Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Functions that interact with a dbnl
Click through to view all the SDK functions.
Authenticate dbnl SDK
Setup dbnl SDK to make authenticated requests. After login is run successfully, the dbnl client will be able to issue secure and authenticated requests against hosted endpoints of the dbnl service.
dbnl.login must be run before any other functions in the DBNL workflow
api_token
namespace_id
Namespace ID to use for the session; available namespaces can be found with get_my_namespaces().
api_url
The base url of the Distributional API. For SaaS users, set this variable to api.dbnl.com. For other users, please contact your sys admin.
app_url
An optional base url of the Distributional app. If this variable is not set, the app url is inferred from the DBNL_API_URL variable. For on-prem users, please contact your sys admin if you cannot reach the Distributional UI.
The API token used to authenticate your DBNL account. You can generate your API token at (also, see ). If none is provided, theDBNL_API_TOKEN will be used by default.
name
The name for the dbnl Project. Project names must be unique; an error will be raised if there exists a Project with the same name.
description
An optional description for the dbnl Project, defaults to None. Description is limited to 255 characters.
The newly created dbnl Project.
The to copy.
The name for the new dbnl . Project names must be unique; an error will be raised if there exists a Project with the same name.
The to export as json.
Retrieve the specified dbnl Project or create a new one if it does not exist
name
description
An optional description for the dbnl Project, defaults to None. Description is limited to 255 characters.
Description cannot be updated with this function.
A new Project will be created with the specified name if there does not exist a Project with this name already. If there does exist a project with the name, the pre-existing Project will be returned.
Functions related to dbnl
The name for the existing dbnl . An error will be raised if there is no Project with the given name.
The name for the dbnl . A new Project will be created with this name if there does not exist a Project with this name already. If there does exist a project with this name, the pre-existing Project will be returned.
params
JSON object representing the Project, generally based on a Project exported via export_project_as_json. Example:
The newly created dbnl Project.
The this RunConfig is associated with.
The the most recent Run is associated with.
run_config_id
The ID of the dbnl RunConfig. RunConfig ID starts with the prefix runcfg_ . Run ID can be found at the Run detail page or Project detail page. An error will be raised if there does not exist a RunConfig with the given run_config_id.
The dbnl RunConfig with the given ID.
Functions related to Column and Scalar data uploaded within a Run.
As a convenience for reporting results and creating a Run, you can also check out report_run_with_results
Retrieve results from dbnl
run
pandas.DataFrame
You can only call get_column_results after the run is closed.
Retrieve results from dbnl
run
pandas.DataFrame
You can only call get_scalar_results after the run is closed.
Report all scalar results to dbnl
The dbnl from which to retrieve the results.
A of the data for the particular Run.
The dbnl from which to retrieve the results.
A of the uploaded for the particular Run.
run
The dbnl Run that the results will be reported to.
data
A dict or a single-row pandas DataFrame with all the scalar values to report to dbnl.
Retrieve results from dbnl
run
ResultData
You can only call get_results after the run is closed.
The dbnl from which to retrieve the results.
A named tuple that comprises of columns and scalars fields. These are the s of the data for the particular Run.
Functions interacting with dbnl Run
Report all column results to dbnl
run
data
All data should be reported to dbnl at once. Calling dbnl.report_column_results more than once will overwrite the previously uploaded data.
Once a Run is closed. You can no longer call report_column_results to send data to dbnl.
The dbnl that the results will be reported to.
A with all the results to report to dbnl. The columns of the DataFrame must match the columns described in the associated with the Run.
run
The dbnl Run to be finalized.
Create a new Run, report results to it, and close it.
project
column_data
scalar_data
display_name
An optional display name for the Run. Display names do not have to be unique.
row_id
An optional list of the column names that can be used as unique identifiers.
run_config_id
ID of the RunConfig to use for the Run, defaults to None. If provided, the RunConfig is used as is and the results are validated against it. If not provided, a new Run Config is inferred from the column_data.
metadata
Any additional key-value pairs information the user wants to track.
The closed Run with the uploaded data.
The ID of the dbnl . Run ID starts with the prefix run_ . Run ID can be found at the Run detail page. An error will be raised if there does not exist a Run with the given run_id.
The dbnl that this Run will be associated with.
