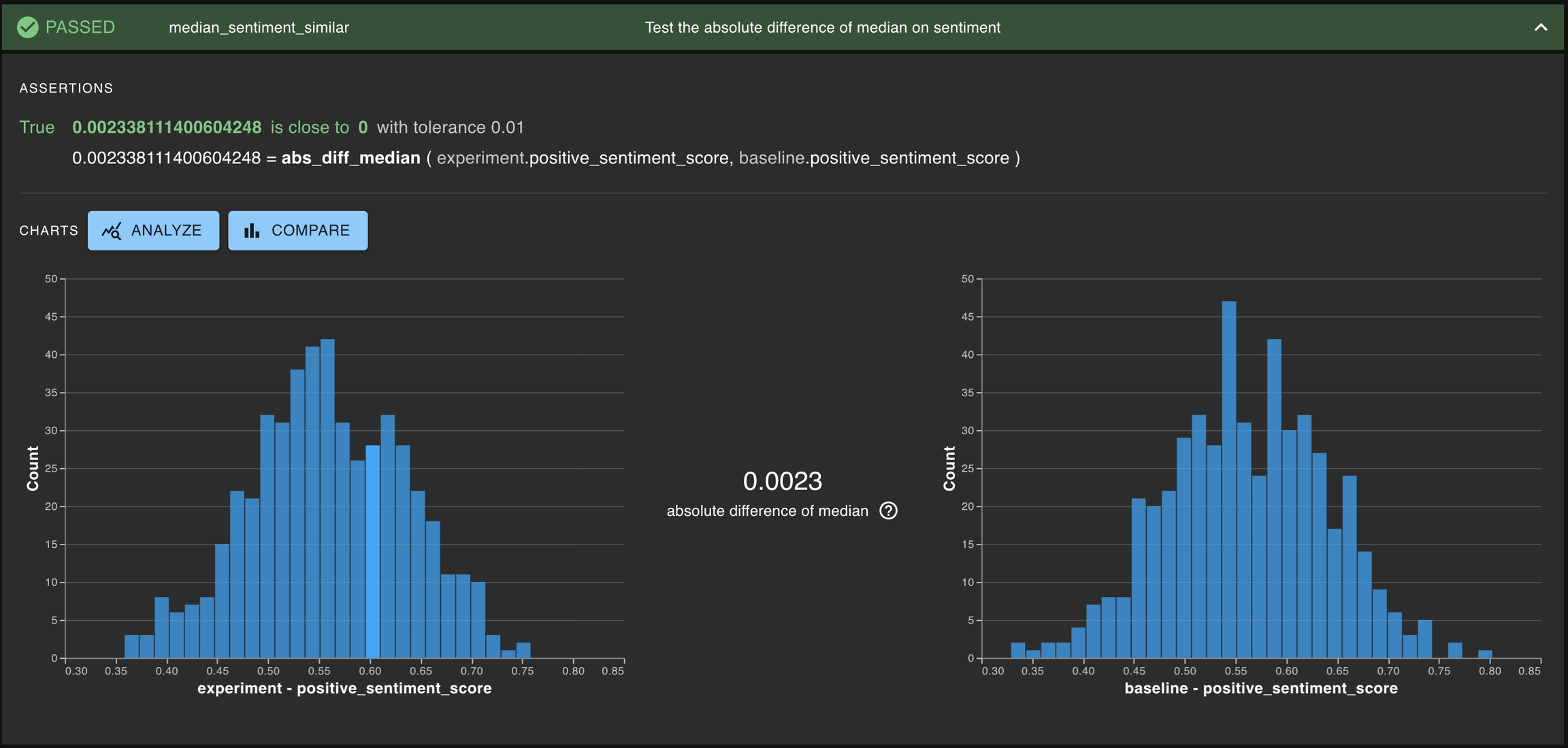
Another type of test is testing if a particular statistic is similar for two different distributions. For example, this can be testing if the absolute difference of medians of sentiment score between the experiment run and the baseline run is small — that is, the scores are close to one another.
Like in traditional software testing, it is paramount to come up with a testing strategy that has both breadth and depth. Such a set of tests gives confidence that the AI-powered app is behaving as expected, or it alerts you that the opposite may be true.
