The objects needed to define a Run, the core data structure in DBNL
The core object for recording and studying an app’s behavior is the run, which contains:
a table where each row holds the outcomes from a single app usage,
structural information about the components of the app and how they relate, and
user-defined metadata for remembering the context of a run.
Runs live within a selected project, which serves as an organizing tool for the runs created for a single app.
The structure of a run is defined by its Run Configuration, or RunConfig. This informs dbnl about what information will be stored in each result (the columns) and how the app is organized (the components). A Component is a mechanism for grouping columns based on their role within the app; this information is stored in the run configuration.
Using the row_id functionality within the run configuration, you also have the ability to designate Unique Identifiers – specific columns which uniquely identify matching results between runs. Adding this information enables specific tests of individual result behavior.
The data associated with each run is passed to dbnl through the SDK as a pandas dataframe.
As Distributional continues to evolve, we have made it our mission to meet customers where they, and their data, live. As such, we are building out integrations to pull in data from common cloud storage systems including, but not limited to, Snowflake and Databricks. Please contact your dedicated engineer to discuss the status of our integrations and implementing them in your system.
The Scalars feature allows for the upload, storage and retrieval of individual datums, ie. scalars, for every Run. This is contrary to the Columns feature, which allows for the upload of tabular data via Results.
Your production testing workflow involves the upload of results to Distributional in the form of model inputs, outputs, and expected outcomes for a machine learning model. Using these results you can calculate aggregate metrics, for example F1 score. The Scalars feature allows you to upload the aggregate F1 score that was calculated for the entire set of results.
Uploading Scalars is similar to uploading Results. First you must define the set of Scalars to upload in your RunConfig, for example:
Next, create a run and upload results:
Note: dbnl.report_scalars accepts both a dictionary and a single-row Pandas DataFrame for the data argument.
Finally you must close the run.
Navigate to the Distributional app in your browser to view the uploaded Run with Scalars.
Tests can be defined on Scalars in the same way that tests are defined on Columns. For example, say that you would like to ensure some minimum acceptable performance criteria like "the F1 score must always be greater than 0.8". This test can be defined in the Distributional platform as follows:
assert scalar({EXPERIMENT}.f1_score) > 0.8
You can also test against a baseline Run. For example, we can write the test "the F1 score must always be greater than or equal to the baseline Run's F1 score" in Distributional as:
assert scalar({EXPERIMENT}.f1_score - {BASELINE}.f1_score) >= 0
You can view all of the Scalars that were uploaded to a Run by visiting the Run details page in the Distributional app. The Scalars will be visible in a table near the bottom of that page.
Scalars can also be downloaded using the Distributional SDK.
Scalars downloaded via the SDK are single-row Pandas DataFrames.
The Distributional expression language supports Scalars, as shown in the above examples. Scalars are identical to Columns in the expression language. When you define an expression that combines Columns and Scalars, the Scalars are broadcast to each row. Consider a Run with the following data:
When the expression {RUN}.column_data + {RUN}.scalar_data is applied to this Run, the result will be calculated as follows:
column_data
scalar_data
column_data + scalar-data
1
10
11
2
10
12
3
10
13
4
10
14
5
10
15
Scalar broadcasting can be used to implement tests and filters that operate on both Columns and Scalars.
Tests are defined in Distributional as an assertion on a single value. The single value for the assertion comes from a Statistic.
Distributional has a special "scalar" Statistic for defining tests on Scalars. This is demonstrated in the above examples. The "scalar" statistic should only be used with a single expression input, where the result of that singular expression is a single value. The "scalar" Statistic will fail if the provided input resolves to multiple values.
Any other Statistic will reduce the input collections to a single value. In this case Distributional will treat a Scalar as a collection with a single value when computing the Statistic. For example, computing max({RUN}.my_statistic) is equivalent to scalar({RUN}.my_statistic), because the maximum of a single value is the value itself.
An overview of data access controls.
Data for a run is split between the object store (e.g. S3, GCS) and the database.
Metadata (e.g. name, schema) and aggregate data (e.g. summary statistics, histograms) are stored in the database.
Raw data is stored in the object store.
All data accesses are mediated by the API ensuring the enforcement of access controls. For more details on permissions, see Users and Permissions.
Database access is always done through the API with the API enforcing access controls to ensure users only access data for which they have permission.
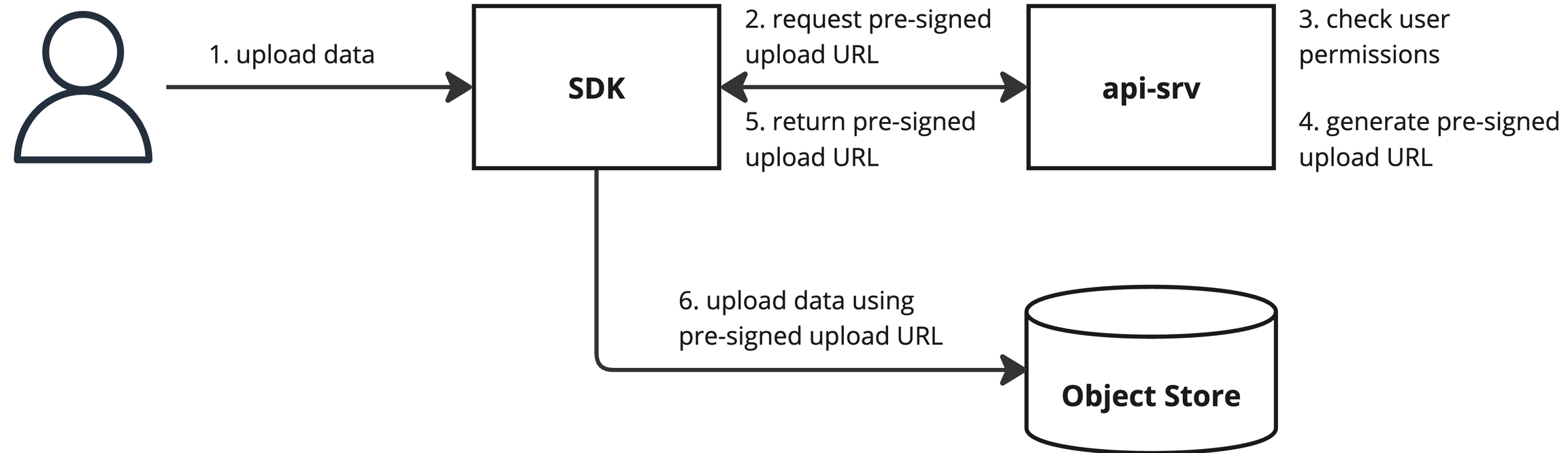
Direct object store access is required to upload or download raw run data using the SDK. Pre-signed URLs are used to provide limited direct access. This access is limited in both time and scope, ensuring only data for a specific run is accessible and that it is only accessible for a limited time.
When uploading or downloading data for a run, the SDK first sends a request for a pre-signed upload or download URL to the API. The API enforces access controls, returning an error if the user is missing the necessary permissions. Otherwise, it returns a pre-signed URL which the SDK then uses to upload or download the data.
Uploading data to a run in a given namespace requires write permission to runs in that namespace. Downloading data from a run in a given namespace requires read permission to runs in that namespace.


DBNL provides a software development kit in Python to organize this data, submit it to our system, and interact with our API. In this section we introduce key objects in the dbnl framework and describe using this SDK to interact with these objects.