A with all the column results to report to dbnl. If run_config_id is provided, the columns of the DataFrame must match the columns described in the .
A dict or pandas DataFrame with all the scalar results to report to dbnl. If run_config_id is provided, the key of the dict must match the scalars described in the .
Functions that interact with dbnl Baseline concept
Report all results to dbnl
run
column_data
scalar_data
report_results is the equivalent of calling both report_column_results and report_scalar_results .
All data should be reported to dbnl at once. Calling dbnl.report_results more than once will overwrite the previously uploaded data.
Once a Run is closed. You can no longer call report_results to send data to DBNL.
Functions that interact with dbnl
Create a new dbnl RunConfig
Column names can only be alphanumeric characters and underscores.
The following type supported as type in column schema
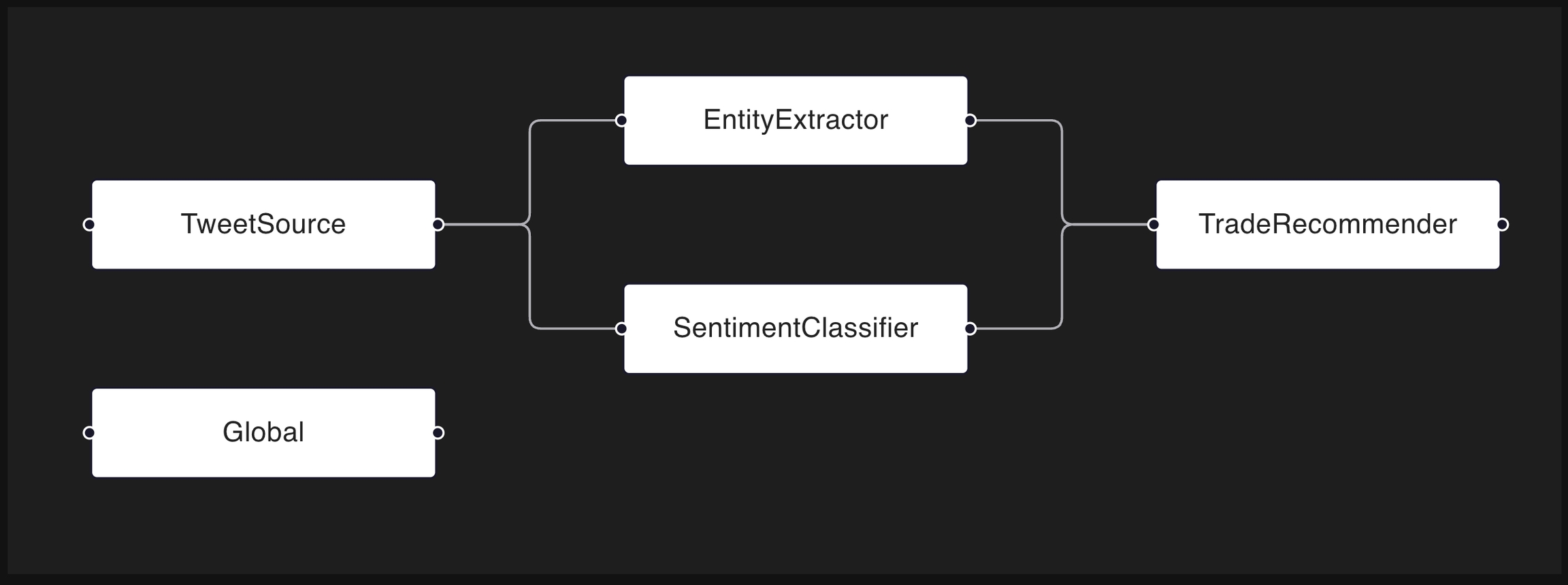
The components_dag dictionary specifies the topological layout of the AI/ML app. For each key-value pair, the key represents the source component, and the value is a list of the leaf components. The following code snippet describes the DAG shown above.
RunConfig with scalars
The dbnl that this Run will be associated with.
The dbnl that this Run will be associated with. Two Runs with the same RunConfig can be compared in the web UI and associated in Tests. The associated RunConfig must be from the same Project.
A new dbnl for .
The DBNL that the results will be reported to.