To build out a comprehensive testing strategy it is important to come up with a series of assertions and statistics on which to create tests. This section explains several goals when testing and how to create tests to assert desired behavior.
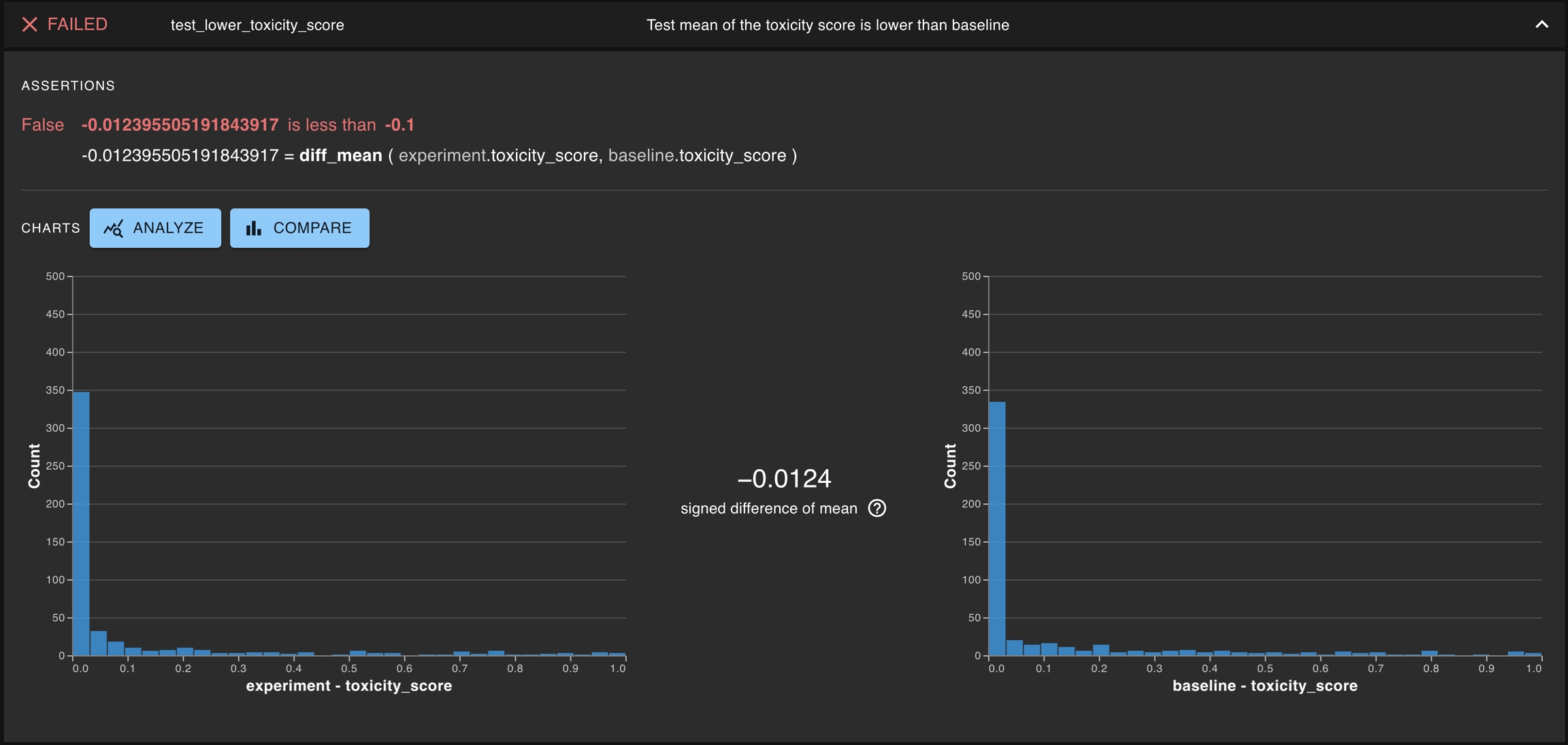
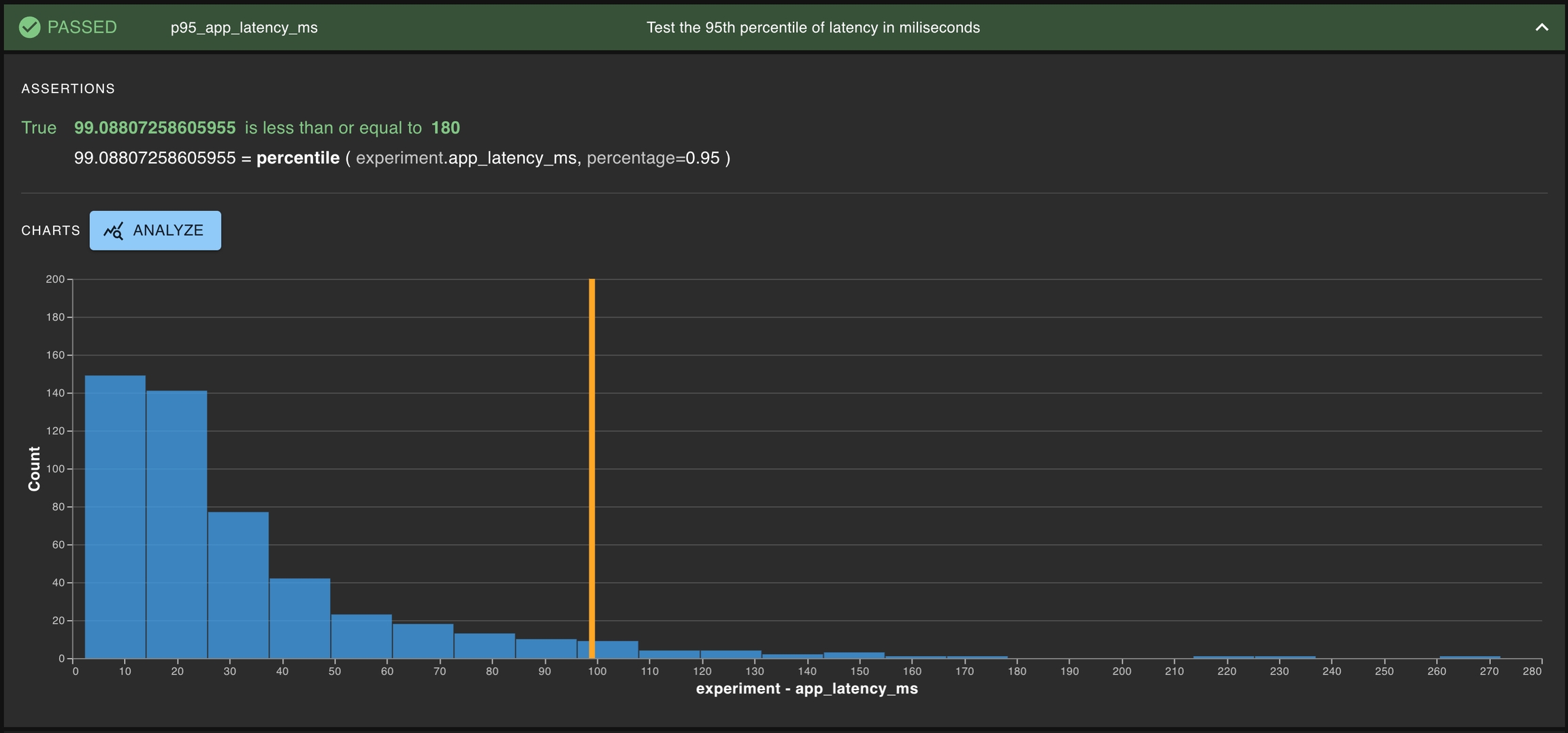
A common type of test is testing whether a single distribution contains some property of interest. Generally, this means determining whether some statistics for the distribution of interest exceeds some threshold. Some examples of this can be testing the toxicity of a given LLM or the latency for the entire AI-powered application.
This is especially common for development testing, where it is important to test if a proposed app reaches the minimum threshold for what is acceptable.
