl Project or create a new one if it does not exist
Parameters
Arguments
Description
name
Description cannot be updated with this function.
Returns
Type
Description
Examples
report_column_results
Report all column results to dbnl
Parameters
Arguments
Description
run
Limitations
All data should be reported to dbnl at once. Calling dbnl.report_column_results more than once will overwrite the previously uploaded data.
Once a Run is . You can no longer call report_column_results to send data to dbnl.
Export a dbnl Project alongside its Test Specs and Tags as a JSON object
Parameters
Arguments
Description
Filters in the Compare Page
Filters can be written at the top of the compare page, which is accessible from the project detail page. Users write filters to select for only the rows they wish to visualize / inspect.
Below is a list of DBNL defined functions that can be used in filter expressions:
function name
aliases
description
login
Authenticate dbnl SDK
Setup dbnl SDK to make authenticated requests. After login is run successfully, the dbnl client will be able to issue secure and authenticated requests against hosted endpoints of the dbnl service.
dbnl.login must be run before any other functions in the DBNL workflow
Filters in Tests
Filters can also be used to specify a sub-selection of rows in runs you would like to include in the test computation.
For example, our goal could be to create a test that asserts that, for rows where the loc column is ‘NY’, the absolute difference of means of the correct churn predictions is <= 0.2 between baseline and experiment runs.
We will walk through how this can be accomplished:
1. Navigate to the Project Detail page and click on “Configure Tests”.
Click Add Test on the Test Configuration page. Don’t forget to also set a baseline run for automated test configuration.
Getting Started
Installing the Python SDK and Accessing Distributional UI
For getting access to the Distributional platform, .
import dbnl
dbnl.login()
proj1 = dbnl.get_or_create_project(name="test_p1")
runcfg1 = dbnl.create_run_config(project=proj1, columns=[{"name": "error", "type": "float"}])
# Retrieving the RunConfig by ID
runcfg2 = dbnl.get_run_config(run_config_id=runcfg1.id)
assert runcfg1.id == runcfg2.id
# DBNLRunConfigNotFoundError: A DBNL RunConfig with id not_exist does not exist
run_config3 = dbnl.get_run_config(run_config_id="runcfg_not_exist")
The name for the dbnl Project. A new Project will be created with this name if there does not exist a Project with this name already. If there does exist a project with this name, the pre-existing Project will be returned.
description
An optional description for the dbnl Project, defaults to None. Description is limited to 255 characters.
A new Project will be created with the specified name if there does not exist a Project with this name already. If there does exist a project with the name, the pre-existing Project will be returned.
The dbnl Run that the results will be reported to.
data
A pandas DataFrame with all the results to report to dbnl. The columns of the DataFrame must match the columns described in the RunConfig associated with the Run.
The ID of the dbnl Run. Run ID starts with the prefix run_ . Run ID can be found at the Run detail page. An error will be raised if there does not exist a Run with the given run_id.
import dbnl
dbnl.login()
proj_1 = dbnl.create_project(name="test_p1")
# DBNLConflictingProjectError: A DBNL Project with name test_p1 already exists.
proj_2 = dbnl.create_project(name="test_p1")
import dbnl
import pandas as pd
dbnl.login()
proj1 = dbnl.get_or_create_project(name="test_p1")
data = pd.DataFrame({"error": [0.11, 0.33, 0.52, 0.24]})
run = dbnl.report_run_with_results(
project=proj,
column_results=data,
scalar_results={"rmse": 0.37}
)
downloaded_scalars = dbnl.get_scalar_results(run=run)
import dbnl
dbnl.login()
proj_1 = dbnl.create_project(name="test_p1")
proj_2 = dbnl.get_project(name="test_p1")
# Calling get_project will yield same Project object
assert proj_1.id == proj_2.id
# DBNLProjectNotFoundError: A dnnl Project with name not_exist does not exist
proj_3 = dbnl.get_project(name="not_exist")
import dbnl
dbnl.login()
proj1 = dbnl.get_or_create_project(name="test_p1")
runcfg1 = dbnl.create_run_config(project=proj1, columns=[{"name": "error", "type": "float"}])
run1 = dbnl.create_run(project=proj1, run_config=runcfg1)
# Retrieving the Run by ID
run2 = dbnl.get_run(run_id=run1.id)