A with all the column results to report to DBNL. The columns of the DataFrame must match the columns described in the associated with the Run.
A dict or pandas Dataframe with all the scalar results to report to DBNL. The key of the dict must match the scalars described in the associated with the Run.
The dbnl this will be associated with
A new dbnl RunQuery, typically used for finding a for a Test Session
The optional component key is for specifying the source of the data column in relationship to the AI/ML app subcomponents. Components are used in visualizing the .
run
The dbnl Run to be set as the Baseline Run in its Project Test Config.
run_query
The dbnl RunQuery to be set as the Baseline Run in its Project Test Config.
project
The Project this RunConfig is associated with.
columns
A list of column schema specs for the uploaded data, required keys name and type, optional key component, description and greater_is_better. type can be int, float, category, boolean, or string. component is a string that indicates the source of the data. e.g. "component" : "sentiment-classifier" or "component" : "fraud-predictor". Specified components must be present in the components_dag dictionary. greater_is_better is a boolean that indicates if larger values are better than smaller ones. False indicates smaller values are better. None indicates no preference.
Example:
columns=[{"name": "pred_proba", "type": "float", "component": "fraud-predictor"}, {"name": "decision", "type": "boolean", "component": "threshold-decision"}, {"name": "requests", "type": "string", "description": "curl request response msg"}]
See the column schema section below for more information.
scalars
NOTE: scalars is available in SDK v0.0.15 and above.
A list of scalar schema specs for the uploaded data, required keys name and type, optional key component, description and greater_is_better. type can be int, float, category, boolean, or string. component is a string that indicates the source of the data. e.g. "component" : "sentiment-classifier" or "component" : "fraud-predictor". Specified components must be present in the components_dag dictionary. greater_is_better is a boolean that indicates if larger values are better than smaller ones. False indicates smaller values are better. None indicates no preference. An example RunConfig scalars: scalars=[{"name": "accuracy", "type": "float", "component": "fraud-predictor"}, {"name": "error_type", "type": "category"}]
Scalar schema is identical to column schema.
description
An optional description of the RunConfig, defaults to None. Descriptions are limited to 255 characters.
display_name
An optional display name of the RunConfig, defaults to None. Display names do not have to be unique.
row_id
An optional list of the column names that can be used as unique identifiers, defaults to None.
components_dag
An optional dictionary representing the direct acyclic graph (DAG) of the specified components, defaults to None. Every component listed in the columns schema must be present in the components_dag. Example: components_dag={"fraud-predictor": ["threshold-decision"], 'threshold-decision': []}
See the components DAG section below for more information.
float
int
boolean
string
Any arbitrary string values. Raw string type columns do not produce any histogram or scatterplot on the web UI.
category
Equivalent of pandas categorical data type. Currently only supports category of string values.
list
Currently only supports list of string values. List type columns do not produce any histogram or scatterplot on the web UI.
A new dbnl RunConfig
Create a TestSession
Start evaluating Tests associated with a Run. Typically, the Run you just completed will be the "Experiment" and you'll compare it to some earlier "Baseline Run".
The Run must already have and be closed before a Test Session can begin.
A Run must be closed for all to be shown on the UI.
Suppose we have the following Tests with the associated Tags in our Project
Test1 with tags ["A", "B"]
Test2 with tags ["A"]
Test3 with tags ["B"]
dbnl.create_test_session(..., include_tags=["A", "B"]) will trigger Tests 1, 2, 3 to be executed.
dbnl.create_test_session(..., require_tags=["A", "B"]) will only trigger Test 1.
dbnl.create_test_session(..., exclude_tags=["A"]) will trigger Test 3.
dbnl.create_test_session(..., include_tags=["A"], exclude_tags=["B"]) will trigger Test 2.
experiment_run
baseline
include_tags
An optional list of Test Tags to be included. All Tests with any of the tags in this list will be ran after the run is complete.
exclude_tags
An optional list of Test Tags to be excluded. All Tests with any of the tags in this list will be skipped after the run is complete.
require_tags
An optional list of Test Tags that are required. Only tests with all the tags in this list will be ran after the run is complete.
The dbnl to create the TestSession for.
The dbnl or to compare the experiment_runagainst. If None(or omitted), will use the baselinedefined in the TestConfig