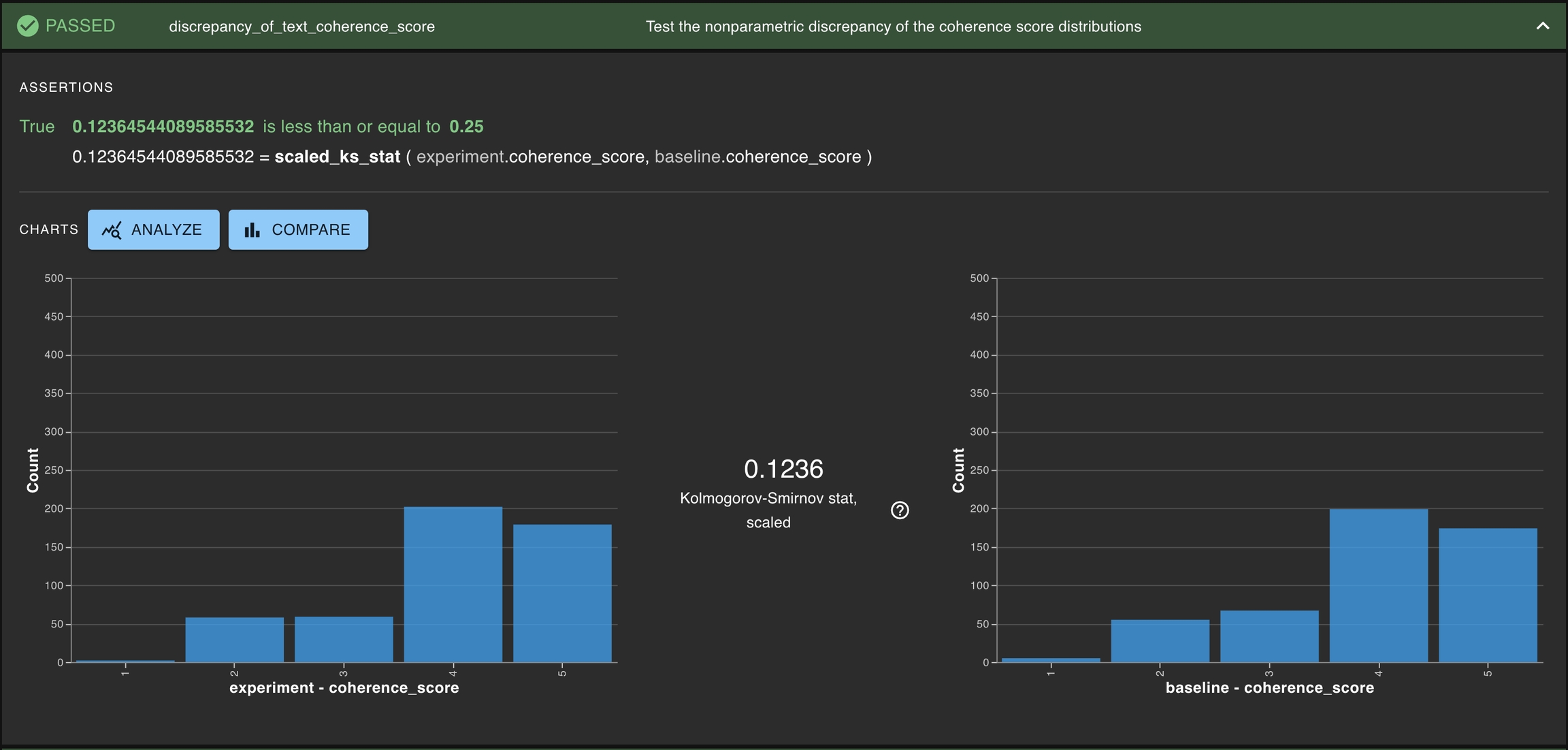
One general approach to test if two columns are similarly distributed is using a nonparametric statistic. DBNL offers two such statistics: scaled_ks_stat for testing ordinal distributions and scaled_chi2_stat for testing nominal distributions.