assert run1.id == run2.id
# DBNLRunNotFoundError: A DBNL Run with id run_0000000 does not exist.
run3 = dbnl.get_run(run_id="run_0000000")
class Project:
id: str
name: str
description: Optional[str] = None
"description":"Test the nonparametric discrepancy of the coherence score distributions",
"statistic_name":"scaled_ks_stat",
"statistic_params":{},
"assertion":{
"name":"less_than_or_equal_to",
"params":{
"other":0.25,
},
},
"statistic_inputs":[
{
"select_query_template":{
"select":"{EXPERIMENT}.coherence_score"
}
},
{
"select_query_template":{
"select":"{BASELINE}.coherence_score"
}
},
],
}
Returns
Type
Description
dict[str, Any]
JSON object representing the Project. Example:
Examples
project
The to export as json.
Logical AND operation of two or more boolean columns
or
Logical OR operation of two or more boolean columns
not
Logical NOT operation of a boolean column
less_than
['lt']
Computes the element-wise less than comparison of two columns. input1 < input2
less_than_or_equal_to
['lte']
Computes the element-wise less than or equal to comparison of two columns. input1 <= input2
greater_than
['gt']
Computes the element-wise greater than comparison of two columns. input1 > input2
greater_than_or_equal_to
['gte']
Computes the element-wise greater than or equal to comparison of two columns. input1 >= input2
equal_to
['eq']
Computes the element-wise greater than or equal to comparison of two columns
Here is an example of a more complicated filter that selects for rows that have their loc column equal to the string 'NY' and their respective churn_score > 0.9:
Use single quotes ' for filtering of string variables.
and
Parameters
Arguments
Description
api_token
The API token used to authenticate your DBNL account. You can generate your API token at (also, see ). If none is provided, theDBNL_API_TOKEN will be used by default.
namespace_id
Namespace ID to use for the session; available namespaces can be found with get_my_namespaces().
api_url
The base url of the Distributional API. For SaaS users, set this variable to api.dbnl.com. For other users, please contact your sys admin.
app_url
Examples
Create the test with the filter specified on the baseline and experiment run.
Filter for the baseline Run:
Filter for the experiment Run:
4. You can now see the new test in the Test Configuration Page. When new data is uploaded, this test will automatically run and compare the new run (as experiment) against the selected baseline run.
When new run data is uploaded, this test will run automatically and use the defined filters to sub-select for the rows that have the loc column equal to ‘NY’.
The full Test Spec in JSON format is shown below.
equal_to({BASELINE}.loc, 'NY')
equal_to({EXPERIMENT}.loc, 'NY')
The dbnl SDK supports Python versions 3.9-3.12. You can install the latest release of the SDK with the following command on Linux or macOS, install a specific release, and install :
1. Latest Stable Release
To install the latest stable release of the dbnl package:
2. Specific Release
To install a specific version (e.g., version 0.19.1):
3. Installing with the eval Extra
The dbnl.eval extra includes additional features and requires an external spaCy model.
3.1. Install the Required spaCy Model
To install the required en_core_web_sm pretrained English-language NLP model model for spaCy:
3.2. Install dbnl with the eval Extra
To install dbnl with evaluation extras:
If you need a specific version with evaluation extras (e.g., version 0.19.1):
Accessing the Distributional UI and API token
You should have already received an invite email from the Distributional team to create your account. If that is not the case, please reach out to your Distributional contact. You can access your token at https://app.dbnl.com/tokens (which will prompt you to login if you are not already).
We recommend setting your API token as an environment variable, see below.
Environment Variables
DBNL has three reserved environment variables that it reads in before execution.
Variable Name
Description
DBNL_API_TOKEN
The API token used to authenticate your dbnl account. You can generate your API token at
DBNL_API_URL
The base url of the Distributional API. For SaaS users, set this variable to api.dbnl.com. For other users, please contact your sys admin.
