Distributional runs on data, but our goal is to enable you to operate on data you already have available. If you are using a golden dataset to guide your development, we want you to use that to power your Development and Deployment testing. If you have actual Question-Answer pairs from production that are sitting in your data warehouse, we recommend that you to execute Production testing on that data to continually assert that your app is not misbehaving.
Generally, data is organized on Distributional in the form of a parquet file full of app usages, e.g., the prompts and summaries observed in the last 24 hours. This data is then packaged up and shipped to Distributional’s API, primarily through our . This could include any contextual information that can help determine if the app is behaving as desired, such as the day of the week.
Prior to shipping the data to dbnl, the library can be used to augment your data (especially text data) with additional columns for a more complete testing experience.
Distributional runs on data, but we know that your data is incredibly valuable and sensitive. This is why Distributional is built to be deployed in your private cloud. We have AWS and GCP installations today and are working towards an Azure installation. There is also a SaaS version available for demonstrations or proofs of concept.
Data goes in, insights come out
Distributional runs on data, so we make it easy for you to:
Push data into Distributional
Augment your unstructured data, such as text, to facilitate testing
Organize your data to enable more insightful testing
Review data that has been sent to Distributional
Your data + dbnl testing == insights about your app's behavior
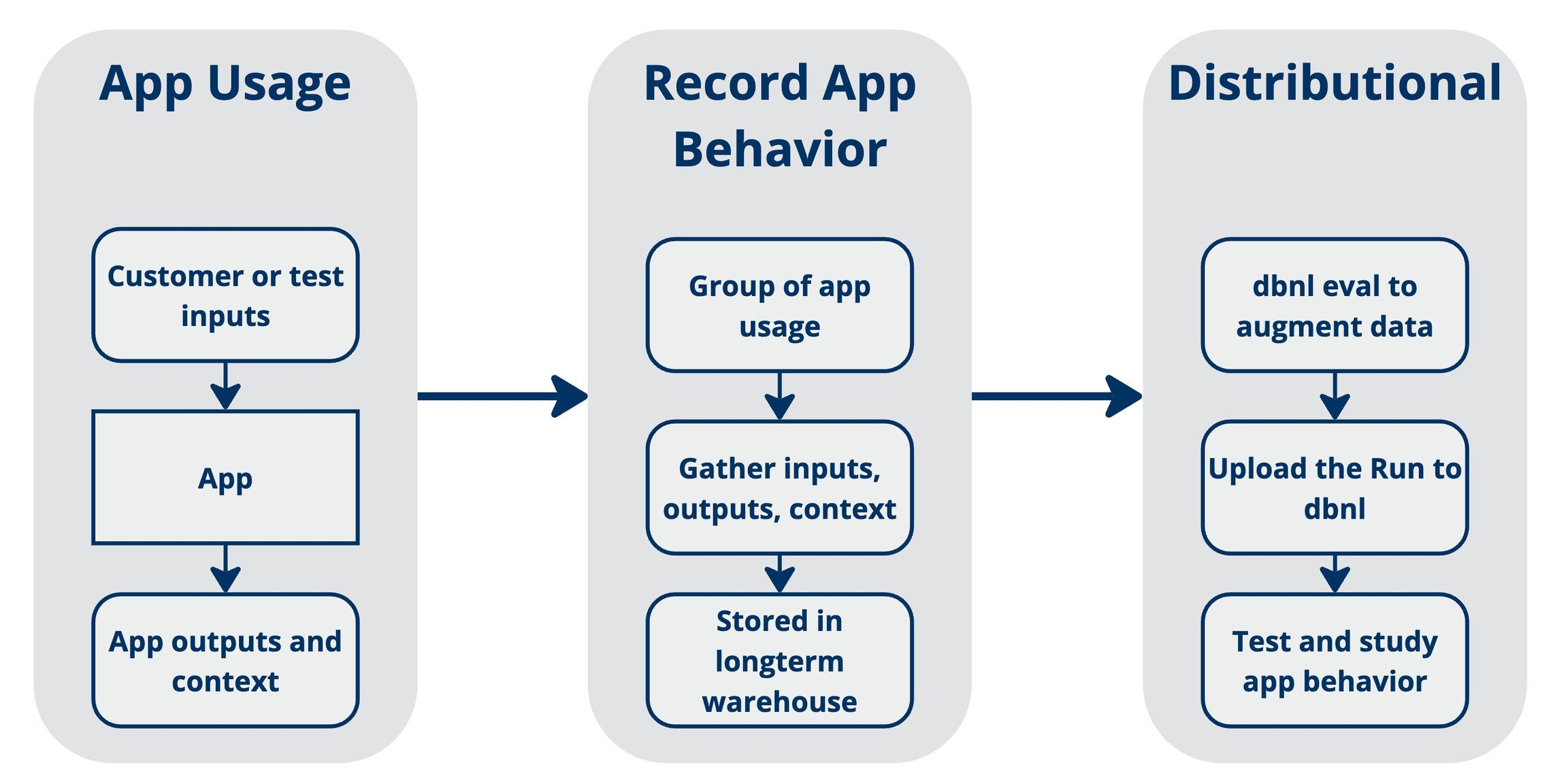
Distributional uses data generated by your AI-powered app to study its behavior and alert you to valuable insights or worrisome trends. The diagram below gives a quick summary of this process:
Each app usage involves input(s), the resulting output(s), and context about that usage
Example: Input is a question about the city of Toronto; Output is your app’s answer to that question; Context is the time/day that the question was asked.
As the app is used, you record and store the usage in a data warehouse for later review
Example: At 2am every morning, an airflow job parses all of the previous day’s app usages and sends that info to a data warehouse.
When data is moved to your data warehouse, it is also submitted to dbnl for testing.
Example: The 2am airflow job is amended to include data augmentation by dbnl Eval and uploading of the resulting dbnl Run to trigger automatic app testing.
A dbnl Run usually contains many (e.g., dozens or hundreds) rows of inputs + outputs + context, where each row was generated by an app usage. Our insights are statistically derived from the distributions estimated by these rows.
Distributional runs on data. When that data is well organized, Distributional can provide more powerful insights into your app’s behavior. One key way to do so is through defining components of your app and the organization of those components within your app.
Components are groupings of columns – they provide a mechanism for identifying certain columns as being generated at the same time or otherwise relating to each other. As part of your data submission, you can define that grouping as well as a flow of data from one component to another. This is referred to as the DAG, the directed acyclic graph.
In the example above, we see:
Data being input at TweetSource (1 column),
An EntityExtractor (2 columns) and a SentimentClassifier (4 columns) parsing that data, and
A TradeRecommender (2 columns) taking the Entities and Sentiments and choosing to execute a stock trade.
Tests were created to confirm the satisfactory behavior of the app. We can see that the TradeRecommender seems to be misbehaving, but so is the SentimentClassifier. Because the SentimentClassifier appears earlier in the DAG, we start our triage of these failed tests there.
You can read more about the dbnl specific terms . Simply stated, a dbnl Run contains all of the data which dbnl will use to test the behavior of your app – insights about your app’s behavior will be derived from this data.
is our library that provides access to common, well-tested GenAI evaluation strategies. You can use dbnl Eval to augment data in your app, such as the inputs and outputs. Doing so produces a broader range of tests that can be run, and it allows dbnl to produce more powerful insights.
To see more of this example, visit .