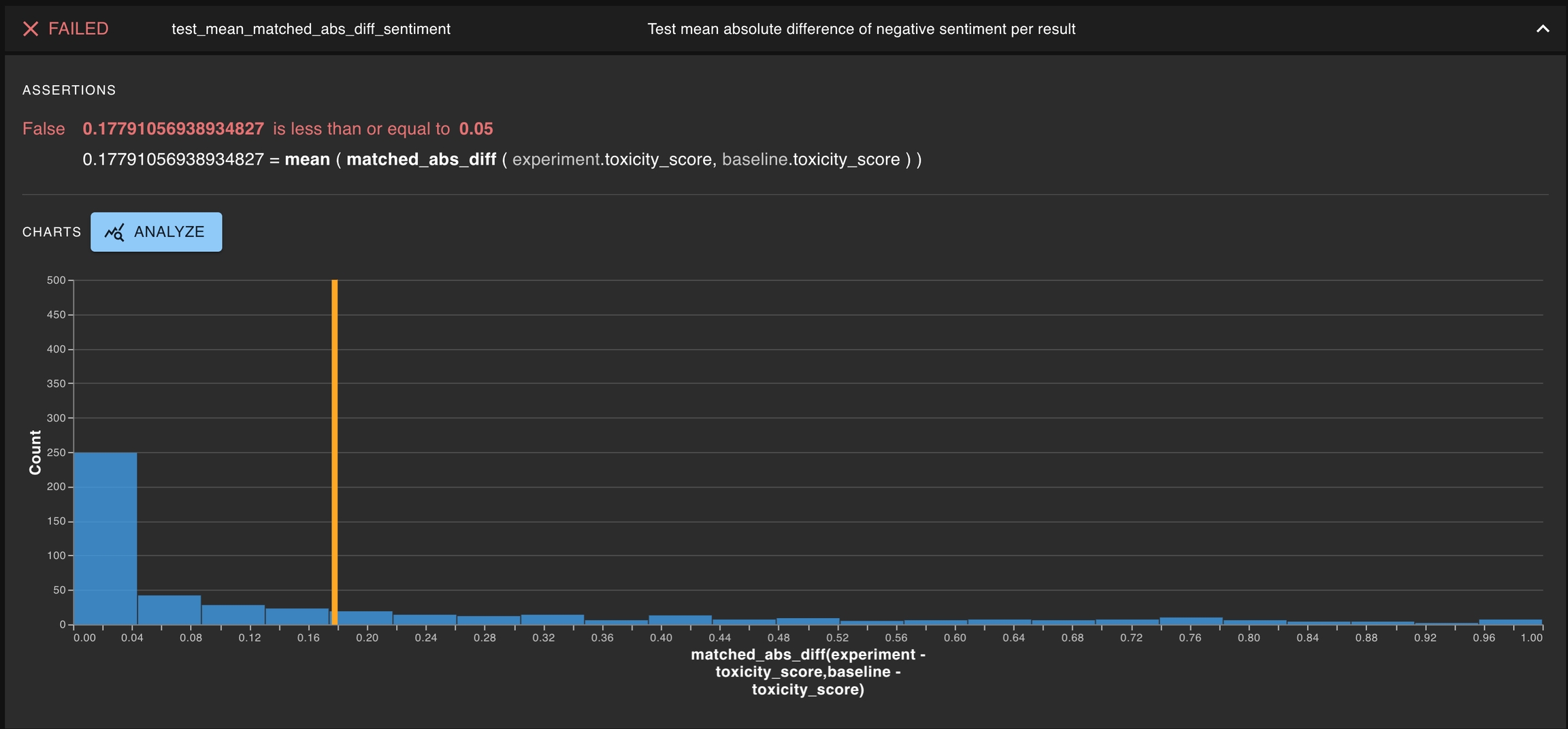
When the results from a run have unique identifiers, one can create a special type of tests for testing matching behavior at a per-result level. One example would be testing the mean of per-result absolute difference does not exceed a threshold value.
Another testing case is testing whether two distributions are not the same. Such a test involves the same statistics as a test of consistency, but a different assertion. One example could be to change the assertion from close_to to greater_than and thereby state that a passed test requires a difference bigger than some threshold.