DBNL_APP_URL
An optional base url of the Distributional app. If this variable is not set, the app url is inferred from the DBNL_API_URL variable. For on-prem users, please contact your sys admin if you cannot reach the Distributional UI.
Linux/Mac OS Set Up
Run the following commands in your terminal. Make sure to wrap the API token in quotes.
To confirm that the dbnl API Token is set in your environment, run the following command and verify its output is the correct token.
Start evaluating Tests associated with a Run. Typically, the Run you just completed will be the "Experiment" and you'll compare it to some earlier "Baseline Run".
The Run must already have Results reported and be closed before a Test Session can begin.
A Run must be closed for all to be shown on the UI.
Parameters
Arguments
Description
Managing Tags
Suppose we have the following Tests with the associated Tags in our Project
Test1 with tags ["A", "B"]
Test2 with tags ["A"]
Test3 with tags ["B"]
dbnl.create_test_session(..., include_tags=["A", "B"]) will trigger Tests 1, 2, 3 to be executed.
dbnl.create_test_session(..., require_tags=["A", "B"]) will only trigger Test 1.
dbnl.create_test_session(..., exclude_tags=["A"]) will trigger Test 3.
dbnl.create_test_session(..., include_tags=["A"], exclude_tags=["B"]) will trigger Test 2.
Examples
Basic example
Using a Run Query as a Baseline
When Baseline Run has already been set
Run-Level Data
Overview
The Scalars feature allows for the upload, storage and retrieval of individual datums, ie. scalars, for every Run. This is contrary to the Columns feature, which allows for the upload of tabular data via Results.
import dbnl
# when login() is called without specifying a token,
# it will use the `DBNL_API_TOKEN` env var
dbnl.login()
# login() can be called with a specific API Token
dbnl.login(api_token="YOUR_TOKEN_AAAA_BBBB_CCCC_DDDD")
{
"name": "abs diff of mean of correct churn preds of NY users is within 0.2",
"statistic_name": "abs_diff_mean",
"statistic_params": {},
"assertions": [
{
"name": "less_than_or_equal_to",
"params": {
"other": 0.2
},
}
],
"statistic_inputs": [
{
"select_query_template": {
"select": "{BASELINE}.pred_correct",
"filter": "equal_to({BASELINE}.loc, 'NY')"
}
},
{
"select_query_template": {
"select": "{EXPERIMENT}.pred_correct",
"filter": "equal_to({EXPERIMENT}.loc, 'NY')"
}
},
],
}
echo 'export DBNL_API_TOKEN="copy_paste_dbnl_api_token"'| tee -a ~/.zshrc || tee -a ~/.bashrc
echo 'export DBNL_API_URL="api.dbnl.com"'| tee -a ~/.zshrc || tee -a ~/.bashrc
exec "$SHELL"
An optional base url of the Distributional app. If this variable is not set, the app url is inferred from the DBNL_API_URL variable. For on-prem users, please contact your sys admin if you cannot reach the Distributional UI.
The dbnl Project that this Run will be associated with.
column_data
A pandas DataFrame with all the column results to report to dbnl. If run_config_id is provided, the columns of the DataFrame must match the columns described in the RunConfig.
scalar_data
A dict or pandas DataFrame with all the scalar results to report to dbnl. If run_config_id is provided, the key of the dict must match the scalars described in the RunConfig.
display_name
An optional display name for the Run. Display names do not have to be unique.
row_id
An optional list of the column names that can be used as unique identifiers.
run_config_id
ID of the RunConfig to use for the Run, defaults to None. If provided, the RunConfig is used as is and the results are validated against it. If not provided, a new Run Config is inferred from the column_data.
metadata
Any additional key-value pairs information the user wants to track.
{
"project": {
"name": "My Project",
"description": "This is my project."
},
"tags": [
{
"name": "my-tag",
"description" :"This is my tag."
}
],
"test_specs": [
{
"assertion": { "name": "less_than", "params": { "other": 0.5 } },
"description": "Testing the difference in the example statistic",
"name": "Gr.0: Non Parametric Difference: Example_Statistic",
"statistic_inputs": [
{
"select_query_template": {
"filter": null,
"select": "{EXPERIMENT}.Example_Statistic"
}
},
{
"select_query_template": {
"filter": null,
"select": "{BASELINE}.Example_Statistic"
}
}
],
"statistic_name": "my_stat",
"statistic_params": {},
"tag_names": ["my-tag"]
}
]
}
Example Use Case
Your production testing workflow involves the upload of results to Distributional in the form of model inputs, outputs, and expected outcomes for a machine learning model. Using these results you can calculate aggregate metrics, for example F1 score. The Scalars feature allows you to upload the aggregate F1 score that was calculated for the entire set of results.
Uploading Scalars
Uploading Scalars is similar to uploading Results. First you must define the set of Scalars to upload in your RunConfig, for example:
Next, create a run and upload results:
Note: dbnl.report_scalars accepts both a dictionary and a single-row Pandas DataFrame for the data argument.
Finally you must close the run.
Navigate to the Distributional app in your browser to view the uploaded Run with Scalars.
Creating Tests on Scalars
Tests can be defined on Scalars in the same way that tests are defined on Columns. For example, say that you would like to ensure some minimum acceptable performance criteria like "the F1 score must always be greater than 0.8". This test can be defined in the Distributional platform as follows:
assert scalar({EXPERIMENT}.f1_score) > 0.8
Writing a test for minimum performance using the Distributional app.
You can also test against a baseline Run. For example, we can write the test "the F1 score must always be greater than or equal to the baseline Run's F1 score" in Distributional as:
Writing a regression test using the distributional app.
Viewing and Downloading Scalars
You can view all of the Scalars that were uploaded to a Run by visiting the Run details page in the Distributional app. The Scalars will be visible in a table near the bottom of that page.
Scalar data viewable from the Run page on the Distributional app.
Scalars can also be downloaded using the Distributional SDK.
Scalars downloaded via the SDK are single-row Pandas DataFrames.
Scalar Broadcasting
The Distributional expression language supports Scalars, as shown in the above examples. Scalars are identical to Columns in the expression language. When you define an expression that combines Columns and Scalars, the Scalars are broadcast to each row. Consider a Run with the following data:
When the expression {RUN}.column_data + {RUN}.scalar_data is applied to this Run, the result will be calculated as follows:
column_data
scalar_data
column_data + scalar-data
1
10
11
2
10
12
Scalar broadcasting can be used to implement tests and filters that operate on both Columns and Scalars.
Statistics with Scalars
Tests are defined in Distributional as an assertion on a single value. The single value for the assertion comes from a Statistic.
Distributional has a special "scalar" Statistic for defining tests on Scalars. This is demonstrated in the above examples. The "scalar" statistic should only be used with a single expression input, where the result of that singular expression is a single value. The "scalar" Statistic will fail if the provided input resolves to multiple values.
Any other Statistic will reduce the input collections to a single value. In this case Distributional will treat a Scalar as a collection with a single value when computing the Statistic. For example, computing max({RUN}.my_statistic) is equivalent to scalar({RUN}.my_statistic), because the maximum of a single value is the value itself.
column_data
A with all the column results to report to DBNL. The columns of the DataFrame must match the columns described in the associated with the Run.
scalar_data
A dict or pandas Dataframe with all the scalar results to report to DBNL. The key of the dict must match the scalars described in the associated with the Run.
report_results is the equivalent of calling both report_column_results and report_scalar_results .
Limitations
All data should be reported to dbnl at once. Calling dbnl.report_results more than once will overwrite the previously uploaded data.
Once a Run is closed. You can no longer call report_results to send data to DBNL.
Examples
run
The DBNL that the results will be reported to.
The ID of the RunConfig. RunConfig ID starts with the prefix runcfg_
project_id
str
The ID of the this RunConfig is associated with.
columns
list[dict[str, str]]
A list of column schema specs for the uploaded data, required keys name and type, optional key component and description. Example:
See the section on the dbnl.create_run_config page for more information.
scalars
list[dict[str, str]]
An optional list of scalar schema specs for the uploaded scalar data, required keys name and type, optional key component, description and greater_is_better. type can be int, float, category, boolean, or string.
description
str
An optional description of the RunConfig. Descriptions are limited to 255 characters.
display_name
str
An optional display name of the RunConfig.
row_id
list[str]
An optional list of the column names that are used as unique identifiers.
components_dag
dict[str, list[str]]
An optional dictionary representing the direct acyclic graph (DAG) of the specified components. Every component listed in the columns schema is present incomponents_dag.
is a string that indicates the source of the data. e.g. "component" : "sentiment-classifier" or "component" : "fraud-predictor". Specified components must be present in the
components_dag
dictionary.
greater_is_better
is a boolean that indicates if larger values are better than smaller ones. False indicates smaller values are better. None indicates no preference. An example RunConfig scalars:
Test That a Given Distribution Has Certain Properties
A common type of test is testing whether a single distribution contains some property of interest. Generally, this means determining whether some statistics for the distribution of interest exceeds some threshold. Some examples of this can be testing the toxicity of a given LLM or the latency for the entire AI-powered application.
This is especially common for development testing, where it is important to test if a proposed app reaches the minimum threshold for what is acceptable.
Example Test Spec
Example Test on 95th percentile of app_latency_ms
{"name":"p95_app_latency_ms","description":"Test the 95th percentile of latency in miliseconds","statistic_name":"percentile","statistic_params":{"percentage":0.95},"assertion":{"name":"less_than_or_equal_to","params":{"other":180.0,},},"statistic_inputs":[{"select_query_template":{"select":"{EXPERIMENT}.app_latency_ms"}},],}
The dbnl that this Run will be associated with. Two Runs with the same RunConfig can be compared in the web UI and associated in Tests. The associated RunConfig must be from the same Project.
display_name
An optional display name for the Run. Display names do not have to be unique.
metadata
Any additional key-value pairs information the user wants to track.
Column names can only be alphanumeric characters and underscores.
Supported Types
The following type supported as type in column schema
type
Notes
Components
The optional component key is for specifying the source of the data column in relationship to the AI/ML app subcomponents. Components are used in visualizing the .
Components DAG
The components_dag dictionary specifies the topological layout of the AI/ML app. For each key-value pair, the key represents the source component, and the value is a list of the leaf components. The following code snippet describes the DAG shown above.
A list of column schema specs for the uploaded data, required keys name and type, optional key component, description and greater_is_better. type can be int, float, category, boolean, or string. component is a string that indicates the source of the data. e.g. "component" : "sentiment-classifier" or "component" : "fraud-predictor". Specified components must be present in the components_dag dictionary. greater_is_better is a boolean that indicates if larger values are better than smaller ones. False indicates smaller values are better. None indicates no preference.
Example:
NOTE: scalars is available in SDK v0.0.15 and above.
A list of scalar schema specs for the uploaded data, required keys name and type, optional key component, description and greater_is_better. type can be int, float, category, boolean, or string. component is a string that indicates the source of the data. e.g. "component" : "sentiment-classifier" or "component" : "fraud-predictor". Specified components must be present in the components_dag dictionary. greater_is_better is a boolean that indicates if larger values are better than smaller ones. False indicates smaller values are better. None indicates no preference. An example RunConfig scalars: scalars=[{"name": "accuracy", "type": "float", "component": "fraud-predictor"}, {"name": "error_type", "type": "category"}]
Scalar schema is identical to column schema.
description
An optional description of the RunConfig, defaults to None. Descriptions are limited to 255 characters.
display_name
An optional display name of the RunConfig, defaults to None. Display names do not have to be unique.
row_id
An optional list of the column names that can be used as unique identifiers, defaults to None.
components_dag
An optional dictionary representing the direct acyclic graph (DAG) of the specified components, defaults to None. Every component listed in the columns schema must be present in the components_dag. Example: components_dag={"fraud-predictor": ["threshold-decision"], 'threshold-decision': []}
See the components DAG section below for more information.